_a.png)
AI框架「TensorFlow」被廣泛用於工業領域的AI應用,但AI框架「PyTorch」在研究和學術領域非常受歡迎,因為它易於原型設計。 因此,有許多用例,例如將 x86-64 環境中的 PyTorch 上定義的 AI 模型移植和運行到邊緣設備等嵌入式環境中。在本文中,我們將討論將 x86-64 環境中的 PyTorch 上定義的 AI 模型移植到基於嵌入式環境 NVIDIA Jetson Orin NX 的產品威盛 AMOS-9100 和基於MediaTek Genio 700 的產品威盛 VAB-5000 的過程。 我們將解釋可以透過此過程建立的人工智慧應用程式的推理速度。 此外,本文的評估使用了“FCN-resnet50”,這是一種計算量比較大的AI模型。 FCN-resnet50 是一種 AI 模型,提供分割功能來選擇圖像中包含特定對象的像素。 我們希望本文能幫助您了解將 x86-64 環境中的 PyTorch 上定義的 AI 模型移植到威盛的邊緣 AI 產品的步驟,以及整合到這些硬體中的 GPU 和 APU 等加速器對推理速度的影響。
PyTorch 和 TensorFlow 市場占比
下圖顯示了每個框架的採用率圖表,顯示了哪些框架用於在工業領域實施機器學習驅動的應用程式(資料來源:2021 年資料科學和機器學習狀況)。 最受歡迎的「Scikit-learn」函式庫提供了與機器學習相關的原始函數,這表明「TensorFlow」及其子集「Keras」是非常流行的深度學習(AI)框架。 選擇 TensorFlow 是因為它易於部署,而不是因為它的學習曲線平緩。 透過採用TensorFlow作為開發AI應用程式的框架,可以在部署過程中優化記憶體使用和計算圖,因此存在部署大規模AI模型的案例和在運算資源有限的環境中部署AI模型的案例。使用案例。 此外,與TensorFlow形成對比的AI框架PyTorch的採用率在工業領域排名第五。
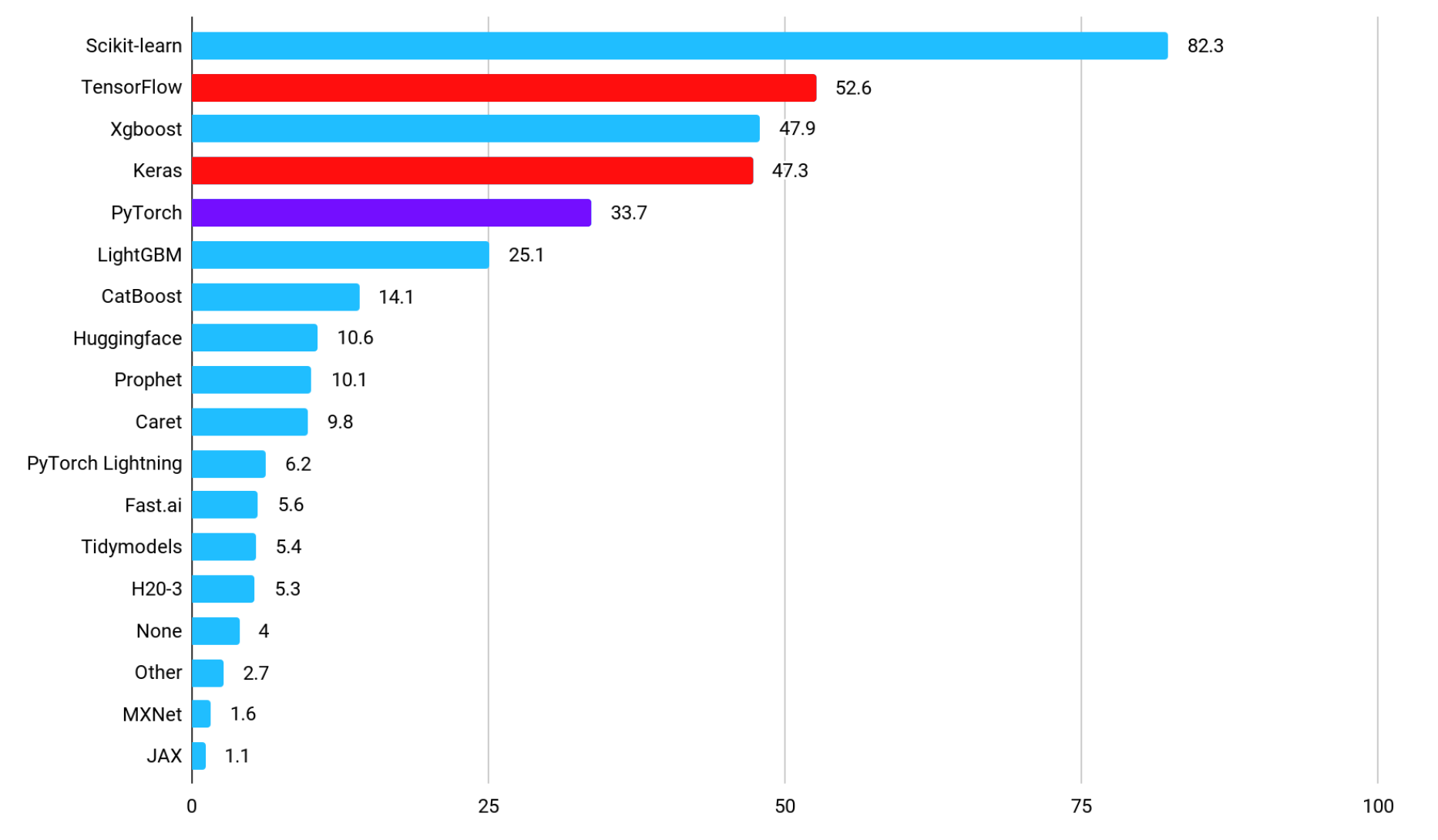
Kaggle 上的 TensorFlow 和 PyTorch
PyTorch 在研究和學術領域非常受歡迎
另一方面,用於研究和學術界論文正式落地的面向AI的框架的滲透率如下圖所示,「PyTorch」的壓倒性受歡迎程度(來源:ML Engineer 對 Pytorch、TensorFlow、JAX 和 Flax 的比較)。 PyTorch之所以在研究和學術界得到廣泛應用,與PyTorch的三個特性有關。 第一個特點是PyTorch使用類似Python的動態計算圖,不僅編碼直觀,而且易於調試。 第二個特點是,動態計算圖的使用使得動態改變模型的結構變得容易,並且相對容易實現條件分支和循環,使得快速建立複雜模型和實現新演算法成為可能。 其流行的功能之一是 PyTorch 可以輕鬆與各種開源庫集成,包括 Hugging Face 和 PyTorch Lightning。 選擇 PyTorch 的第三個原因是,它使 AI 模型開發人員更容易與為研究目的而建立的社區和生態系統進行協作。 PyTorch 被研究深度學習的社群廣泛採用,例如 CVPR、NeurIPS 和 ICML,最新的研究論文廣泛使用 PyTorch 進行正式實施。 PyTorch 也用於 YOLOv12 的官方實現,這是一種在物件偵測方面擁有高性能的 AI 模型。

