_a.png)
産業分野におけるAIアプリケーションの実装にはAIフレームワーク「TensorFlow」が広く利用されていますが、研究分野や学術分野ではプロトタイピングのしやすいAIフレームワーク「PyTorch」が高い人気を誇ります。このことから、x86-64環境のPyTorch上で定義されたAIモデルを、エッジデバイスをはじめとする組み込み環境上に移植して実行するといったユースケースは少なくないでしょう。そこで本記事ではx86-64環境のPyTorch上に定義されたAIモデルを、組み込み環境であるNVIDIA Jetson Orin NXをベースとしたプロダクトであるVIA AMOS-9100ならびにMediaTek Genio 700をベースとしたプロダクトであるVIA VAB-5000上に移植する手順と、この手順により構築することのできるAIアプリケーションの推論速度について解説いたします。なお、本記事における評価には比較的計算量の大きいAIモデルである「FCN-resnet50」を利用しました。FCN-resnet50は画像中から特定のオブジェクトが含まれるピクセルを選出するセグメンテーション機能を提供するAIモデルです。本記事を通してx86-64環境のPyTorch上にて定義されたAIモデルを、VIAのエッジAI向けプロダクト上へと移植する手順と、これらのハードウェアに統合されたGPUやAPUといったアクセラレータが推論速度に与える効果について、ご理解いただければ幸いです。
PyTorchモデルをAMOS-9100/VAB-5000で動かす
お忙しい方向けに、このページに掲載されている「PyTorchモデルをエッジデバイスで動かすPodcast」の情報を、短時間でご理解いただけるよう音声で要約・解説します。通勤中や少しの休憩時間にご活用いただき、AI開発プロジェクトのヒントとしてお役立てください。
聴きどころ
研究で人気のPyTorchモデルを、産業界で使われるTensorFlowやエッジデバイスへ移植する背景と課題を解説します。
異なるAIフレームワーク間でAIモデルを効率的に交換する共通フォーマットONNX。エッジデバイス移植における鍵となる役割を説明します。
NVIDIA Jetson Orin NX搭載AMOS-9100でTensorRTとFP16最適化を施し、約20FPSを実現した高速化戦略を詳述します。
MediaTek Genio 700搭載VAB-5000でINT8量子化。精度低下の問題とその解決策としてモデル修正を行った工夫を解説します。
エッジAIの実用化で重要な速度、精度、消費電力の三要素。用途に応じた最適なデバイス選びとトレードオフの考え方を解説します。
PyTorchとTensorFlowの市場シェア
下図に、産業分野において機械学習を活用したアプリケーションの実装にいずれのフレームワークが利用されているかを示す、各フレームワークの普及率を表すグラフを示します(引用元:State of Data Science and Machine Learning 2021)。最も普及率の高い「Scikit-learn」は、機械学習に関するプリミティブな機能を提供するライブラリであることから、深層学習つまりAI向けのフレームワークとしては「TensorFlow」や、そのサブセットである「Keras」が高い人気であることがわかります。TensorFlowは、習得に至るまでの学習曲線の緩やかさではなく、デプロイのしやすさを理由に選ばれています。AIアプリケーションを開発する際のフレームワークにTensorFlowを採用することで、デプロイ時にメモリ使用量や計算グラフを最適化することが可能となるため、大規模なAIモデルをデプロイするケースや、コンピューティングリソースに制限のある環境に対してAIモデルをデプロイするケースなど、開発における様々なユースケースに対応することができます。なお、TensorFlowの対比として名前が挙げられるAI向けのフレームワーク「PyTorch」の普及率は、産業分野では5位となっています。
