
高性能シングルボードコンピュータ「VAB-5000」と、高性能 AI エンジン搭載エッジゲートウェイ「ARTiGO A5000」は、エッジAIが求められる領域の中でも特に要求の厳しい産業用途に向けたVIAのトータルソリューションです。これらのソリューションは、エッジAIに対して高い性能を発揮するハードウェアプラットフォーム「MediaTek Genio 700 SoC」と、小さなフットプリントでAIを実行することのできるソフトウェアプラットフォーム「TensorFlow Lite」から構成されています。
ARTiGO A5000の製品情報はこちらからご確認いただけます
本記事は、MediaTek Genio 700 SoCの紹介をはじめ、AIアプリケーションを最適化する際に求められるプロセッシングユニット「MediaTek Deep Learning Accelerator(MDLA)」に関する情報や、VAB-5000に統合されたソフトウェアプラットフォームの特徴、転移学習により効率的にAIアプリケーションを開発することのできるツールキット「NVIDIA TAO Toolkit」を活用する方法について解説します。

VAB-5000
エッジAIを実現するまでのワークフロー
VAB-5000上にエッジAIを活用したアプリケーションを実装し、ハードウェアに秘められた演算リソースの能力を余すことなく引き出すためには、以下に挙げる7つの項目について理解する必要があります。
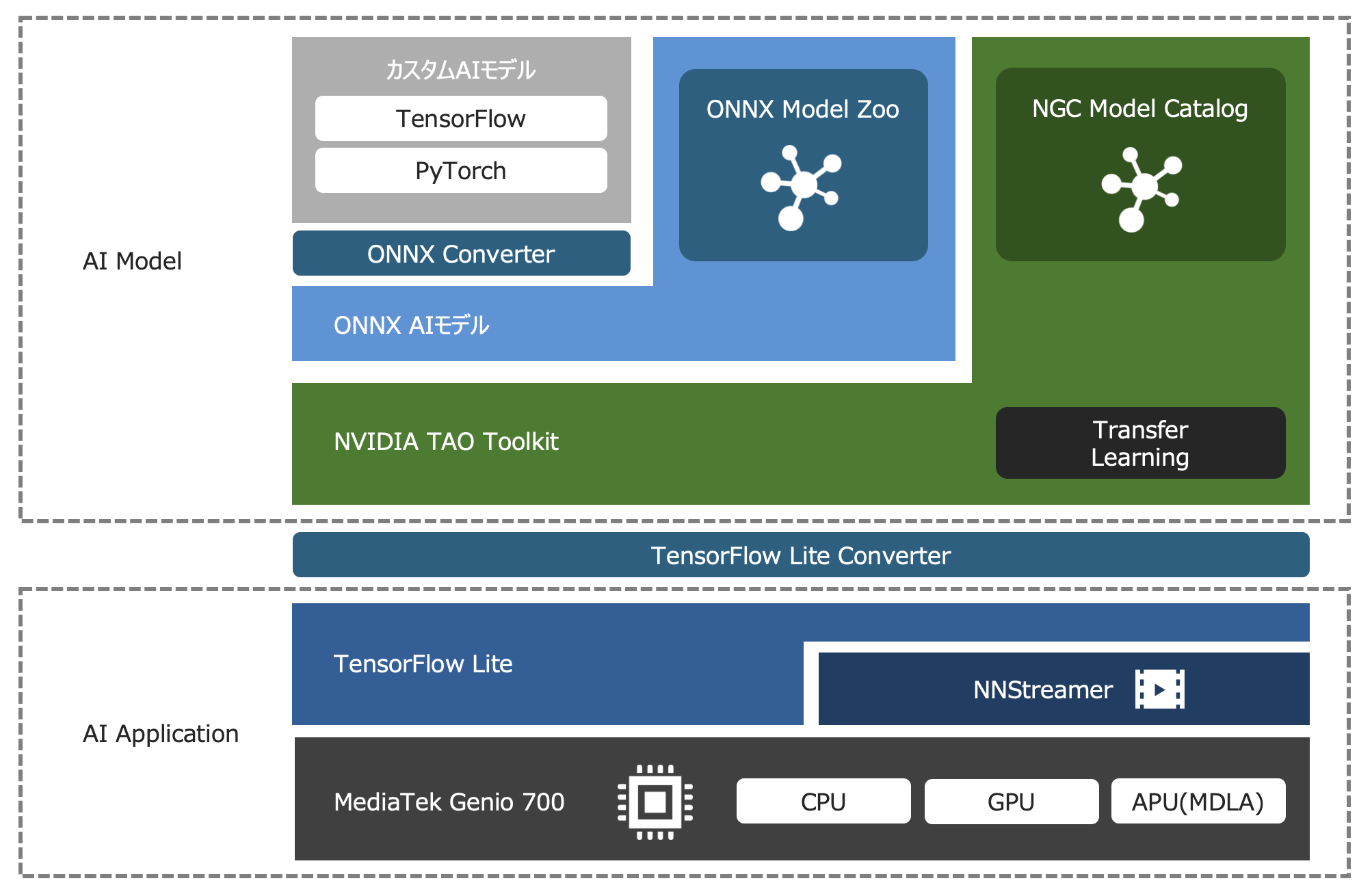
本記事では、まず、VAB-5000のMediaTek Genio 700がどのような特長を持ったSoCであるかについて紹介します。次に、SoCに内蔵されている演算リソースであるCPU・GPU・APU(MDLA)がエッジAIの実行に対してどのように機能するかについて解説します。その後、Genio 700上でAIを実行し、演算リソースを存分に活用するためのツールセット「TensorFlow Lite」について紹介します。また、TensorFlow Liteの紹介とあわせて、映像などのストリーミングデータに対してAI機能を適用できるミドルウェア「NNStreamer」についても紹介します。記事の中盤では、効率よくエッジAIを開発できるツールキット「NVIDIA TAO Toolkit」と、ツールキットにAIモデルを登録する際に利用する汎用的なAIの記述形式「ONNX」について解説します。最後に、多くのお客様がAIアプリケーションの開発に利用しているフレームワーク「TensorFlow」「PyTorch」の特徴と「ONNX」の関係について触れます。本記事を通して、お客様が実際にAIアプリケーションを開発するイメージを持っていただけたら幸いです。
VAB-5000の核である「MediaTek Genio 700 SoC」について知る
演算リソース「CPU」「GPU」「APU」について知る
AIを実行するためのツールセット「TensorFlow Lite」について知る