論文中的 TensorFlow 和 PyTorch
本文涵蓋的 AI 模型
在本文中,我們將解釋在 x86-64 環境中在 PyTorch 上定義的 AI 模型「FCN-resnet50」移植到威盛 AMOS-9100 或威盛 VAB-5000 時的推理速度。
用於細分的 AI 模型 – FCN-resnet50
FCN-resnet50 是一個執行圖像分割的 AI 模型,並輸出每個像素包含 21 種對象的可能性,用於輸入圖像中的每個像素。 FCN-resnet50 是一個 50 層全卷積網路(Fully Convolutional Networks:FCN),並且往往比由卷積層和輸出邊界框的完全耦合層組成的一般對象檢測 AI 模型具有更高的計算強度。 在本文中,我們將對影片的每一幀應用 FCN-resnet50,以識別影片中包含狗物件的像素。 我們將在 x86-64 環境、AMOS-9100 和 VAB-5000 上實現一個 AI 應用程式,該應用程式如下圖所示遮罩並顯示狗對象存在的像素,以比較它們的性能。

Application Output
本文推理效能的評估方法
本文實現的應用程式將從影片每一幀中剪切的 288px x 288px 的方形 RGB 格式影像輸入給 AI 模型「FCN-resnet50」,並獲得一個概率為 288px x 288px 的特徵圖,顯示每個像素包含哪些物體作為輸出。 參考存儲在特徵圖特定層中的“每個像素是構成狗的像素的可能性”,我們為具有一定值或更大可能性的像素創建一個掩碼。 即時顯示包含狗的區域如上圖所示。 在本文中,我們根據FPS(Frames Per Second)評估推理速度,FPS(每秒幀數)可以從將288px x 288px RGB格式的圖像輸入到AI模型並輸出特徵圖所需的時間計算出來,並考慮AMOS-9100和VAB-5000的最佳AI框架。 我們還測量了後處理的時間,從特徵圖生成遮罩輸出圖像作為參考值。 在本文中,我們將這些效能測量與在具有不同硬體平台、框架和加速器配置的 11 種不同環境中實作的應用程式進行比較,包括: 此外,我們還使用常見的 OpenCV 函數實現了從影片中剪出方形圖像的 PreProcess 過程,以及從特徵圖中生成遮罩圖像的 PostProcess 過程。
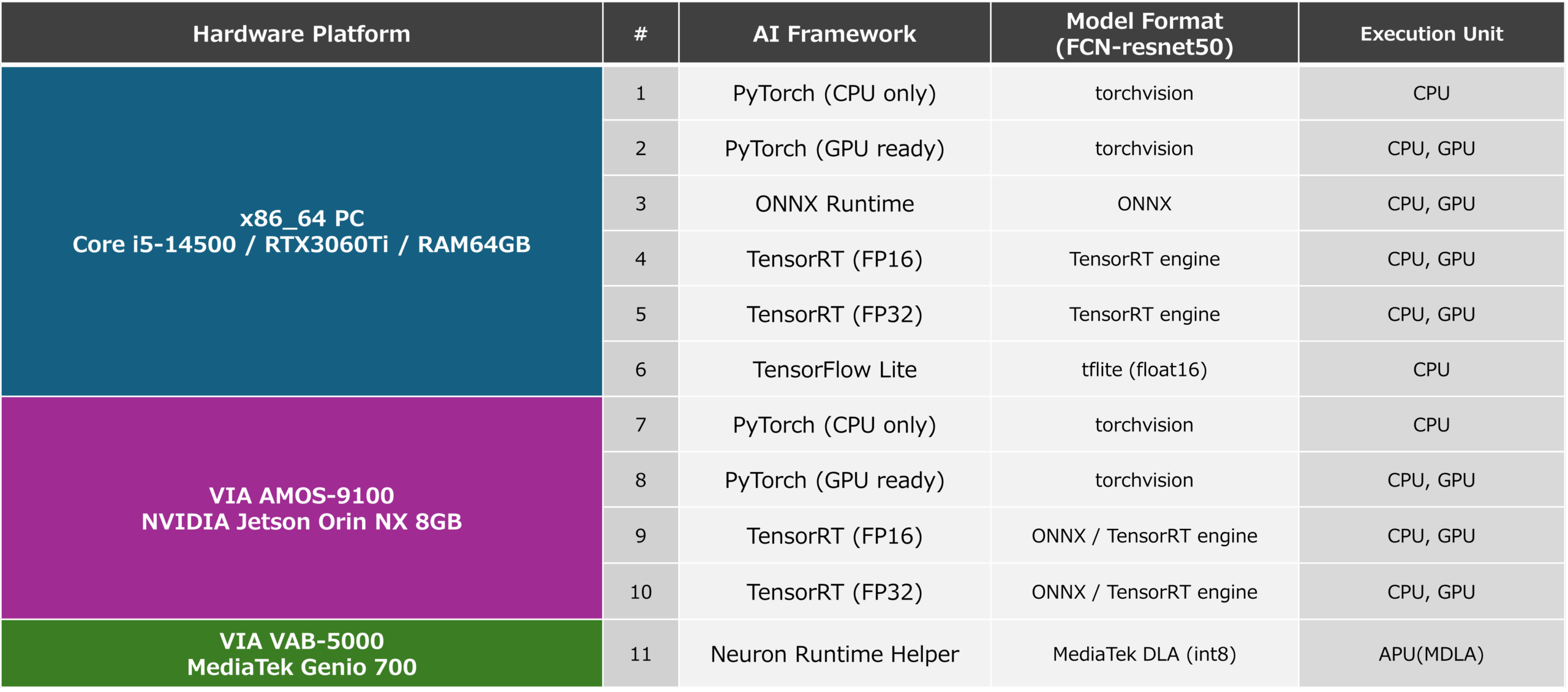
各項平台
機器學習中使用的關鍵框架及其功能
在本節中,我們將討論用於開發人工智慧的主要框架及其功能,然後再討論應用程式。
PyTorch 的特點