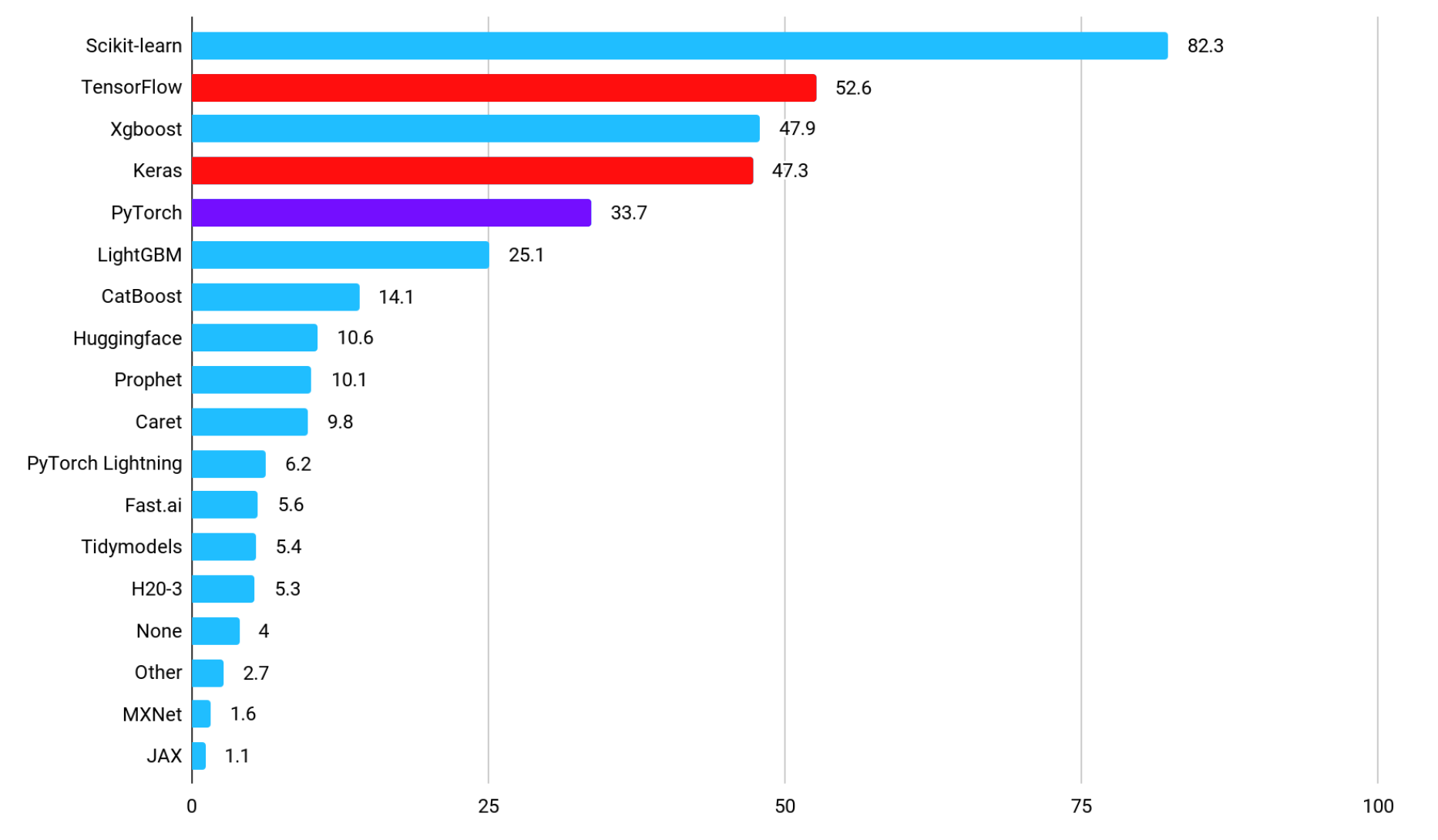
TensorFlow and PyTorch on Kaggle
研究分野や学術分野において高い人気を誇るPyTorch
一方で、研究分野や学術分野において論文の公式実装に利用されているAI向けのフレームワークの普及率は下図のようになっており、「PyTorch」が圧倒的な人気を誇ります(引用元:ML Engineer comparison of Pytorch, TensorFlow, JAX, and Flax)。研究分野や学術分野でPyTorchが広く利用されている背景には、PyTorchが掲げる3つの特長が関係しています。1つ目の特長は、PyTorchがPythonライクな動的計算グラフを採用しており、直感的にコーディングできるだけでなく、デバッグも容易であるという点です。2つ目の特長は、動的計算グラフの採用により、モデルの構造を動的に変更しやすく、条件分岐やループなどを比較的簡単に実装することが可能であり、手早く複雑なモデルを構築できる点や、新しいアルゴリズムを実装しやすいといった点にあります。PyTorchを利用することにより、Hugging FaceやPyTorch Lightningをはじめとする様々なオープンソースライブラリとの結合が容易であることも、その人気のひとつです。PyTorchが選ばれている3つ目の理由は、PyTorchを利用することによって、AIモデルの開発者が研究目的で設立されたコミュニティやエコシステムと連携しやすくなるといった特徴にあります。PyTorchはディープラーニングを研究しているコミュニティであるCVPR、NeurIPS、ICMLで広く採用されており、最新の研究論文では、それらの公式実装にPyTorchが広く利用されています。物体検出において高い性能を誇るAIモデル「YOLOv12」の公式実装にもPyTorchが採用されています。

TensorFlow and PyTorch in Paper
本記事で扱うAIモデル概要
本記事ではx86-64環境のPyTorch上に定義されたAIモデル「FCN-resnet50」を、VIA AMOS-9100やVIA VAB-5000上に移植した際の推論速度について解説します。
セグメンテーションを行うAIモデル – FCN-resnet50
FCN-resnet50は画像のセグメンテーションを行うAIモデルであり、入力された画像中のすべての画素に対して、それぞれの画素に21種類いずれのオブジェクトが含まれているかの尤度を出力します。FCN-resnet50は50層の全層畳み込みネットワーク(Fully Convolutional Networks:FCN)から構成されたAIモデルであり、バウンディングボックスを出力する畳み込み層と全結合層から構成される一般的な物体検出のAIモデルに比べて計算量が多い傾向にあります。本記事では、FCN-resnet50を動画の各フレームに対して適用し、動画中から犬のオブジェクトが含まれているピクセルを特定。犬のオブジェクトが存在する画素に対して下図のようにマスクをかけて表示するAIアプリケーションをx86-64環境上、AMOS-9100上、VAB-5000上に実装して、その性能を比較します。

Application Output
本記事における推論性能の評価方法
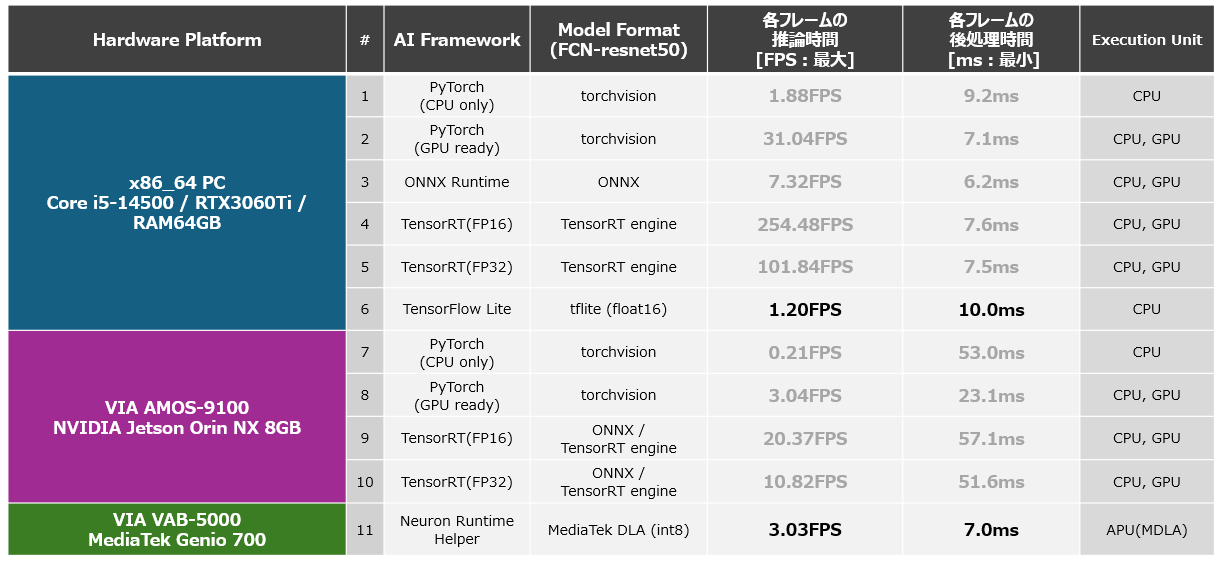
本記事で実装するアプリケーションは、AIモデル「FCN-resnet50」に対して、動画の各フレームから切り出した288px x 288pxの正方形のRGB形式の画像を入力として与え、出力として各ピクセルに21種類いずれのオブジェクトが含まれているかを示す288px x 288pxの尤度を含んだ特徴量マップ(Feature Map)を取得。特徴量マップの特定のレイヤーに格納されている「各画素が犬を構成するピクセルである尤度」を参照し、尤度が一定値以上のピクセルに対してマスクを作成。リアルタイムに犬が含まれる領域を上図のように表示します。