映像をスマートに処理できるミドルウェア「NNStreamer」について知る
効率よくエッジAIを開発できるツールキット「NVDIA TAO Toolkit」について知る
AI開発ツールの相互運用性を高めるAIモデル記述形式「ONNX」について知る
独自のAIモデルを定義できる「TensorFlow」「PyTorch」と「ONNX」の関係について知る
MediaTek Genio 700の特長
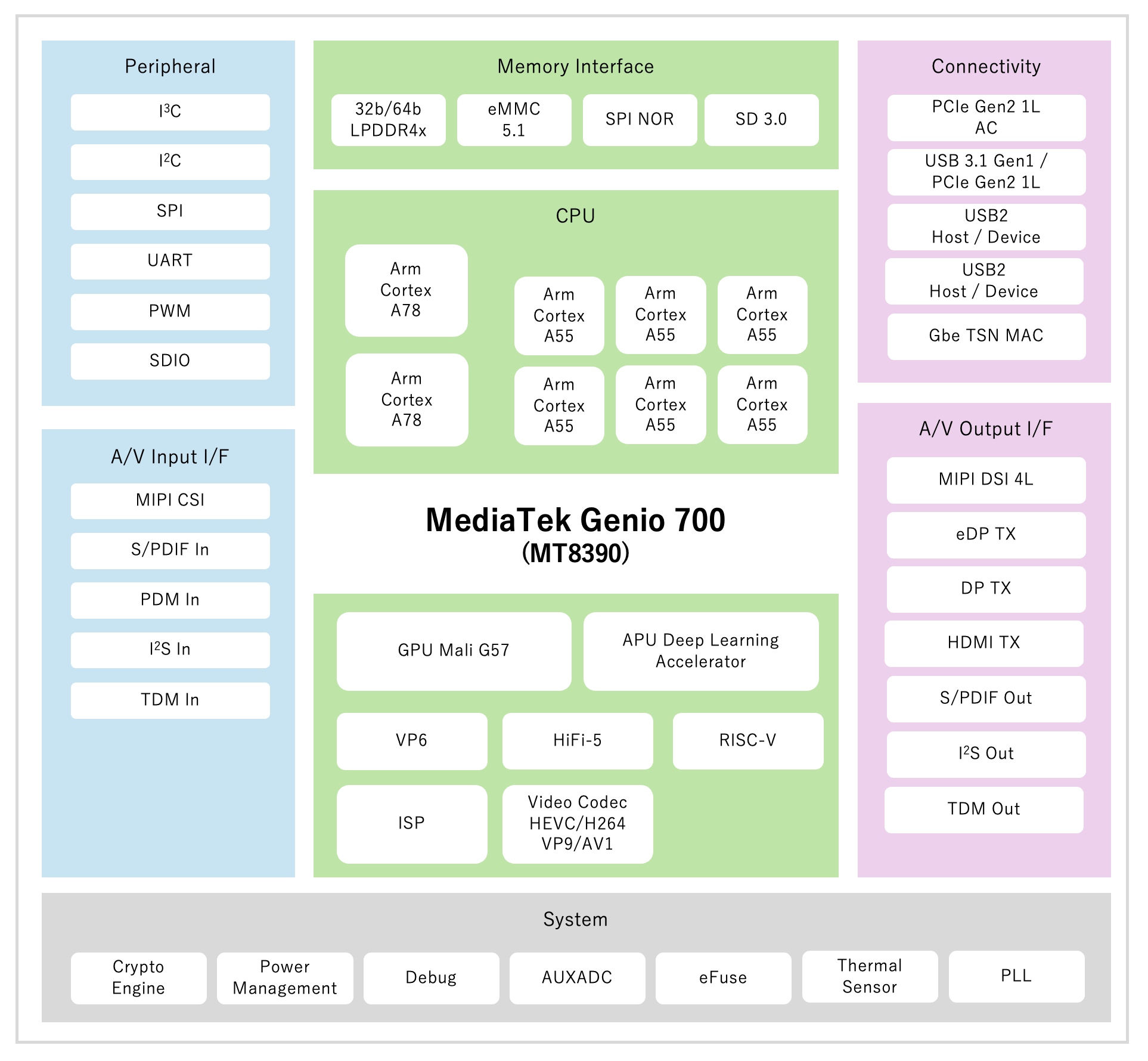
MediaTek Genio 700は、VIA VAB-5000やARTiGO A5000の核となるSoCです。Arm big.LITTLEテクノロジーにより、Arm Cortex-A78(2.2GHz)のコア2個と、Arm Cortex-A55(2.0GH)のコア6個の、合計8コアを搭載したSoCであり、ここにパワフルなGPUと、MediaTek独自のAIアクセラレータを統合することにより4.0TOPSの性能を発揮します。さらに、産業用途における厳しい要求に対応できるハイパフォーマンスを達成しながら、優れた電力効率によりエッジAIの低消費電力化に貢献することが可能です。また、豊富な演算リソースだけでなく、エッジに欠かせないペリフェラルも充実しており、Genio 700を搭載したVAB-5000は、HDMI、eDP(Embedded DisplayPort)、MIPI CSI、USB 3.1、GPIO、MicroSDカードコネクタを含む豊富な拡張オプションを提供します。ギガビットイーサネットに加え、オプションのデュアルバンドWi-Fi 6、Bluetooth 5.2、4G LTEモジュールなど多様な接続にも対応しています。なお、Genio 700はプラットフォーム統合の標準化・簡易化に関するArm SystemReady認証と、セキュリティの品質に関するArm PSA認証を取得しています。
MediaTek Genio700 SoC
MediaTek Genio 700に搭載された演算リソース
VAB-5000の核となるMediaTek Genio 700は、エッジAIを備えたアプリケーションを実行するために理想的なバランスの良い演算リソースを備えています。Genio 700の主な演算リソースには「CPU」「GPU」そしてAIのワークロードを高速に処理することのできる「APU(MDLA)」があります。AIと聞くと、GPUやAPUの演算リソースさえ搭載されていれば、高いパフォーマンスを発揮するAIアプリケーションを開発できるように思われがちですが、実はCPUも不可欠です。これはCPUが、AIアプリケーションに欠かせないSoC外のハードウェアとの連携や、ファイルアクセス、AIの推論に必須となるデータの前処理、そしてGPUやMLDAを管理する役割などを担うためです。こうした状況に応じて変化する処理は、GPUやAPUが得意としない演算であり、CPUの柔軟性が不可欠です。本節では、AIアプリケーションの実行環境を選定する際に注意しなければならないことや、各演算リソースの特徴について紹介いたします。