PyTorch 是一個 AI 框架,通過提供類似 Python 的 API 來鼓勵 AI 模型的直觀編碼。 PyTorch 使用一種名為「Define-by-Run」的方法來動態定義用於定義 AI 模型的計算圖,從而實現靈活的 AI 模型修改、複雜的 AI 模型建構以及輕鬆調試。 PyTorch 也適用於研究應用的 AI 模型原型設計和官方實現,允許用戶定義自訂層、定義原始損失函數並利用 AutoGrad 功能,這些功能對於訓練具有複雜網路結構的 AI 模型是有效的。 此外,PyTorch 還支援 CUDA,這是一個使用 GPU 作為硬體加速器的函式庫,允許使用 GPU 進行快速學習。 儘管 PyTorch 很少被移植到嵌入式環境中,但它可以透過以 ONNX 格式匯出經過訓練的 AI 模型來將模型分發到包括邊緣在內的各種環境,這將在後面描述。
ONNX 特點
ONNX 是一個增強互通性的框架,旨在實現不同 AI 框架(例如 PyTorch 和 TensorFlow)之間訓練有素的 AI 模型的高效交換。 借助 ONNX,在從雲端到邊緣的各種平台上運行的 AI 模型可以輕鬆整合到嵌入式應用程式中。 這使得部署使用 PyTorch 實現的在雲端擁有高性能的 AI 模型和剛剛開發和發布用於研究目的的最新 AI 模型作為使用 TensorFlow 和 TensorRT 等 AI 框架在邊緣針對硬件資源進行優化的 AI 模型成為可能。 快速開發先進但硬體最佳化的 AI 應用程式。 透過使用 ONNX Runtime,ONNX AI 模型不像 PyTorch 和 TensorFlow 那樣最佳化,但它們也可以嵌入到 ONNX 格式的應用程式中並用於原型設計。 本文也說明了 ONNX Runtime 的推理速度。
TensorFlow 的特點
TensorFlow 是一個理想的 AI 框架,用於部署運算密集型 AI 模型或部署到硬體資源有限的邊緣。 雖然與 PyTorch 相比,學習曲線有點陡峭,但一旦掌握了,您就可以利用 TensorFlow Serving 和 TensorFlow Lite 為各種平台優化和部署 AI 模型。 PyTorch 也提供了部署功能,但 TensorFlow 的部署功能在生產中擁有更好的記錄,並且使用更廣泛。 威盛 VAB-5000 基於聯發科 Genio 700,可利用聯發科技基於 TensorFlow Lite AI 模型的工具集,產生針對 APU 和 GPU 最佳化的 DLA 格式 AI 模型,讓您能夠建立高效利用硬體加速器的高速 AI 應用程式。 在使用 PyTorch 實現高級 AI 模型以提高推理準確性後,通過 ONNX 格式將其轉換為 TensorFlow Lite 格式的 AI 模型。 優化硬體資源、部署到生產環境、建立快速運行的應用程式等開發方法是開發高級系統的最佳解決方案。
TensorRT (AMOS-9100) 的特點
TensorRT 是 NVIDIA 專用的 AI 推理框架,可用於具有 NVIDIA GPU 的基於 NVIDIA Jetson Orin NX 的 AMOS-9100 環境,以及具有 NVIDIA GPU 的 x86-64 環境。 TensorRT 專注於 AI 中的推理階段,提供針對推理優化的庫和控制推理的 API。 TensorRT不僅提高了AI模型的推理速度,還透過積極利用FP16、INT8等低精度格式的變量,以及整合多層運算,降低了記憶體消耗。 請注意,TensorRT 的 AI 模型可以從 ONNX 格式的 AI 模型建立。 在本文中,我們將透過 ONNX 格式的 AI 模型,將 PyTorch 上定義的 AI 模型「FCN-resnet50」轉換為 TensorRT 的 AI 模型。 以下說明對 AMOS-9100 執行的步驟及其效能。