本記事では推論速度を、AIモデルに288px x 288pxのRGB形式の画像を入力してから特徴量マップが出力されるまでの時間から算出できるFPS(Frames Per Second)を基準に評価し、AMOS-9100やVAB-5000における最適なAIフレームワークについて考察します。また、参考値として特徴量マップからマスク付きの出力画像を生成するPostProcessの時間も計測しました。本記事では、これらの性能測定を、以下に挙げるハードウェアプラットフォーム、フレームワーク、アクセラレータの構成の異なる11種類の環境で実装したアプリケーションに対して行い、性能を比較します。なお、動画から正方形の画像を切り出すPreProcessの処理と、特徴量マップからマスク付きの画像を生成するPostProcessの処理の実装には一般的なOpenCVの機能を利用しました。
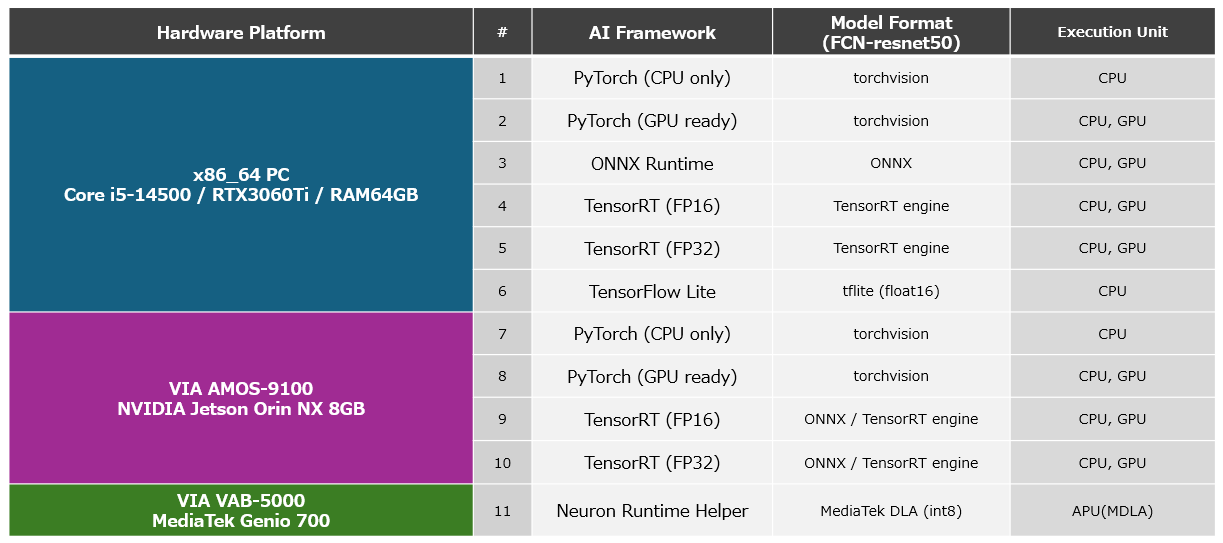
Platform List
機械学習で利用される主要なフレームワークとその特長
本節では、アプリケーションについて解説する前に、AIの開発に利用される主要なフレームワークと、その特長について解説します。
PyTorchの特長
PyTorchはPythonライクなAPIを提供することにより、直感的にAIモデルをコーディングできることを促すAIフレームワークです。PyTorchはAIモデルの定義に計算グラフを動的に定義する「Define-by-Run」と呼ばれる方式を採用しており、柔軟なAIモデルの変更や、複雑なAIモデルの構築、それらに対する容易なデバッグを可能としています。また、PyTorchは研究用途におけるAIモデルのプロトタイピングや公式実装にも適しており、カスタムレイヤーを定義することや、オリジナルの損失関数を定義すること、そして複雑なネットワーク構造を持ったAIモデルの学習に効果的な自動微分(AutoGrad)の機能を利用することが可能です。さらにPyTorchはハードウェアアクセラレータとしてGPUを利用するためのライブラリであるCUDAもサポートしていることから、GPUを使った高速な学習が可能となっています。PyTorchは組み込み環境に対してはほとんど移植されていませんが、学習済みのAIモデルを後述するONNX形式でエクスポートする機能を利用することにより、エッジをはじめとする様々な環境に対してモデルを配布することができます。
ONNXの特長
ONNXは学習済みのAIモデルを、PyTorchやTensorFlowといった異なるAIフレームワーク間で効率的に交換できるようにすることを目指した、相互運用性を高めるためのフレームワークです。ONNXを利用することにより、クラウドからエッジに至るまで様々なプラットフォーム上で動作しているAIモデルを、わずかな作業工数で組み込みアプリケーションに統合することが可能です。これにより、PyTorchで実装されたクラウド上で高い利用実績を誇るAIモデルや、研究用途として開発され公開されたばかりの最新のAIモデルを、TensorFlowやTensorRTといったAIフレームワークを使ってエッジに備えられたハードウェアリソースにあわせて最適化されたAIモデルとしてデプロイすることができるようになり、先進的でありながらハードウェアに最適化されたAIアプリケーションを手早く開発することが可能です。なお、ONNX形式のAIモデルはONNX Runtimeを利用することにより、PyTorchやTensorFlowほどの最適化は行われませんが、ONNX形式のままアプリケーション内に組み込み、プロトタイピングに利用することもできるようになっています。本記事はONNX Runtimeによる推論速度についても解説いたします。
TensorFlowの特長