Genio 700を搭載したVAB-5000の製品情報はこちらからご確認いただけます
各演算リソースの特性
MediaTek Genio 700搭載されたCPU、GPU、APU(MDLA)のそれぞれが得意とする演算、処理性能、消費電力の特徴を以下の表に示します。CPUはその柔軟性により、AIアプリケーションに必要とされる様々な処理を実行することが可能であり、GPUやAPUはその演算性能と演算器の特性により、TensorFlow Lite(後述)で記述された固定的なAIの処理を高速に実行することができます。なお、最高性能で動作している状態の消費電力は、CPUに比べてGPUやAPUの方が低くなる傾向にあります。
MediaTek Genio 700に搭載されたCPU、GPU、APUについて知る(外部サイト)

CPU vs GPU vs APU
なお、MediaTek Genio 700に搭載された演算器とメモリは、下図のように結合されています。APU(MDLA)はMediaTek独自のアーキテクチャであり、CPUとGPUはArm由来のアーキテクチャです。

CPU (Arm Cortex-A78 x2 + Arm Cortex-A55 x6)
MediaTek Genio 700は、Arm big.LITTLEテクノロジーにより2種類のプロセッサーを連携させるヘテロジニアスプロセッシングアーキテクチャを採用しています。プロセッサーとしては、高い演算性能を発揮できる2.2GHzで動作するArm Cortex-A78を2コア、優れた低消費電力を誇る2.0GHzで動作するArm Cortex-A55を6コア搭載しています。2種類のコアを連携させることにより、スマートフォンやタブレットをはじめとする多くのエッジのアプリケーションにおいて発生する、高負荷と低負荷が繰り返されるダイナミックな使用パターンに対して優れた電力特性を発揮します。AIアプリケーションにおけるCPUは、AIで主となる演算器であるGPUやAPUを制御する役割と、ペリフェラルやファイルシステムと連携してAIで処理するデータを準備する役割を担います。そのため、AIアプリケーション実行中のCPU使用率は高い傾向となり、高い演算性能を誇るArm Cortex-A78はなくてはならない存在です。
なお、Arm Cortex-A78とArm Cortex-A55にはSIMD演算のできるNEONと呼ばれる演算器が搭載されており、GPUやAPUと比較すると性能は高くありませんが、CPU単体でもAIアプリケーションを実行することが可能です。詳細については後述する「デリゲート」の節をご参照ください。
Arm CPUの特徴とAIアプリケーションにおける役割について知る(外部サイト)
GPU (Arm Mali-G57 MC3)