MediaTek NeuroPilot SDK / MDLA3.0 的特點 (VAB-5000)
MediaTek的 NeuroPilot SDK 是一個 AI 框架,可用於威盛 VAB-5000 等產品,該產品基於MediaTek Genio 700 等配備 APU (MDLA3.0) 的 SoC。 透過使用NeuroPilot SDK,您可以將TensorFlow格式的AI模型轉換為針對Genio硬體最佳化的DLA格式的AI模型,並使用整合到Genio中的GPU和APU等硬體加速器來實現高速推理。 在本文中,我們將透過 ONNX 格式和 TensorFlow Lite 格式,將 PyTorch 定義的 AI 模型「FCN-resnet50」轉換為 DLA 格式的 AI 模型。 我們將介紹如何使用威盛專有的「Neuron Runtime Helper」(一個執行框架)在威盛 VAB-5000 上高速運行 AI 模型及其效能。
針對 AMOS-9100 優化 PyTorch 的模型
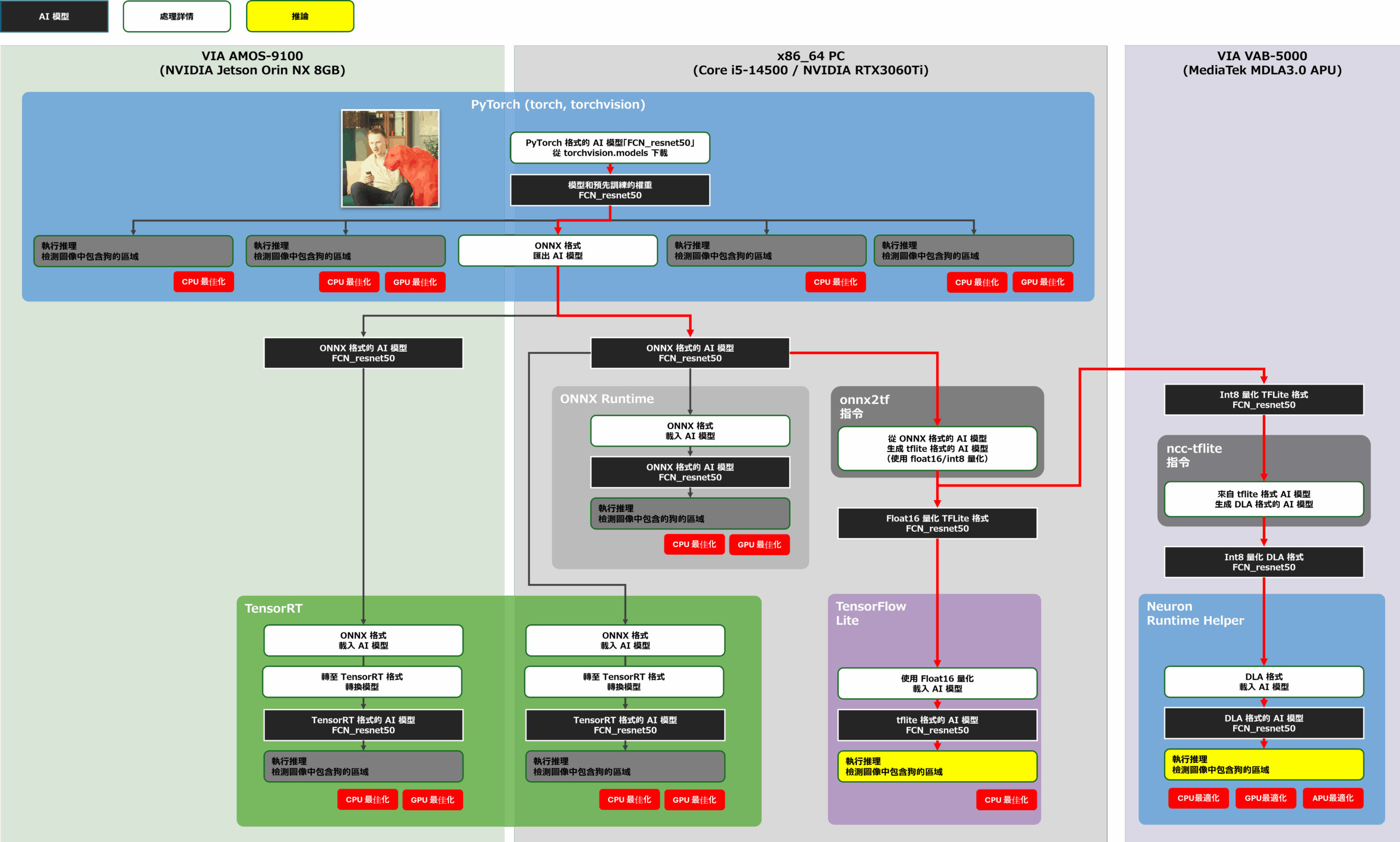
讓我們繼續開發將 PyTorch 上定義的訓練有素的 FCN-resnet50 移植到 AMOS-9100。 此開發的目標是測量下圖中黃框所示配置的性能。 首先,我們在 x86-64 環境下測量了 FCN-resnet50 在各個AI 框架中的推理速度,然後在 AMOS-9100 環境下測量了 AI 模型在 PyTorch 上的推理速度,以及專門從事 GPU 推理的 TensorRT 上的 AI 模型的推理速度。 要合併到待測應用程式中的 AI 模型是使用下圖中紅線的流程產生的。
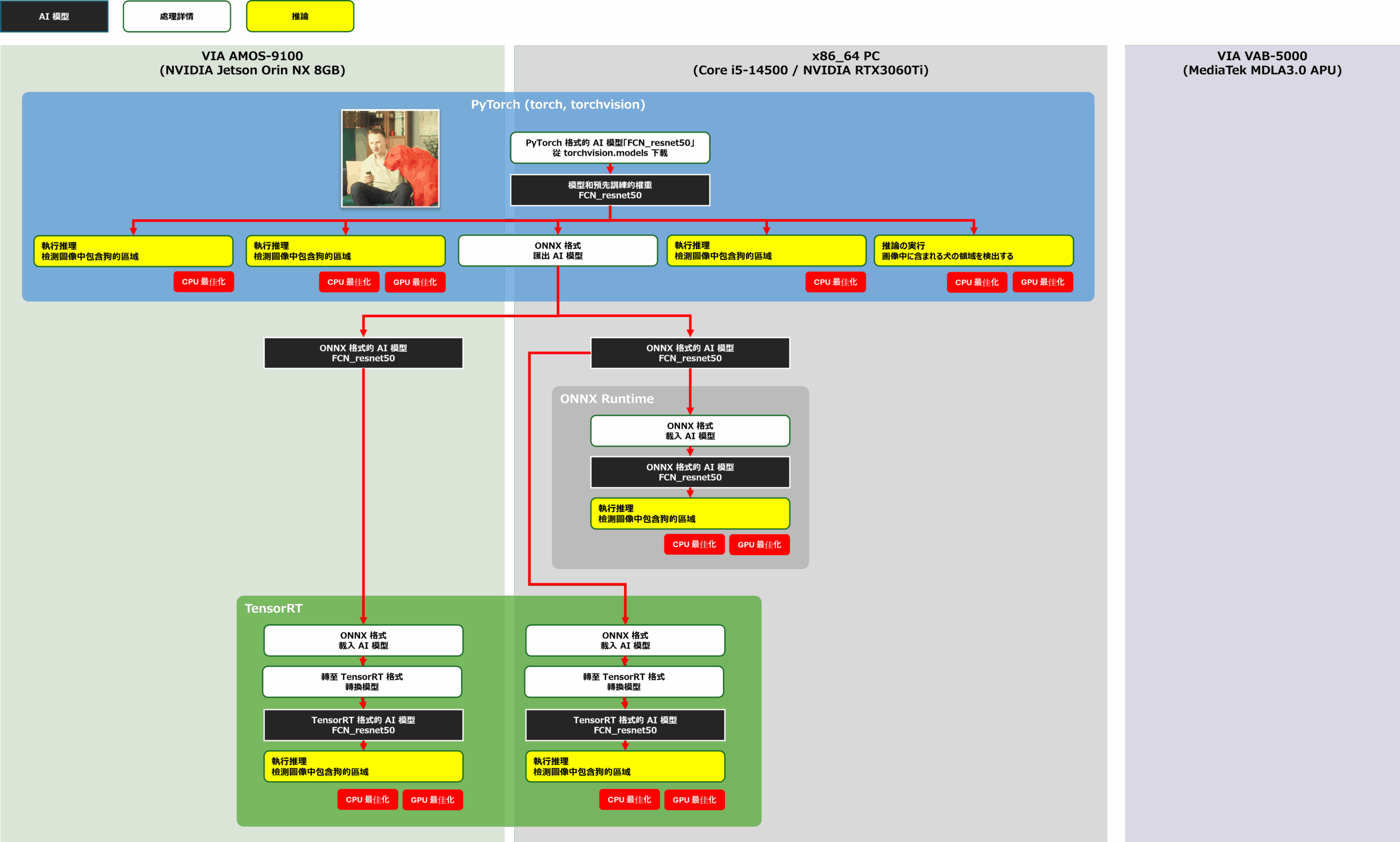
轉換並評估 PYTorch-TensorRT
在 x86-64 和 AMOS-9100 環境中定義 PyTorch 模型
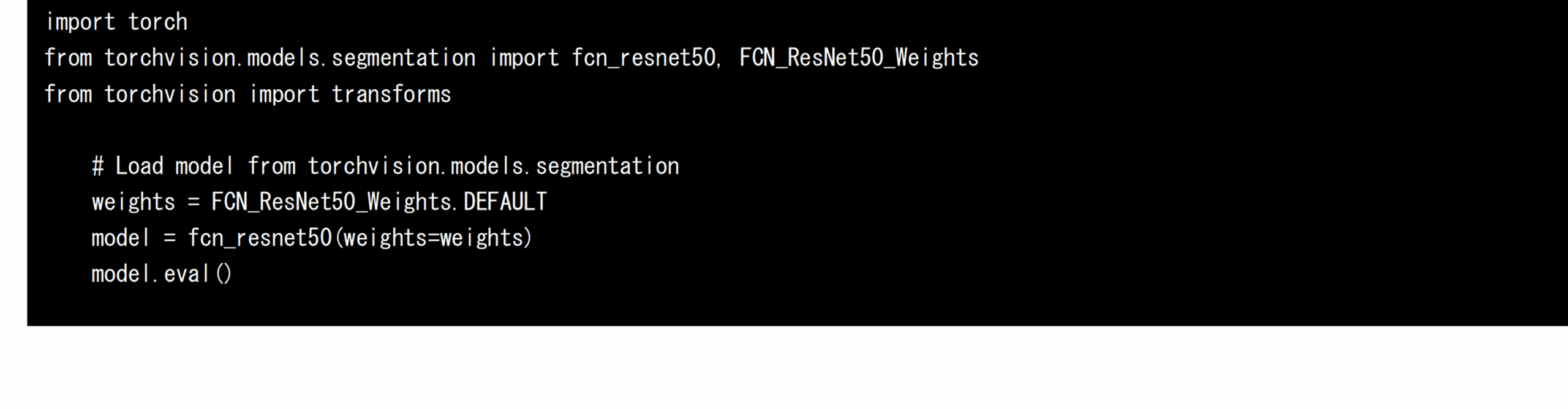
首先,在 x86-64 和 AMOS-9100 環境中使用 PyTorch 的 torchvision 套件載入經過訓練的 FCN-resnet50。 具有預訓練權重的 FCN-resnet50 分佈在 PyTorch 的擴展庫 torchvision 上,只需運行以下源代碼即可獲得 AI 模型:
PyTorch 使用以下原始碼將載入的 AI 模型和透過 PreProcess(見下文)產生的輸入張量傳輸到 GPU,用於高速推理。 如果未執行傳輸至 GPU,則會執行僅限 CPU 的推論程式。 推理前後的 CPU 時間用於計算每次推理的速度。

測量 PyTorch 效能時的注意事項