TensorFlowは計算量の大きなAIモデルのデプロイや、ハードウェアリソースの限られたエッジへAIモデルをデプロイする際に最適なAIフレームワークです。PyTorchと比べると学習曲線はやや急ですが、習得後はTensorFlow ServingやTensorFlow Liteを活用することにより、AIモデルを様々なプラットフォーム向けに最適化してデプロイすることが可能となります。PyTorchもデプロイ機能を提供していますが、TensorFlowのデプロイ機能の方が本番環境において高い実績があり、広く普及しています。MediaTek Genio 700をベースとしたVIA VAB-5000では、TensorFlow Lite形式のAIモデルを基に、MediaTek製のツールセットを使ってAPUやGPU向けに最適化されたDLA形式のAIモデルを生成し、ハードウェアアクセラレータを効率的に活用できる高速なAIアプリケーションを構築することが可能です。PyTorchで先端的なAIモデルを実装し、推論精度を高めた後に、ONNX形式を経由してTensorFlow Lite形式のAIモデルへと変換。ハードウェアリソースに最適化して本番環境へとデプロイし、高速に動作するアプリケーションを構築するといった開発手法は、高度なシステムを開発する際の最適解といえるでしょう。
TensorRTの特長 (AMOS-9100)
TensorRTは、NVIDIA製のGPUが搭載されているNVIDIA Jetson Orin NXベースのAMOS-9100環境や、NVIDIAのGPUを搭載したx86-64環境で利用することのできるAIの推論に特化したNVIDIA製のフレームワークです。TensorRTはAIにおける推論フェーズに焦点を当て、推論に最適化されたライブラリや、それを制御するためのAPIを提供します。TensorRTはAIモデルの推論速度を向上させるだけでなく、FP16やINT8といった低精度なフォーマットの変数を積極的に利用することや、複数の層の演算を統合することにより、メモリの消費量を削減することも可能です。なお、TensorRT向けのAIモデルはONNX形式のAIモデルから作成することができます。本記事では、PyTorch上に定義されたAIモデル「FCN-resnet50」を、ONNX形式のAIモデルを経由し、TensorRT向けのAIモデルへと変換。AMOS-9100上で実行する手順と、その性能について紹介します。
MediaTek NeuroPilot SDK / MDLA3.0の特長 (VAB-5000)
MediaTekの提供するNeuroPilot SDKは、MediaTek Genio 700等のAPU(MDLA3.0)を搭載したSoCを核としたVIA VAB-5000をはじめとするプロダクト上で利用できるAIフレームワークです。NeuroPilot SDKを利用することにより、TensorFlow形式のAIモデルをGenioのハードウェアに最適化されたDLA形式のAIモデルへと変換し、Genioに統合されたGPUやAPUなどのハードウェアアクセラレータを利用して高速な推論を実現することが可能です。本記事では、PyTorchで定義されたAIモデル「FCN-resnet50」を、ONNX形式とTensorFlow Lite形式を経由してDLA形式のAIモデルへと変換。それらの実行フレームワークであるVIA独自の「Neuron Runtime Helper」を使ってVIA VAB-5000上でAIモデルを高速に実行する方法と、その性能について紹介します。
MediaTek Genio 700の製品概要(外部サイト:英語)
MediaTekの提供するAI向けソリューション(外部サイト:英語)
PyTorchのモデルをAMOS-9100に最適化する
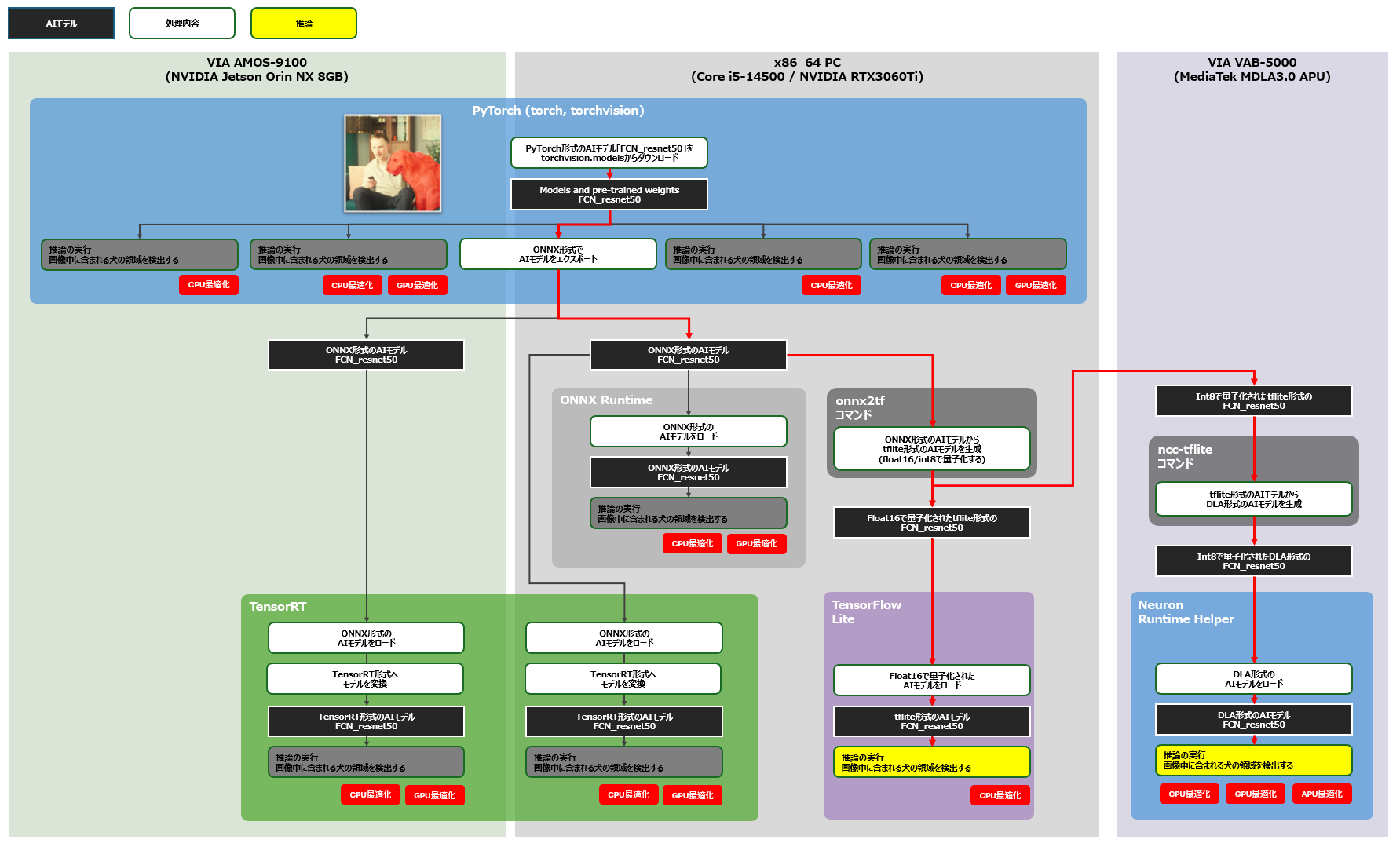
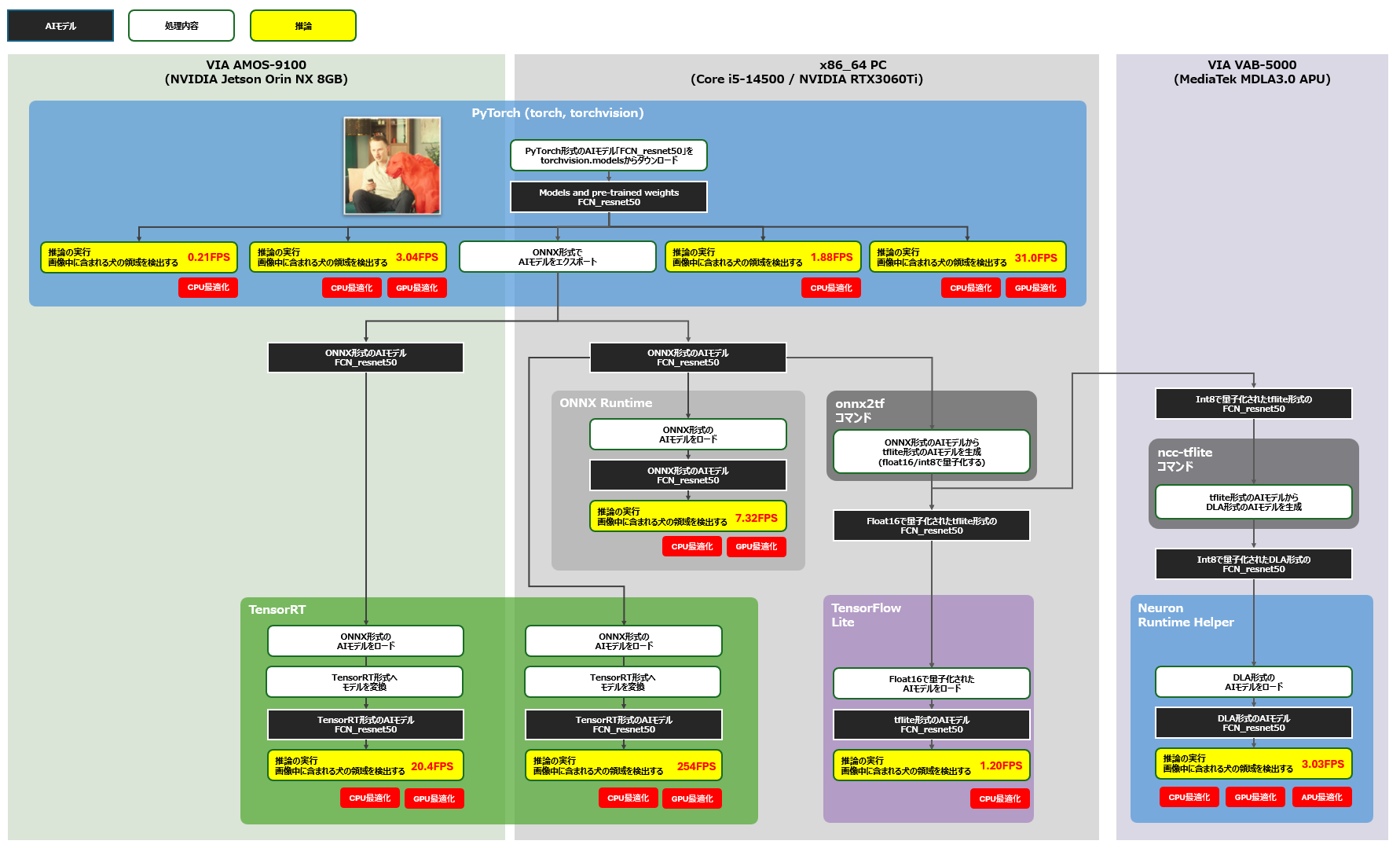
それでは早速、PyTorch上に定義した学習済みのFCN-resnet50をAMOS-9100上に移植する開発を進めていきましょう。本開発のゴールは以下の図中に黄色枠で示す構成の性能を計測することです。まず、x86-64環境の各AIフレームワークにおけるFCN-resnet50の推論速度を計測し、次にAMOS-9100環境においてPyTorch上でのAIモデルの推論速度と、GPUでの推論に特化したTensorRT上でのAIモデルの推論速度を計測します。計測対象となるアプリケーションに組み込むAIモデルは、下図赤線のフローにより生成しました。