MediaTek Genio 700には、GPUとしてArm Mali-G57が搭載されています。Arm Mali-G57は、現在注目が集まっているARやVRといったアプリケーションにも対応できる優れたレンダリング性能を有しています。エッジAIの領域では映像を扱うアプリケーションも多く、Arm Mali-G57は、こうした高品質なグラフィックが求められるアプリケーションの実現を可能にします。なお、Mali-G57はAIのワークロードを加速できる機能も備えていますが、Genio 700にはAIに対して優れた演算性能と低消費電力の特性をあわせ持つAPUが搭載されていますので、AIをGPU上で実行することはあまり無いと思われます。そのため、VAB-5000ではPC等で採用されているGPGPU(General-Purpose computing on Graphics Processing Units)のアーキテクチャで課題となる、AIの処理がGPUを占有してしまい、グラフィックの処理を妨害してしまうような状況に陥ることはまずありません。
Genio 700に搭載されたGPU Mali-G57について知る(外部サイト)

MDLA (MediaTek Deep Learning Accelerator) / APU (AI Processing Unit)
MDLA (MediaTek Deep Learning Accelerator)は、スマートフォンやAI/IoT、スマートTVに必要とされる様々なエッジAIを効率的に実行できる演算ユニット(APU:AI Processing Unit)です。エッジAIで採用されている畳み込みニューラルネットワーク(CNN)や、リカレントニューラルネットワーク(RNN)、長期短期記憶ネットワークモデル(LSTM)、Transformerによる双方向のエンコード表現(BERT)など、あらゆるネットワークに対応しており、これらを高速に実行することができます。ニューラルネットワークに頻出する、活性化関数、要素ごとの演算、プーリング層などもAPUにより高速に処理することが可能です。なお、MediaTek Genio 700に搭載されたAPUは、エネルギー効率の高いMultiply-Accumulate(MAC)アーキテクチャを採用することにより、低遅延と低消費電力も実現します。
MediaTek Genio 700のAPUはデータタイプとしてINT8/INT16/FP16に対応しており、幅広く利用されているAIフレームワーク「TensorFlow Lite」により量子化されたネットワークと高い親和性があります。なおAPUは、Linux OSとAndroid OSの双方からTensorFlow LiteのAPIを介して利用可能であり、MediaTekの提供するNeuroPilot SDKやNeuron SDK等の開発環境を活用することにより、さらなるチューニングも可能です。
高速なAPUを搭載したVAB-5000はこちらから購入いただけます
MediaTekの提供するAI向けソリューション(外部サイト)

MVPU (MediaTek Vision Processing Unit)