請注意,如果您想在 PyTorch 上使用 CPU 時間來測量 AI 模型的推理時間,則必須在呼叫推理過程後呼叫 torch.cuda.synchronize()。 這是因為 PyTorch 使用 GPU 的推理處理是非同步工作的。 透過呼叫 torch.cuda.synchronize(),可以保證推理過程是完整的,因此可以準確測量從推理開始到完成的時間。 如果在不呼叫torch.cuda.synchronize()的情況下測量效能,則在PostProcess 進程中從 CPU 存取特徵圖時,CPU和GPU 是第一次同步,因此部分推理時間在過程中它將記錄在處理時間內。
在 OpenCV 中定義後處理和前處理
在此應用程式中,我們使用 OpenCV 來定義從影片中剪切幀的 PreProcess 過程,以及從推理結果獲得的特徵圖中產生和顯示遮罩幀的 PostProcess 過程。 PreProcess和PostProcess的流程如下圖所示。

將張量轉換為影像
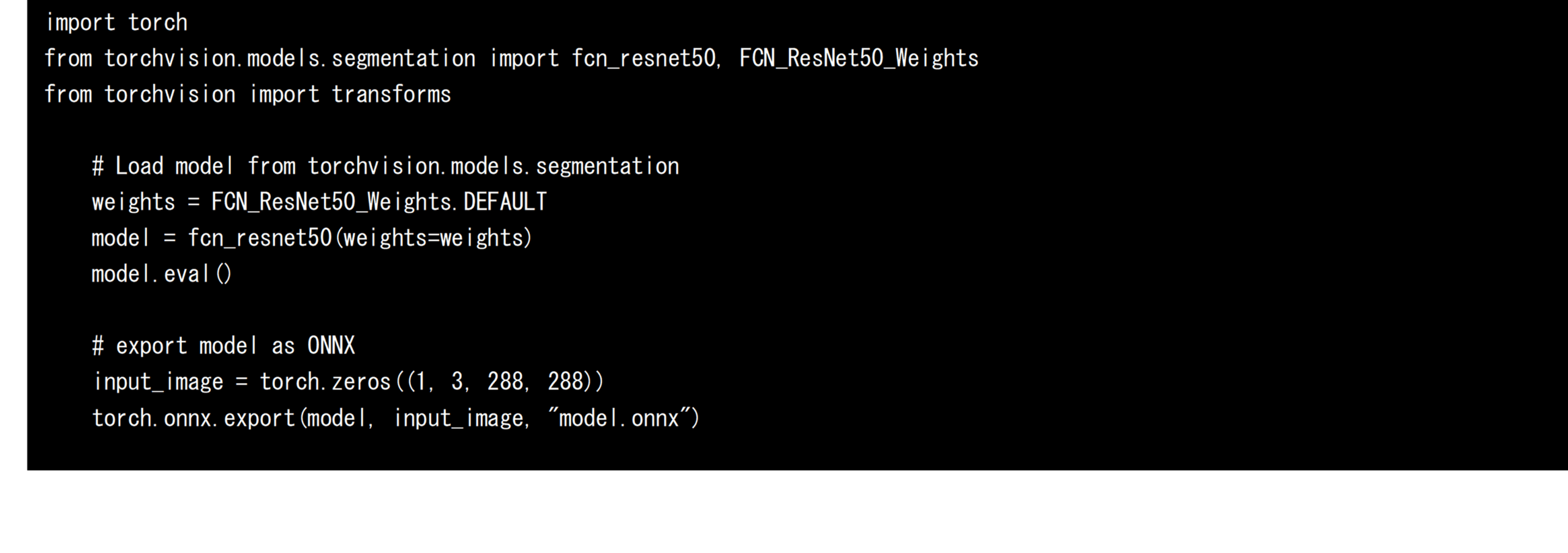
將 PyTorch 上的 AI 模型轉換為 ONNX 格式模型
接下來,將訓練好的 FCN-resnet50 從 PyTorch 的 torchvision 匯出為 ONNX 格式的 AI 模型。 由於匯出時需要固定輸入張量的大小,因此定義一個虛擬輸入張量並指定,如下圖所示。 在這項開發中,FCN-resnet50 的輸入張量形狀被固定為 288px x 288px,並匯出到 model.onnx 檔案中。 匯出的 ONNX 格式 AI 模型可以轉換為其他 AI 框架,也可以利用 ONNX Runtime 進行直接推理。 在此開發中,還測量和評估了使用 ONNX Runtime 時的推理速度。
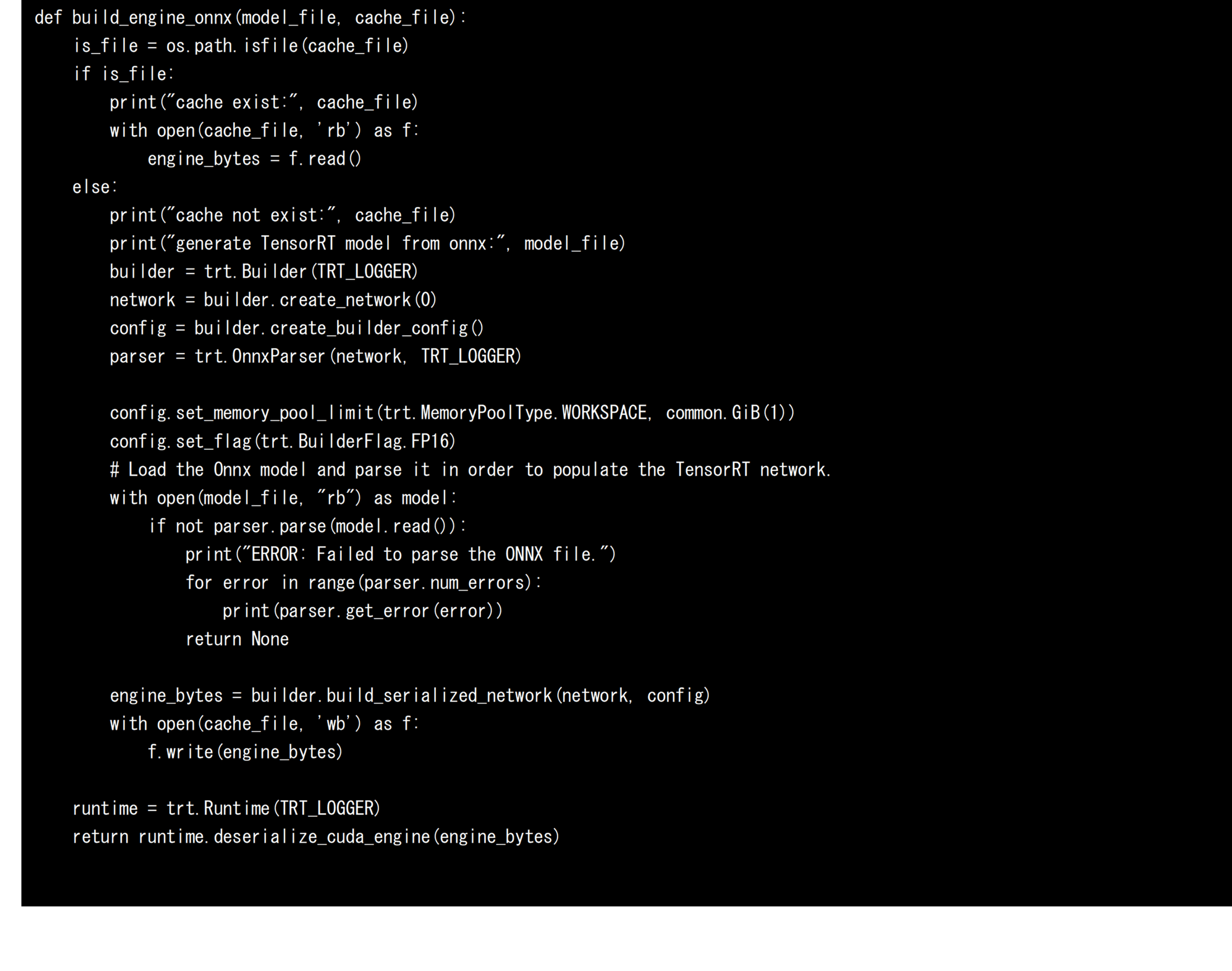
將 ONNX 格式的 AI 模型轉換為 TensorRT 的模型
接下來,我們將 ONNX 格式的 AI 模型轉換為 TensorRT 的 AI 模型,以便在 AMOS-9100 和 x86-64 環境中使用 NVIDIA GPU 高速運行 AI 模型。 將 AI 模型轉換為 TensorRT 時,會定義並使用四個元素:Builder、Network、Config 和 Parser。 解析器以 ONNX 格式分析 AI 模型,Network 定義計算圖。 Config 決定轉換選項,Builder 為 TensorRT 生成 AI 模型。 在這次開發中,為了將AI模型優化到FP16,我們新增了「trt. BuilderFlag.FP16“。 此指定允許為針對 FP16 最佳化的 TensorRT 產生 AI 模型,從而減少記憶體使用並有效利用運算單元。 如果您未指定此設定,AI 模型將針對 FP32 進行最佳化。 基於上述,將 ONNX 格式的 AI 模型轉換為 TensorRT 的 AI 模型的原始碼如下所示。 由於模型轉換需要一定的時間,因此在本次開發中,序列化的AI模型在第一次轉換時保存在引擎檔案中,後續轉換時無需呼叫模型轉換過程即可載入和使用保存的AI模型。 這是一種加速技術,也用於 NVIDIA 的 DeepStream 框架。