convert and eval PYTorch-TensorRT
x86-64環境およびAMOS-9100環境でPyTorchのモデルを定義する
まず、x86-64環境およびAMOS-9100環境でPyTorchのtorchvisionパッケージを利用して学習済みのFCN-resnet50をロードします。学習済みの重みが付いたFCN-resnet50は、PyTorchの拡張ライブラリであるtorchvision上で配布されており、以下のソースコードを実行するだけでAIモデルを取得することができます。
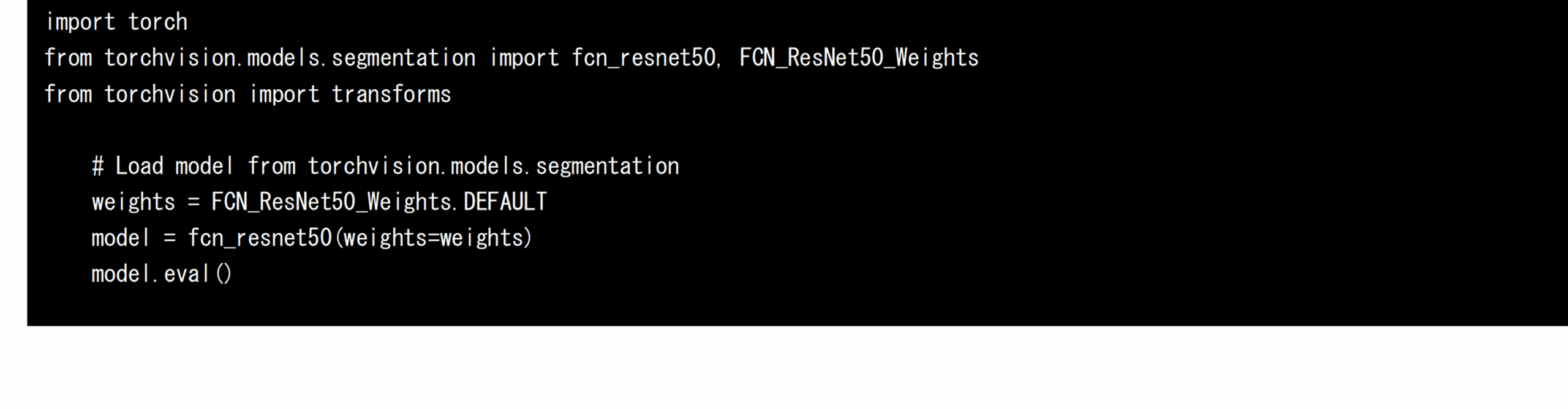
PyTorchでは、以下のソースコードにより、ロードされたAIモデルと、PreProcess(後述)を経て生成された入力テンソルをGPU上に転送し、GPUを使って高速に推論することができます。GPUへの転送処理を実行しなければ、CPUのみを利用した推論処理が実行されます。それぞれの推論速度の算出には、推論の前後のCPU時刻を利用しました。

PyTorchの性能を計測する際の注意点
PyTorch上でAIモデルの推論時間を、CPU時刻を使って計測する場合、推論処理を呼び出した後に torch.cuda.synchronize() を呼び出す必要があることに注意してください。これは、GPUを使ったPyTorchの推論処理が非同期で動作するためです。 torch.cuda.synchronize() を呼び出すことにより、推論処理が完了したことを保証できるため、推論の開始から完了までの時間を正確に計測することができます。もし、torch.cuda.synchronize() を呼び出さずに性能を計測した場合はPostProcess処理にてCPUから特徴量マップにアクセスする際に初めてCPUとGPUの同期処理が行われることから、推論時間の一部がPostProcessの処理時間に計上される結果となってしまいます。
OpenCVでPostProcessとPreProcessを定義する
本アプリケーションでは、動画からフレームを切り出すPreProcessの処理と、推論結果として得られた特徴量マップからマスク付きのフレームを生成して表示するPostProcessの処理を、OpenCVを利用して定義しました。PreProcessとPostProcessの処理フローは下図の通りです。
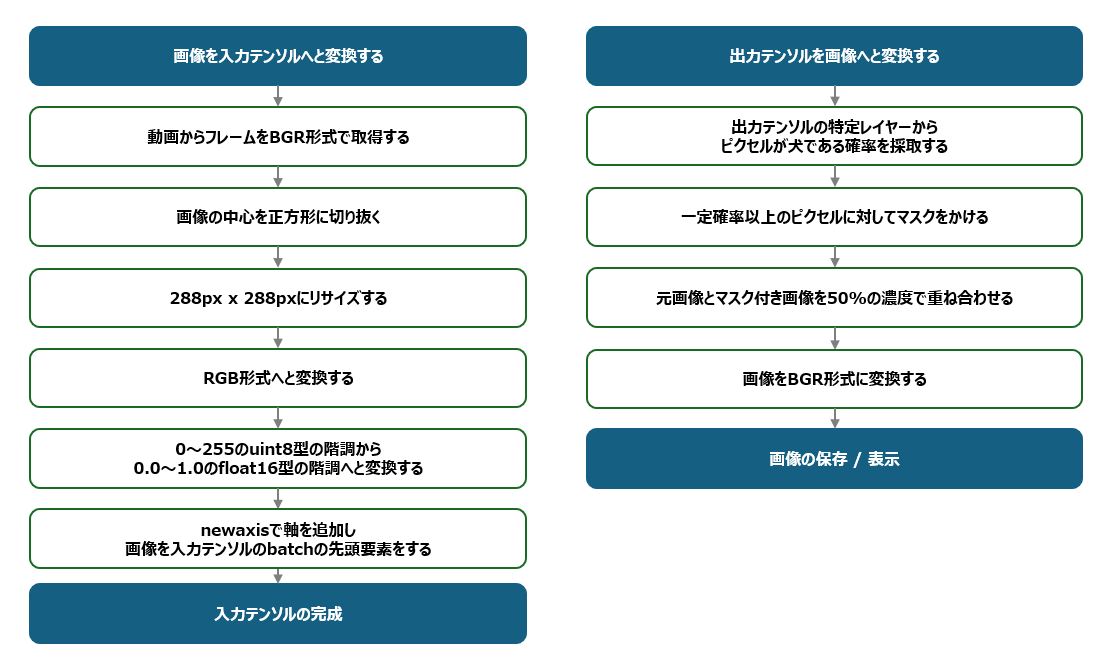
convert tensor to from image
PyTorch上のAIモデルをONNX形式のモデルへと変換する
次に、PyTorchのtorchvisionから取得した学習済みのFCN-resnet50をONNX形式のAIモデルとしてエクスポートします。エクスポートする際には入力テンソルのサイズを固定する必要があるため、以下のソースコードのようにダミーの入力テンソルを定義し、それを指定します。本開発では、FCN-resnet50の入力テンソルの形状を288px x 288pxに固定し、model.onnxファイル にエクスポートしました。エクスポートされたONNX形式のAIモデルは、他のAIフレームワーク向けに変換するだけでなく、ONNX Runtimeを活用して直接推論に利用することも可能です。本開発では、ONNX Runtimeを利用した際の推論速度も計測、評価します。
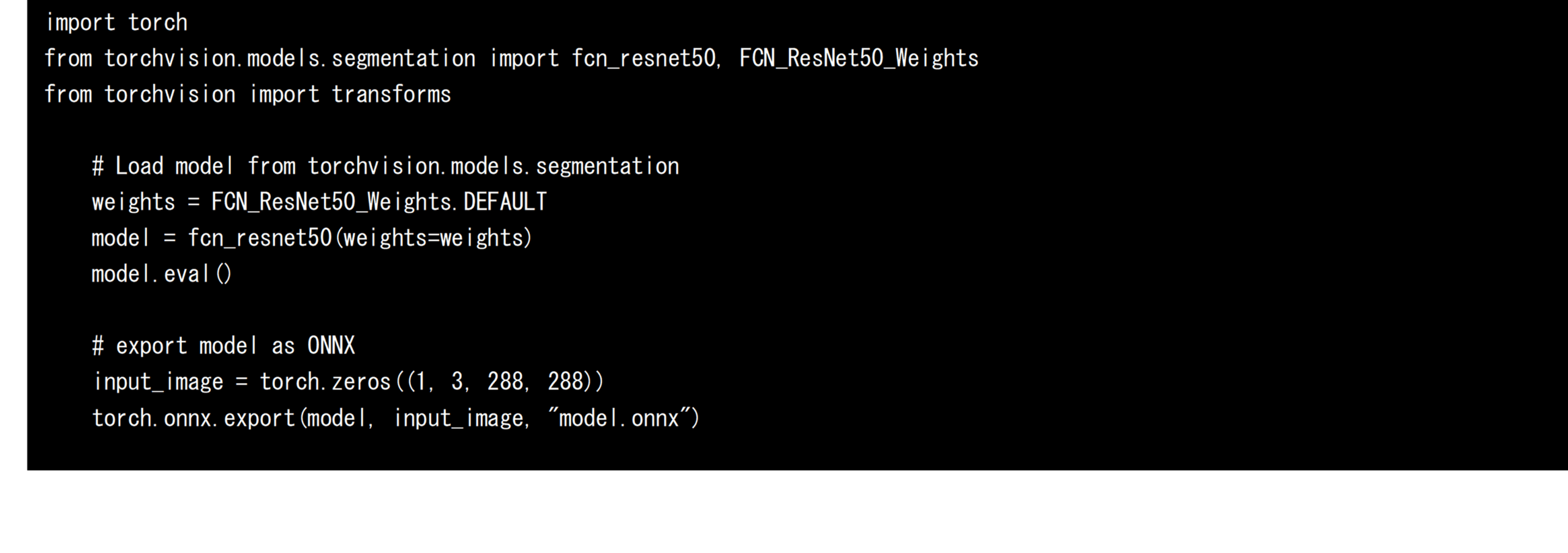
ONNX形式のAIモデルをTensorRT向けのモデルへと変換する
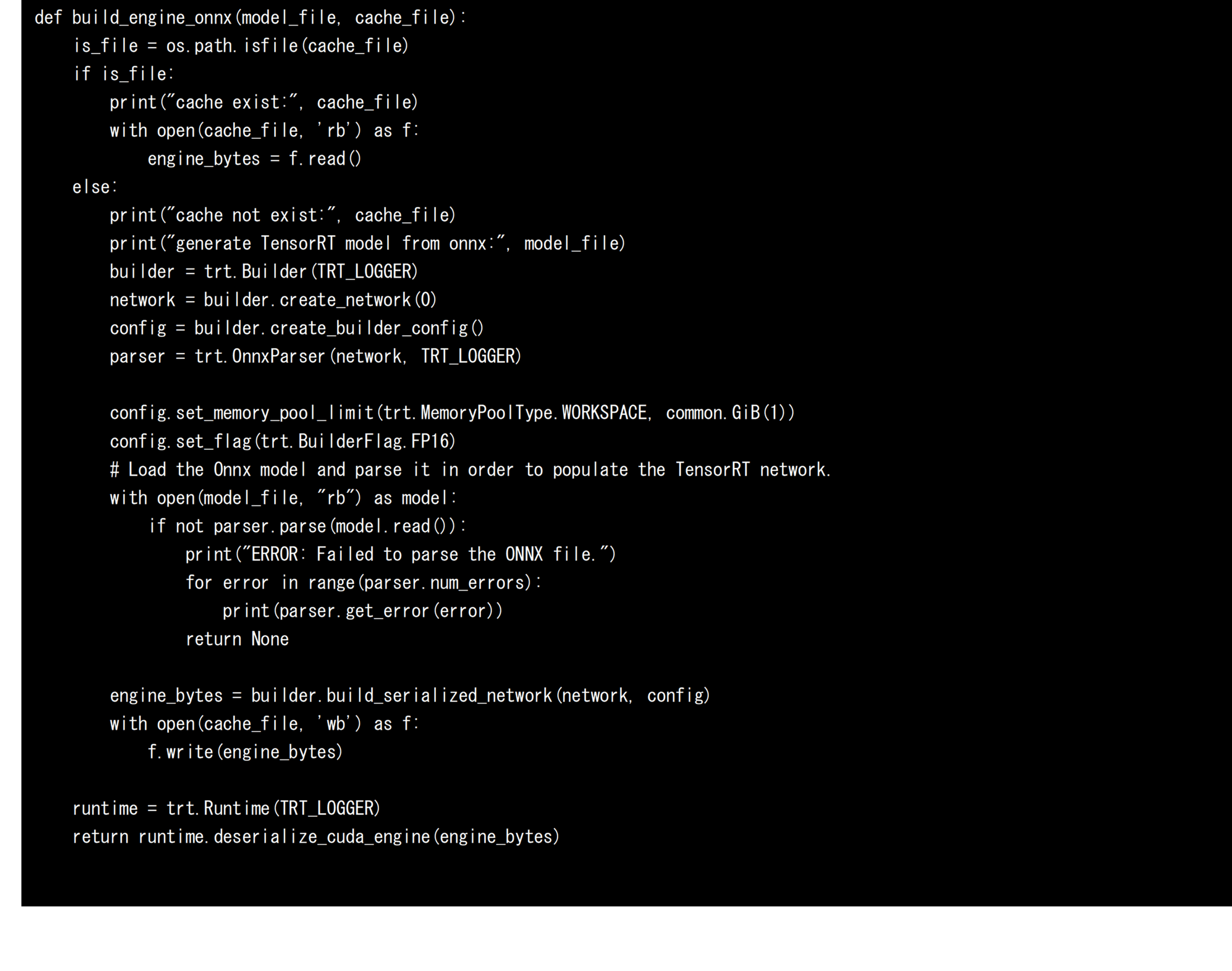