VAB-5000よりもリーズナブルなソリューションであるVIAのVAB-3000やARTiGO A3000のハードウェアは、MediaTek Genio 350 SoCを核として構成されています。Genio 350にはMDLAが搭載されていませんが、MDLAに代わってニューラルネットワークを高速に実行するためにアクセラレータとして「MVPU(MediaTek Vision Processing Unit)」を利用することができます。MVPUは、コンピュータービジョン (CV) はもちろん、ニューラル ネットワーク (NN) アプリケーション向けにも最適化された汎用 DSPです。MVPUを活用することにより、エッジAIの扱う「写真」「ビデオ映像」「ビデオストリーム」などを高速かつ低消費電力で処理することができます。
TensorFlow Lite:Genio 700上でAIを実行するためのツールセット
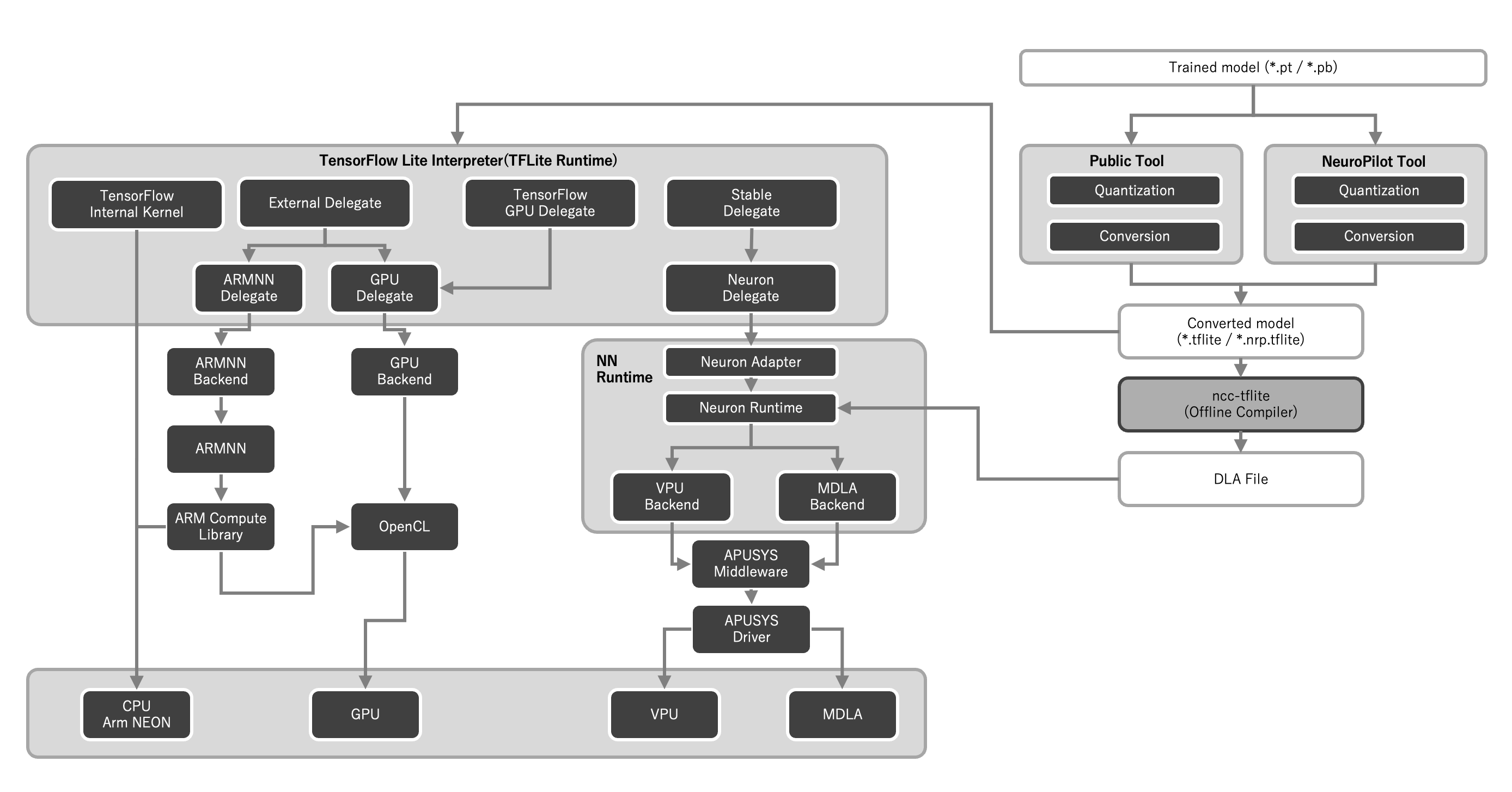
VIAのシングルボードコンピュータVAB-5000に搭載されているMediaTek Genio 700は、エッジAIの開発・実行プラットフォームとしてTensorFlow Liteツールセットをサポートしています。TensorFlow Liteツールセットを利用することにより、エッジAIを実行することはもちろん、Genio 700向けの開発環境としてAIモデルの量子化、プルーニング、クラスタリングによりGenio 700のAPU(MDLA)に最適化されたコンパクトなAIモデルを生成し、エッジの限られたハードウェアリソースの中でお客様のAIアプリケーションの魅力を最大限に引き出すことが可能です。TensorFlow Liteにより実行できるAIモデルは、AIの開発に広く利用されている「TensorFlow」をはじめ、研究分野で人気の高い「PyTorch」や、AIツール間の相互運用性を高めるためのモデル記述形式「ONNX」から、TensorFlow LiteツールセットやNeuroPilot SDKにより生成することができます。
MediaTek Genio 700のサポートするTensorFlow Liteツールセットの概要(外部サイト)
TFLite_on_Genio700_Overview
モデルの最適化:エッジ向けにAIモデルの冗長性や類似性を取り除き軽量化する
TensorFlow Liteツールセットを活用することにより、演算リソースの限られたエッジデバイス上でも実行できるようにAIモデルを最適化し、コンパクトで応答性の優れたAIアプリケーションを構築することが可能となります。TensorFlow Liteツールセットを使うことにより、ニューラルネットワークに対して「量子化」「プルーニング」「クラスタリング」といった最適化を適用することができます。
TensorFlow Liteツールセットによる最適化(外部サイト)
量子化