PyTorch 和 TensorRT 在 x86-64 和 AMOS-9100 環境中的效能比較
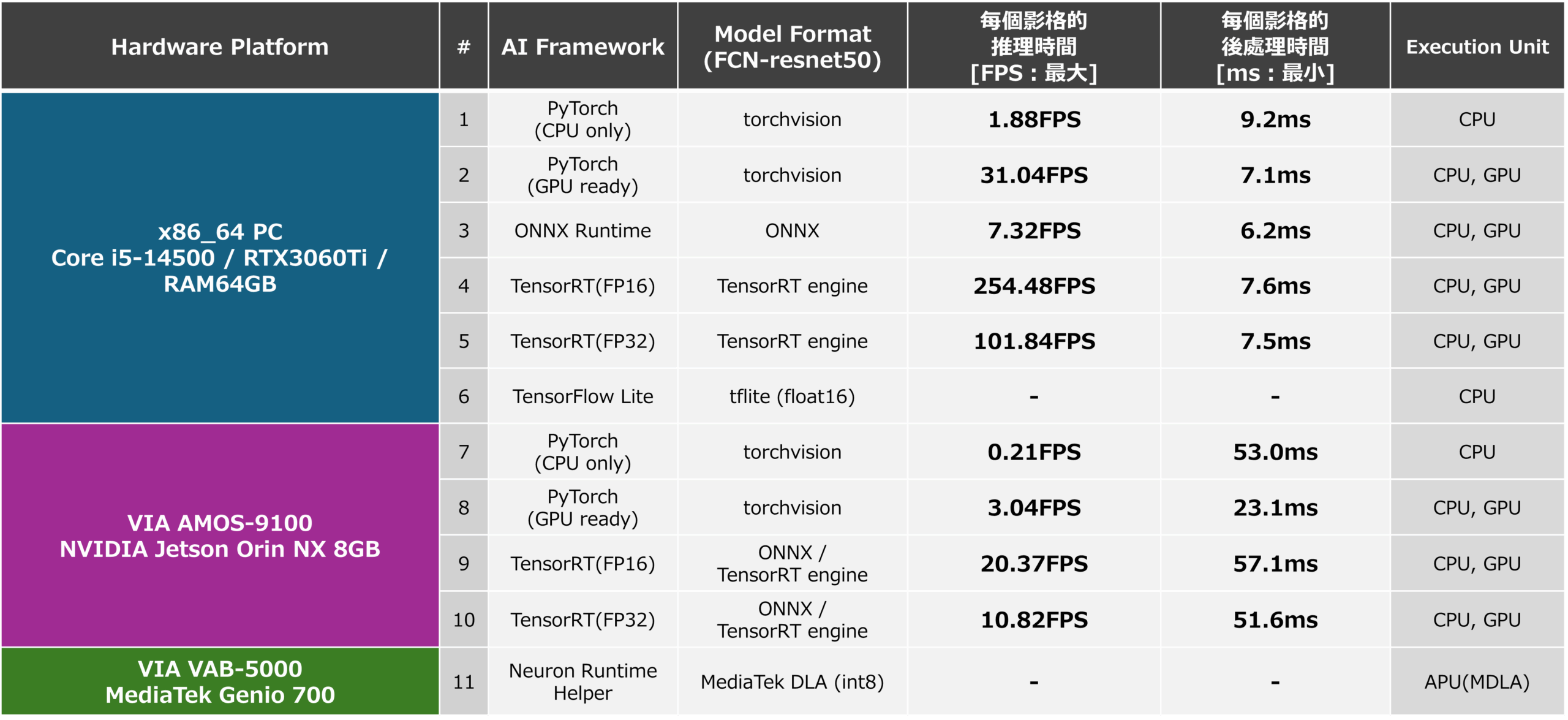
根據上述內容測量的 x86-64 和 AMOS-9100 環境的推理速度 (FPS) 和後處理處理時間如下所示。 此外,使用 ONNX Runtime 在 x86-64 環境中運行 ONNX 格式 AI 模型時的推理速度和 PostProcess 處理時間也列為參考值。 從這個結果可以確認,使用可以充分利用作為計算資源的GPU的TensorRT進行推理速度非常快。 使用 ONNX Runtime 的推理和使用 PyTorch 的推理也運行得很快,因為它們使用 GPU,但在使用 TensorRT 時並沒有實現最佳化,結果是推理速度不夠。 產生 TensorRT AI 模型時,您可以使用「trt. BuilderFlag.FP16“,推理速度為5和10,如下圖所示。 這大約是配置FP16型模型時下圖4和9推理速度的一半。 由此可以看出,透過使用FP16,安裝在GPU內部的CUDA核心和張量核心可以處理比FP32多一倍的操作,並且可以從FP16中受益。
基於這項研究的結果,通過在AMOS-9100上利用TensorRT,FCN-resnet50 AI模型可以以約20 FPS的推理速度運行,因此可以使用AMOS-9100來控制機器人,由此可見,可以將分割功能整合到需要高即時效能的應用中,例如監控攝影機。
PyTorch TensorRT 平台
針對 VAB-5000 優化 PyTorch 的模型
接下來,我們來看看在 PyTorch 上定義並移植到以MediaTek Genio 700 為核心的威盛 VAB-5000 的經過訓練的 AI 模型 FCN-resnet50 的推理速度。 此開發的目標是測量下圖中黃框所示配置的性能。 要合併到待測應用程式中的 AI 模型是使用下圖中紅線的流程產生的。 使用 TensorFlow Lite AI 模型進行的評估並不是測量推理速度,而是檢查模型是否能夠保持其正確性。
轉換並評估 NeuronHelper
使用威盛的 Neuron Runtime Helper 更快地運行 DLA 格式的 AI 模型
在 VAB-5000 上的 Debian 環境中,威盛開發的 Python 套件「Neuron Runtime Helper」可用於高速運行 DLA 格式的 AI 模型,只需少量原始碼。 若要取得 Neuron Runtime Helper 可執行的 DLA 格式的 AI 模型,請先在 x86-64 環境中將 FCN-resnet50 匯出為 ONNX 格式的 AI 模型,然後將 onnx2tf 指令套用至產生的 ONNX 格式 AI 模型,將 AI 模型轉換為 TensorFlow Lite 格式。 最後,透過應用ncc-tflite指令,將VAB-5000上Genio的AI模型轉換為TensorFlow Lite格式的AI模型,可以得到DLA格式的DC模型(上圖)。