続いて、NVIDIAのGPUを搭載したAMOS-9100環境やx86-64環境でAIモデルを高速に実行するために、ONNX形式のAIモデルをTensorRT向けのAIモデルへと変換します。AIモデルをTensorRT向けに変換する場合、Builder、Network、Config、Parserの4つの要素を定義し、利用します。ParserがONNX形式のAIモデルを解析し、Networkが計算グラフを定義。Configが変換する際のオプションを決定し、BuilderがTensorRT向けのAIモデルを生成します。本開発ではAIモデルをFP16に最適化するため、Configに「trt.BuilderFlag.FP16」を指定しました。この指定により、メモリの使用率を抑え、演算ユニットを効率的に利用できるFP16に最適化されたTensorRT向けのAIモデルを生成することができます。このConfigを指定しない場合、AIモデルはFP32に最適化されます。以上に基づいて、ONNX形式のAIモデルをTensorRT向けのAIモデルへと変換するソースコードを以下に示します。なお、モデルの変換にはまとまった時間が必要となるため、本開発では初回の変換時にシリアライズされたAIモデルをengineファイルへ保存し、以降の変換時にはモデルの変換処理を呼び出さず、保存されたAIモデルをロードして利用する実装としました。これはNVIDIAのDeepStreamフレームワークにも採用されている高速化手法です。
x86-64環境とAMOS-9100環境におけるPyTorch、TensorRTの性能比較
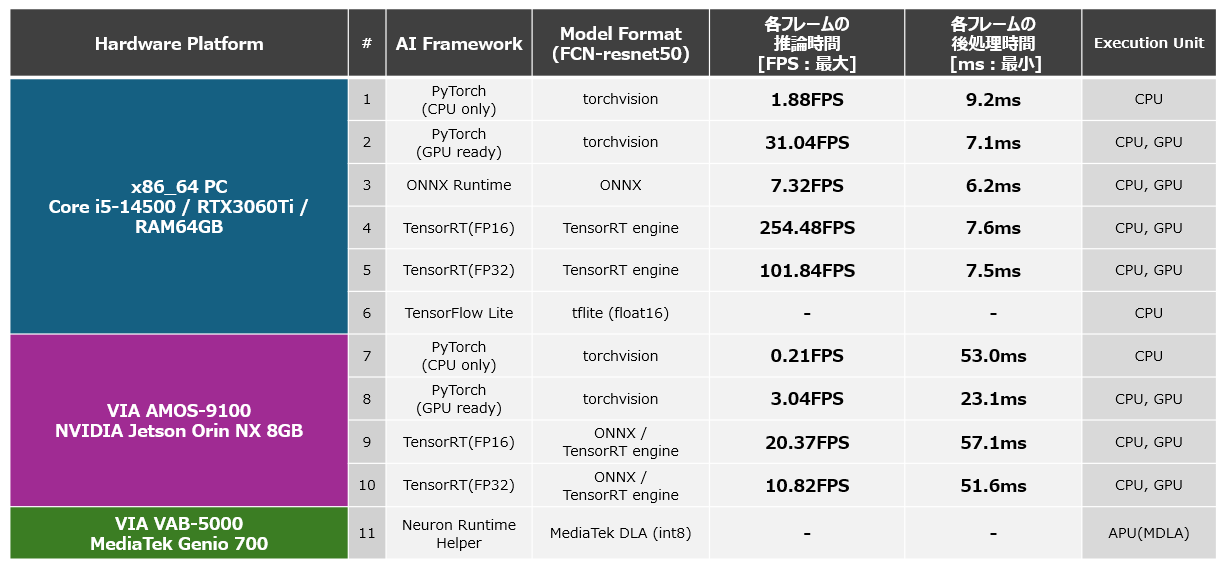
以上に基づいて計測したx86-64環境とAMOS-9100環境の推論速度(FPS)とPostProcessの処理時間を以下に示します。また、x86-64環境にて生成したONNX形式のAIモデルをONNX Runtimeにより実行した際の推論速度とPostProcessの処理時間も参考値として掲載します。本結果から、コンピューティングリソースであるGPUを余すことなく活用できるTensorRTを活用した推論が非常に高速であることを確認することができます。ONNX Runtimeによる推論や、PyTorchによる推論もGPUを利用しているため高速に動作しますが、TensorRTを活用した際の最適化には至らず、十分な推論速度は得られないという結果となりました。なお、TensorRTのAIモデルを生成する際に、Configに「trt.BuilderFlag.FP16」を指定せず、FP32型でモデルを構成した場合の推論速度は下図の5、10となります。これは、FP16型でモデルを構成した場合、下図の4、9の半分程度の推論速度です。このことから、FP16を利用することにより、GPU内部に搭載されたCUDAコアやテンソルコアがFP32の場合よりも倍の演算を処理できており、FP16化することの恩恵を受けることができていることがわかります。 AMOS-9100上でTensorRTを活用することによりFCN-resnet50のAIモデルを20FPS程度の推論速度で実行できるという今回の結果から、AMOS-9100を利用することでロボットの制御や、監視カメラをはじめとする高いリアルタイム性が欠かせないアプリケーションにセグメンテーション機能を組み込むことが可能であることがわかります。
PlatformList PyTorch TensorRT
PyTorchのモデルをVAB-5000に最適化する
続いてPyTorch上に定義した学習済みのAIモデルであるFCN-resnet50を、MediaTek Genio 700を核としたVIA VAB-5000上に移植した際の推論速度を見ていきましょう。本開発のゴールは下図に黄色枠で示す構成の性能を計測することです。計測対象となるアプリケーションに組み込むAIモデルは、下図赤線のフローにより生成しました。なお、TensorFlow Lite形式のAIモデルを利用した評価は、推論速度を計測するためでなく、モデルの正しさを維持できているかを確認するために実施しました。
convert and eval NeuronHelper