まず、AIの最適化で代表的な「量子化」は、モデルのパラメータを表すために使用される数値の精度を下げることにより、高速化とAIモデルの容量削減を促進する技術です。一般的にTensorFlowやPyTorchの扱うAIモデルの精度は32 ビットの浮動小数点数(FP32)ですが、量子化はこれらのパラメータをINT8/INT16/FP16のパラメータへと変換し、AIモデルを圧縮します。これにより、1回のSIMD命令で処理することのできるデータ数を増加させることはもちろん、INT8/INT16/FP16の演算器のみを持ちFP32に対応していないAPU(MDLA)上でAIモデルを実行することが可能になります。なお、量子化による最適化はニューラルネットワーク内の重み値の精度が下がることから、推論結果の精度を確認しながらバランスよく最適化を行う必要があります
プルーニング
次の最適化手法である「プルーニング」は、AIモデルを形成するグラフのうち、推論への影響の少ない重み値を0として、AIモデルを構成するニューロン間の連携を切断(枝刈り)することにより、AIモデルの演算量とモデルサイズを縮小する技術です。プルーニングによる最適化を行う場合、AIモデルの精度を保つため、まずAIモデルの学習を実行し、そこで得られた重み値に応じてプルーニングを行い、プルーニングしたモデルに対して再度学習を行うことが一般的です。
クラスタリング
最後に紹介する最適化手法「クラスタリング」はAIモデルを構成する複数のレイヤー間の類似性に着目し、重み値(weight)の似ているレイヤーを選定し、それらのレイヤーをグループ化して重み値を共通化することによりAIモデルの容量を最適化する技術です。クラスタリングにより、AIモデルが保持する重み値の数が減り、ニューラルネットワークの複雑さが軽減されます。
TensorFlow Liteによる最適化の効果
以上に挙げたTensorFlow LiteによるAIモデルの最適化機能により、AIモデルの容量を小さくすることが可能です。容量の小さなAIモデルは、ストレージの消費量を削減し、ストレージからメモリへの展開速度を向上させ、実行時のRAM消費量を軽減することに寄与します。これにより、VAB-5000に搭載された4GB LPDDR RAMを効率的に活用し、ストレスのない実行速度で動作するAIアプリケーションを実現することができます。また、最適化は推論に必要な計算量も減らすことができるため、AIモデルへデータを入力してから結果が出力されるまでのレイテンシを短縮し、消費電力の低減にも貢献します。
デリゲート:TensorFlow LiteのAIモデルに最適な演算リソースを割り当てる
TensorFlow Liteの実行環境では、デリゲートと呼ばれるハードウェアドライバを介すことにより、ニューラルネットワークをGPUやAPU(MDLA、MVPU)上で実行することができます。MediaTek Genio 700では、指定するデリゲートの内容により、AIモデルをCPU単体で実行するか、CPUとGPUにより実行するか、APUを利用するか、選択可能です。デリゲートを正しく利用することで、演算リソースの特長を活かした、高速で電力効率の良いAIアプリケーションを開発することができます。
Genio 700の演算リソースを活用するためのデリゲートの記述例(C++)
高速なAPUを搭載したVAB-5000はこちらから購入いただけます