透過 TensorFlow Lite 格式將 ONNX 模型轉換為 DLA 模型
在這項開發中,為了獲得DLA格式的AI模型,將生成的ONNX格式的AI模型轉換為TensorFlow Lite格式的AI模型,這將是中間格式。 對於此轉換,我們使用了 Python 套件提供的 onnx2tf 命令。 透過執行帶有參數「-oiqt」的 onnx2tf 命令,您可以從 ONNX 格式的 AI 模型產生多個具有各種最佳化的 TensorFlow Lite AI 模型。
下圖顯示了 onnx2tf 命令可以產生的 AI 模型。 可產生的 AI 模型包括[1] 所有操作均使用 INT8 的 AI 模型 (*_full_integer_quant),[2] 所有操作均使用 FP16 的 AI 模型 (*_float16),[3] 所有操作均使用 FP32 的 AI 模型 (*_float32),[4] 使用 INT8 進行基本操作,使用 INT16 進行激活層的 AI 模型(16×8 量化:*_full_integer_quant_with_int16_act),[5] FP16 用於輸入和輸出, 使用 INT8 進行所有其他操作的 AI 模型 (*_integer_quant),[6] 使用 FP16 進行輸入和輸出,使用 INT8 進行基本操作,使用 INT16 進行啟動層的 AI 模型 (*_integer_quant_with_int16_act),[7] 共有 7 種類型的 AI 模型 (*_dynamic_range_quant),可以在不限制類型的情況下優化計算圖。 在七個AI模型中,除了*_full_integer_quant外,還有六個AI模型包含與INT32和FP32相關的指令,而VAB-5000的APU不支持這些指令,因此很難移植到威盛VAB-5000。
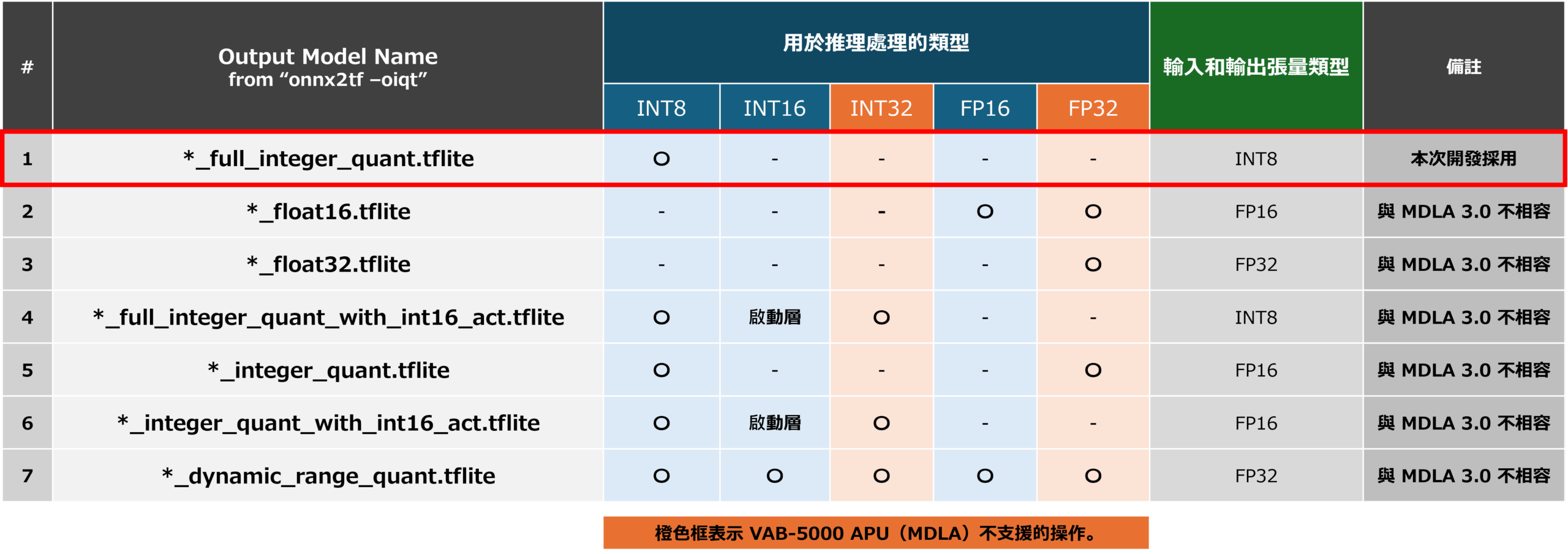
按量化劃分的模型類型
在本次開發中,為了優化VAB-5000的APU的AI模型,我們從[1]中選擇了“model_full_integer_quant.tflite”,這是生成的AI模型中針對INT8進行全面優化的模型,並使用以下ncc-tflite命令生成針對INT8優化的DLA格式的AI模型。 我用它來在 VAB-5000 上進行推理。

解決針對 INT8 優化的 AI 模型導致的檢測準確率下降問題
當ONNX格式的AI模型轉換為TensorFlow Lite格式「model_full_integer_quant.tflite」的AI模型時,將所有變數定義為INT8,並產生DLA格式的AI模型,模型內部的變數從FP32變為INT8,從而降低了可持有值的準確性。 降低物體偵測準確度。 這可降低像素包含狗的可能性,並增加像素包含背景的可能性。 發生狗物件被錯誤地偵測為背景物件,且完全無法偵測到物件的問題。 為了解決這個問題,在本次開發中,對於包含21種物體的特徵圖,刪除了將所有物體的似然之和調整為1.0(概率)的Sofmat層處理,對於總似然為1.0或更高的輸出張量,而不使用Softmax層, 我們透過將具有一定似然值或更高的像素視為狗物體,可以偵測它們。