VIAのNeuron Runtime HelperでDLA形式のAIモデルを高速に実行する
VAB-5000上のDebian環境では、VIAの開発したPythonパッケージである「Neuron Runtime Helper」を利用することにより、DLA形式のAIモデルをわずかなソースコードのみで高速に実行することができます。Neuron Runtime Helperにより実行できるDLA形式のAIモデルを入手するためには、まずx86-64環境上でFCN-resnet50をONNX形式のAIモデルとしてエクスポートし、次に生成されたONNX形式のAIモデルに対してonnx2tfコマンドを適用してAIモデルをTensorFlow Lite形式へと変換。最後にVAB-5000上でGenio向けにAIモデルを変換するためのncc-tfliteコマンドをTensorFlow Lite形式のAIモデルに対して適用することにより、DLA形式のAIモデルを入手することができます(上図)。
ONNX形式のモデルをTensorFlow Lite形式を介してDLA形式のモデルへと変換する
本開発では、DLA形式のAIモデルを得るために、生成したONNX形式のAIモデルを、中間形式となるTensorFlow Lite形式のAIモデルへと変換します。この変換にはPythonパッケージにより提供されるonnx2tfコマンドを利用しました。onnx2tfコマンドに引数「-oiqt」を付けて実行することによりONNX形式のAIモデルから、様々な最適化を施した複数のTensorFlow Lite形式のAIモデルを生成することができます。
onnx2tfコマンドにより生成できるAIモデルを下図に示します。生成できるAIモデルには、[1] すべての演算にINT8を利用するAIモデル(*_full_integer_quant)、[2] すべての演算にFP16を利用するAIモデル(*_float16)、[3] すべての演算にFP32を利用するAIモデル(*_float32)、 [4] 基本的な演算にはINT8を利用し、活性化層にINT16を利用するAIモデル(16×8量子化:*_full_integer_quant_with_int16_act)、[5] 入出力にFP16を利用し、その他のすべての演算にINT8を利用するAIモデル(*_integer_quant)、[6] 入出力にFP16を利用し、基本的な演算にはINT8を利用し、活性化層にINT16を利用するAIモデル(*_integer_quant_with_int16_act)、[7] 型を限定せずに計算グラフを最適化したAIモデル(*_dynamic_range_quant)の合計7種類があります。なお、7種類のうち、*_full_integer_quantを除く6種類のAIモデルはVAB-5000のAPUがサポートしていないINT32とFP32に関する命令を含んでいるため、VIA VAB-5000上へ移植することは困難です。

ModelType by Quantization
本開発ではAIモデルをVAB-5000のAPUに最適化するために、生成されたAIモデルのうち完全にINT8に最適化されたモデルである[1]の「model_full_integer_quant.tflite」を選択し、以下のncc-tfliteコマンドを使ってINT8に最適化されたDLA形式のAIモデルを生成。VAB-5000上での推論に利用しました。

INT8に最適化されたAIモデルにて発生する検出精度の低下への対応