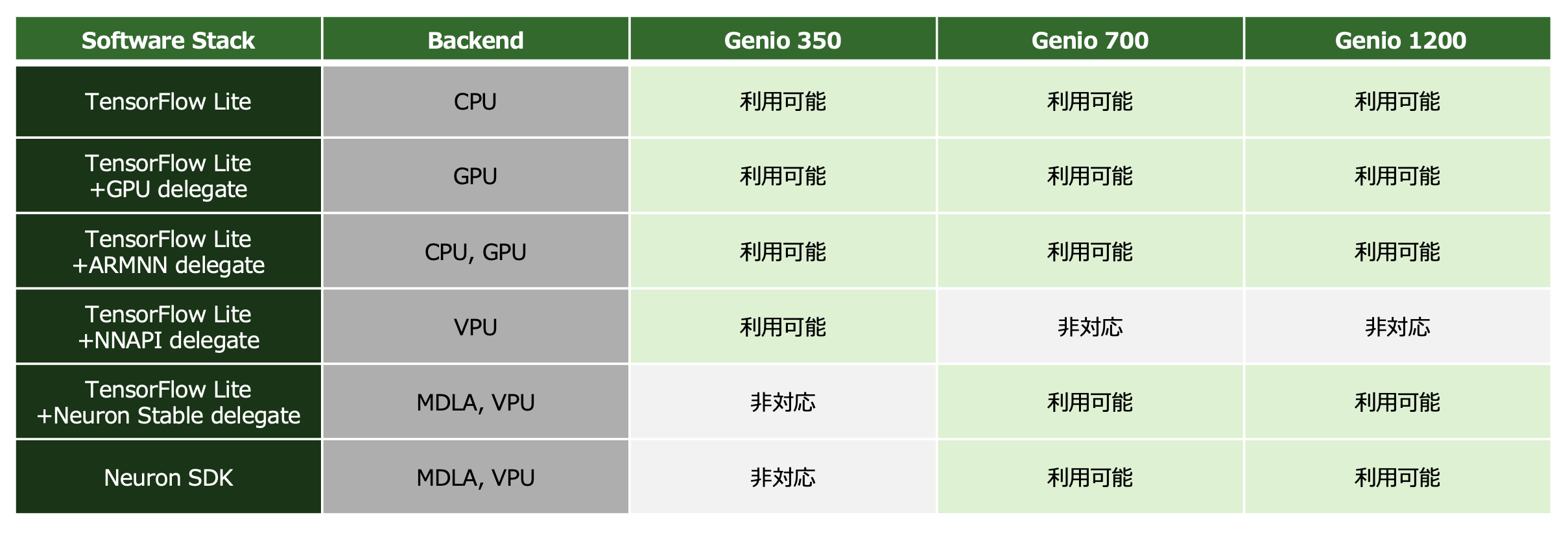
なお、APU(MDLA)はINT8/INT16/FP16の演算器のみを搭載しており、FP32には対応していません。そのため、APUデリゲートを利用する場合は、AIモデルをデプロイする前に、FP32の演算が含まれないよう、TensorFlow Liteツールセットを利用してすべての演算がFP16を使うように量子化しておく必要があります。
また、デリゲートを指定してもGPUやAPUに適していない演算はCPU上で実行されますので、APUを使うデリゲートを指定したとしてもCPUの演算リソースには余裕を持たせておいた方が良いでしょう。
Neuron SDK: AIの各処理を最適なハードウェアに結びつけるためのSDK
MediaTekの提供するツールセットである「Neuron SDK」は、お客様独自のAIモデルをMediaTek Genio 700向けにコンパイルし、TensorFlow LiteでAIモデルを実行するよりもさらに効率的にMediaTekのAPU(MDLA)を活用できるAIアプリケーションの開発を支援します。TensorFlow Lite以上の性能を求めるお客様におすすめのソリューションです。Neuron SDKは以下の4つの機能を備えています。
MediaTekのNeuron SDKについて知る(外部サイト)
Neuron Compiler:TensorFlow Lite形式のAIモデルを、Neuron SDK専用のDeep Learning Archive(DLA)形式に変換するオフラインのニューラルネットワークモデルコンパイラ (ncc-tflite) です。
Neuron Runtime:指定したDLAファイルを実行し、結果を取得できるコマンドラインツール (neuronrt) です。
Neuron Runtime API:Neuron Runtime APIは、ユーザーのC++アプリケーションから、コンパイルされたDLAファイルの読み書きと実行をサポートするAPIを提供します。
Neuron Profiler:Neuron ProfilerはNeuron Runtimeに同梱されたパフォーマンスプロファイリングツールです。Neuron Profilerを使うことにより、Neuron SDKにより最適化したAIモデルを評価することができます。

NeuronSDK
NNStreamer:ストリーミング映像向けAIの実行に最適なミドルウェア
NNStreamerは、映像や音声などのストリーミングデータに対して、TensorFlow Liteフレームワークに従って記述されたAIモデルによる処理を加えることのできるミドルウェアです。MediaTek Genio 700向けのLinuxに同梱されているNNStreamerは、TensorFlow LiteのAIモデルを呼び出す際、自動的にAPU(MDLA)を使うデリゲートを付与するため、NNStreamerを利用するだけで演算リソースを十分に活用したストリーミングを処理するアプリケーションを開発することができます。なお、NNStreamerは映像や音声のストリーミングデータを処理するためのミドルウェア「GStreamer」をベースとしてミドルウェアです。