在 VAB-5000 上執行的 DLA AI 模型效能
在 x86-64 上使用 TensorFlow Lite 執行階段執行時,上述步驟產生的 FP16 最佳化 TensorFlow Lite 格式的 AI 模型效能,以及針對 INT8 最佳化的 DLA 格式 AI 模型效能,由 VAB-5000 上的 Neuron Runtime Helper 執行,如下所示。 從結果中發現,即使是計算密集型的 AI 模型“FCN_resnet50”,通過將模型優化到 INT8 並正確利用 VAB-5000 的 CPU、GPU 和 APU,也可以以大約 5000 FPS 的速度運行。 這一結果使得 VAB-5000 適用於允許延遲容忍的領域的應用,例如視覺檢查設備、門禁控制和影像處理(生成式 AI),在這些領域中,低 FPS 不是問題。
PlatformList NeuronHelper
利用 PyTorch 提供的 AI 模型,為 AMOS-9100 和 VAB-5000 開發邊緣 AI 應用
在本文中,我們介紹了 PyTorch 定義的相對較大的計算 AI 模型可以在 AMOS-9100 和 VAB-5000 上運行,並且可以以合理的速度運行。 下圖顯示了透過本文獲得的 AMOS-9100 和 VAB-5000 的功能,以及每個平台擅長的建議最佳化和用例,這些都可以從測量結果中得出。 這些結果表明,AMOS-9100適用於需要即時推理的領域,而VAB-5000則適用於對低功耗要求強烈且可以容忍延遲的領域。
另外,不包含註釋資料的影片被視為推理的輸入,因此對AI模型推理準確性的評估是定性的。 在以後的文章中,我想使用帶有註釋資料和標籤資料的輸入資料來介紹 mAP 和 IoU 等定量結果。
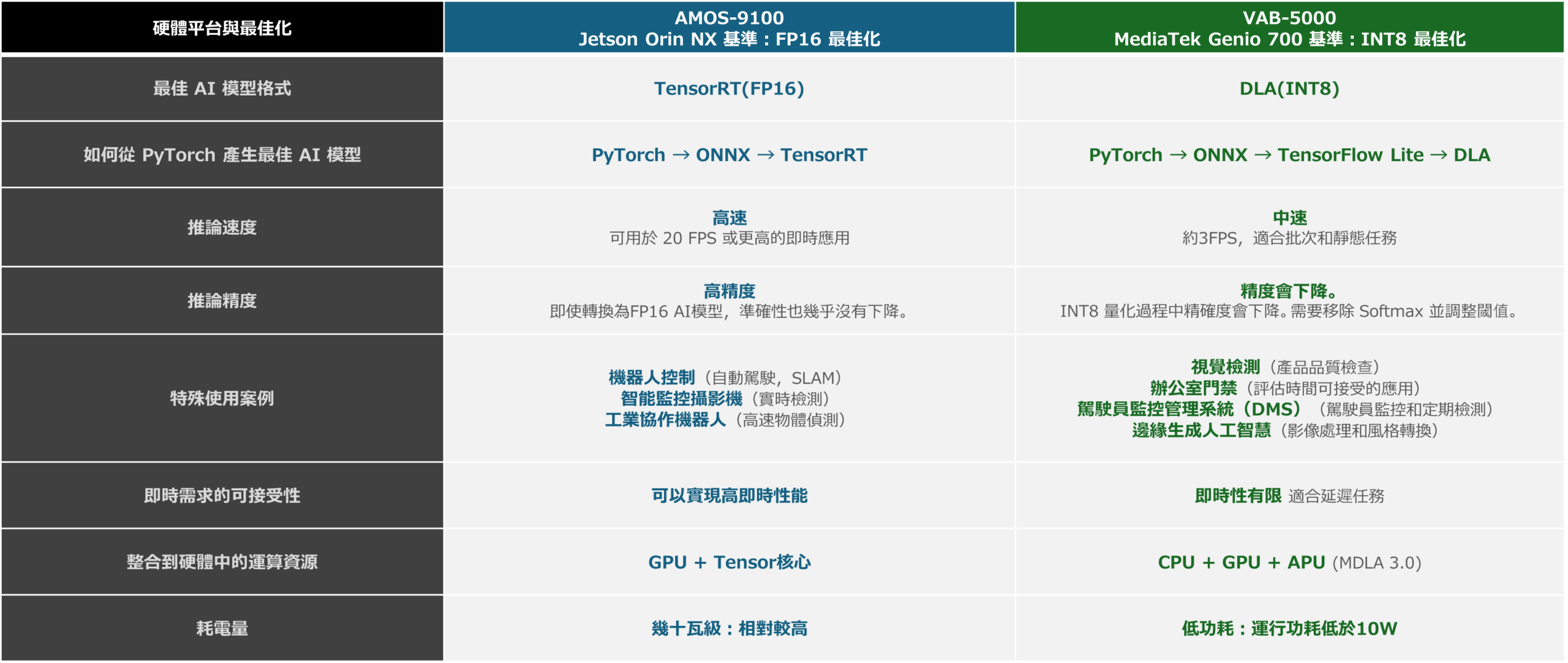
平台和模型
此外,通過這種開發測量的推理速度總結如下圖所示。 結果表明,透過利用應用其優勢的人工智慧模型,他們可以為預期的用例實現合理的推理速度。
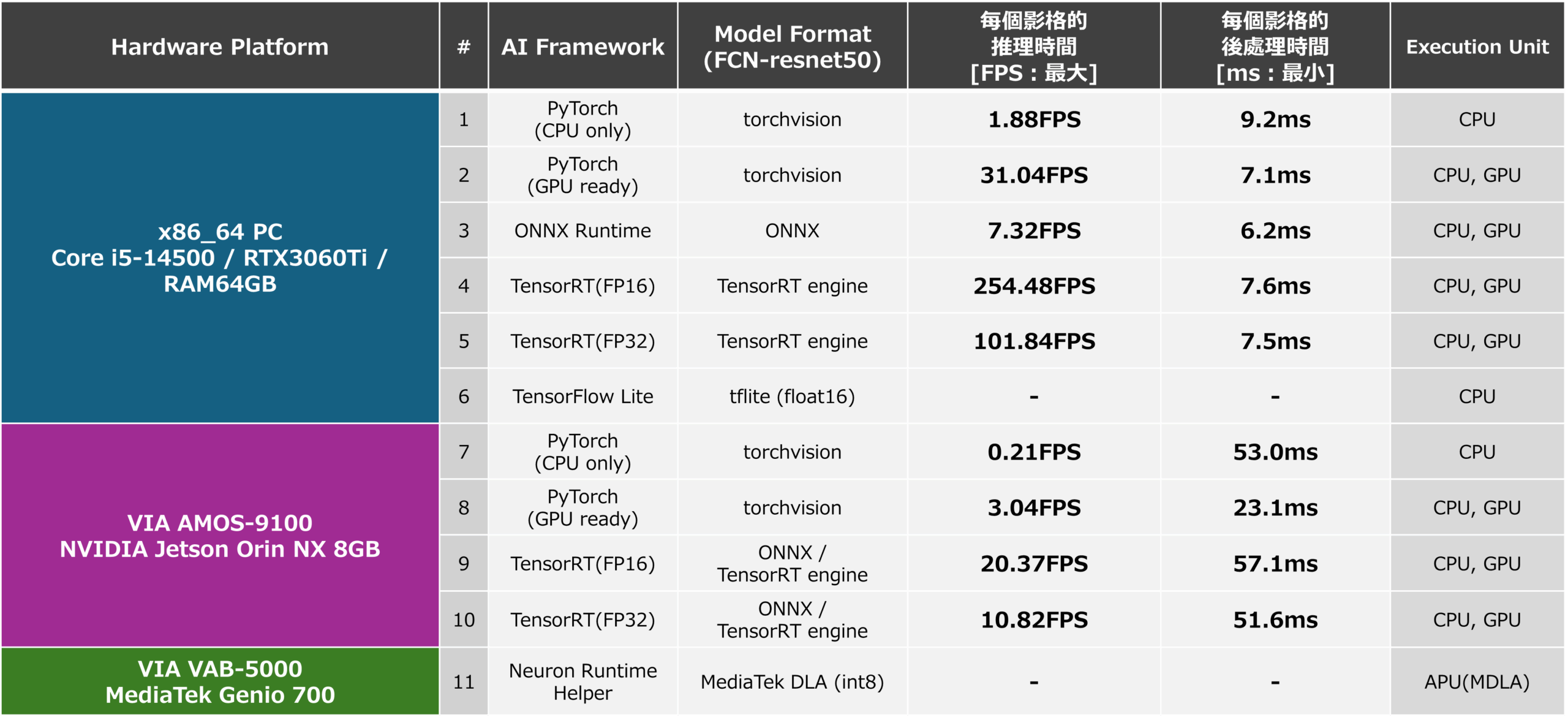
所有平台

轉換及評估-所有
AMOS-9100 和 VAB-5000 具有廣泛的 AI 模型,包括透過 NVIDIA TAO Toolkit、NVIDIA GPU Cloud 和 TensorFlow Hub 分發的模型
在之前的文章中,我們介紹了將 NVIDIA TAO Toolkit、NVIDIA GPU Cloud、TensorFlow Hub 等提供的 AI 模型用於在 VAB-5000 上運行的 AI 應用的能力。 根據本文的內容,可以利用 PyTorch 定義的 AI 模型進行 VAB-5000 和 AMOS-9100 的開發,並可用於建立更先進的 AI 應用程式。 請使用 VAB-5000 和 AMOS-9100 等產品來開發邊緣 AI 產品。若您有關於VAB-5000 或 AMOS-9100 是否適合您的應用等問題,請隨時與我們聯繫。