ONNX形式のAIモデルを、すべての変数をINT8として定義するTensorFlow Lite形式のAIモデル「model_full_integer_quant.tflite」へと変換し、DLA形式のAIモデルを生成すると、モデル内部の変数がFP32からINT8に変化するため、保持できる値の精度が低下し、オブジェクトの検出精度が低下します。これにより、ピクセルに犬が含まれている尤度が低下し、ピクセルに背景が含まれている尤度が上昇。犬のオブジェクトを背景オブジェクトと誤検出し、オブジェクトを全く検出できなくなる問題が発生します。この問題に対処するため、本開発では、21種類のオブジェクトが含まれた特徴量マップに対して、全オブジェクトの尤度を合計した値を1.0(確率)となるように調整するSoftmax層の処理を除去し、Softmax層を利用せずに合計尤度が1.0以上となっている状態の出力テンソルに対して、尤度が一定値以上のピクセルを犬のオブジェクトとして扱うことでオブジェクトを検出できるようにしました。
DLA形式のAIモデルをVAB-5000上で実行した際の性能
以上の手順により生成したFP16に最適化されたTensorFlow Lite形式のAIモデルをTensorFlow Liteランタイムによりx86-64上で実行した際の性能と、INT8に最適化されたDLA形式のAIモデルをVAB-5000上のNeuron Runtime Helperにより実行した際の性能を以下に示します。結果から、計算量の大きなAIモデル「FCN_resnet50」であっても、モデルをINT8に最適化して、VAB-5000のCPU、GPU、APUを適切に活用することにより約3FPSで実行できることがわかりました。この結果によりVAB-5000は、低FPSでも問題のない、外観検査装置や入退室管理、映像加工(生成AI)など遅延許容な分野のアプリケーションに適していると言えます。
PlatformList NeuronHelper
PyTorchから入手できるAIモデルも活用してAMOS-9100やVAB-5000のエッジAIアプリケーションを開発しよう
本記事では、PyTorchにより定義された比較的計算量の大きなAIモデルをAMOS-9100やVAB-5000上で実行できることと、それらが適当な速度で動作することを紹介しました。本記事を通して得られたAMOS-9100とVAB-5000それぞれの特長と、推奨される最適化、計測結果から導き出すことのできる各プラットフォームが得意とするユースケースを下図に示します。本結果より、AMOS-9100はリアルタイムの推論が求められる分野に、VAB-5000は低消費電力が強く求められ、遅延を許容できる分野に適していることがわかります。
なお、本記事ではアノテーションデータを含んでいない動画を推論の入力として扱ったため、AIモデルの推論精度の評価は定性的なものとなっています。今後の記事ではアノテーションデータやラベルデータが付与された入力データを利用して、mAPやIoUといった定量的な結果もご紹介していきたいと思います。

PlatformList and Models
また、下図に本開発により計測できた推論速度をまとめます。本結果より、それぞれのプラットフォームが得意とする最適化を適用したAIモデルを活用することにより、期待されるユースケースに妥当な推論速度を達成できることがわかります。

PlatformList all
convert and eval ALL
NVIDIA TAO Toolkit、NVIDIA GPU Cloud、TensorFlow Hubで配布されるAIモデルをはじめとする幅広いAIモデルを利用することのできるAMOS-9100とVAB-5000
これまでの記事では、VAB-5000上で動作するAIアプリケーションにNVIDIA TAO Toolkit、NVIDIA GPU Cloud、TensorFlow Hubなどが提供するAIモデルを利用できることについて紹介してきましたが、本記事の内容によりVAB-5000やAMOS-9100の開発にPyTorchにより定義されたAIモデルも活用することが可能であり、より先進的なAIアプリケーションの構築にAMOS-9100やVAB-5000を利用できることがわかりました。エッジAI製品の開発に、是非VAB-5000やAMOS-9100等のプロダクトをご活用ください。なお、VIAはお客様のアプリケーションにVAB-5000かAMOS-9100のいずれが適しているかといった質問にも答えることができます。お気軽にご相談ください。