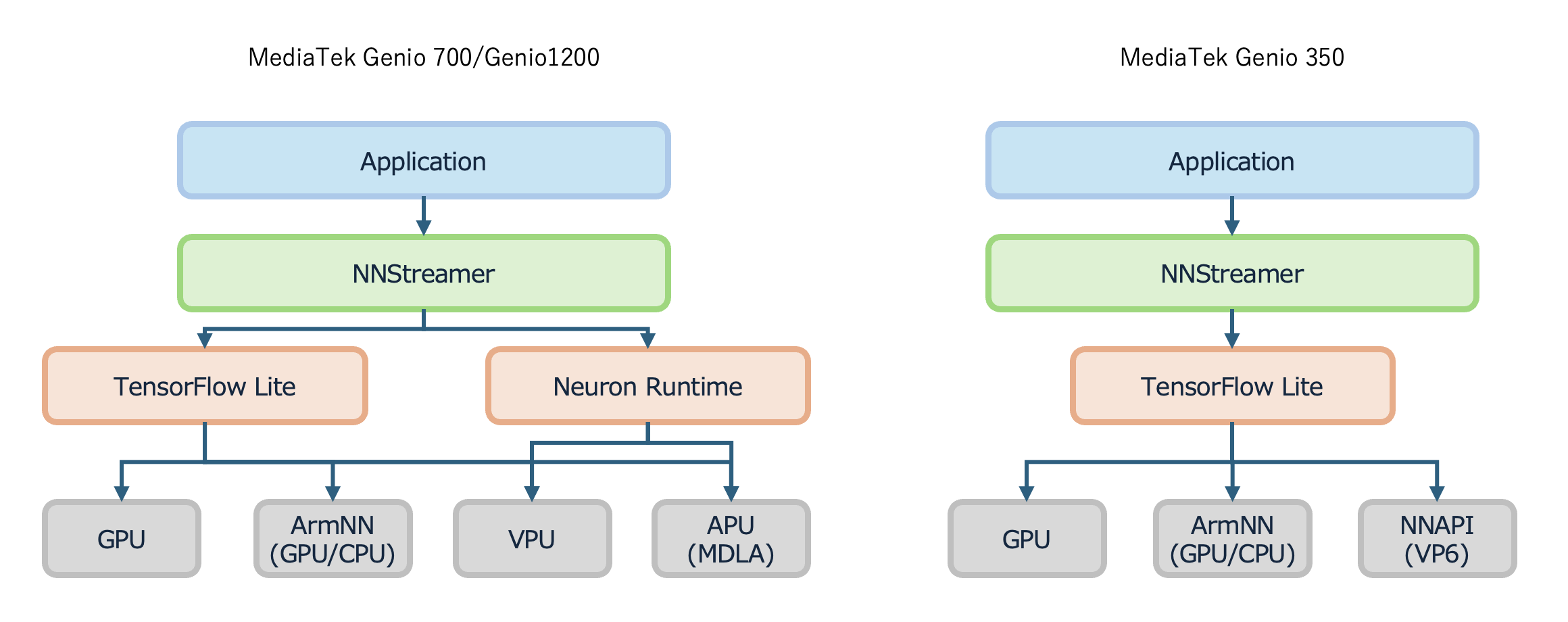
Delegate_in_NNStreamer
NNStreamerの利用例
以下にNNStreamerとTensorFlow Liteを連携させるスクリプトの例を紹介します。NNStreamerは、gst-launch-1.0コマンドの引数に、利用するカメラデバイスや、映像フォーマットの選択、映像の処理方法などを記述することにより、ストリーミングデータに対する処理を決定します。そして、このスクリプトの中にTensorFlow Lite形式のモデル(*.tflite)やAIモデルの実行に必要となるラベルデータ等のファイルを指定することで、AIモデルを活用したストリーミングアプリケーションを構築することができます。
NNStreamerとTensorFlow Liteを連携させるスクリプトの例(外部サイト)
NVIDIA TAO Toolkit:転移学習によりAIアプリケーションを効率的に開発する
それでは、ここまでに紹介した演算リソースやAIフレームワーク上で動作するAIモデルは、実際、どのように入手すればよいでしょうか。そのひとつの解がNVIDIA TAO Toolkitの利用と、NGC(NVIDIA GPU Cloud) Model Catalogの活用です。NVIDIA TAO ToolkitはMediaTek NeuroPilot SDKと統合されたAIの開発プラットフォームであり、テンプレート化されたAIモデルの入手はもちろん、AIモデルのT(Train)、A(Adapt)、O(Optimize)を簡素化し、デプロイを加速します。NVIDIA TAO Toolkitを利用することにより、コンピュータビジョンをもとより、自然言語処理や音声認識など、エッジAIに求められる様々なAIモデルをNGC Model CatalogやONNX Model Zoo(後述)から手早く入手できるため、お客様はAIアプリケーションを簡単に構築することができます。NVIDIA TAO Toolkitにより入手できるAIモデルはいずれも学習済みのものであるため、お客様のフィールドに合わせたわずかな学習用データセットを準備するだけで、転移学習によりお客様のアプリケーションに最適なAIモデルを開発することができます。そして、NVIDIA TAO Toolkitの最適化機能と、MediaTek NeuroPilot SDKやTensorFlow Liteツールセットを組み合わせることにより、MediaTek Genio 700のAPU(MDLA)の性能を最大限に活かすことのできる実行用バイナリを生成可能です。なお、NVIDIA TAO Toolkitは、TensorFlowやPyTorchなどのAI開発プラットフォームと、Dockerによるコンテナ技術、GPUによる高速化技術を組み合わせたツールキットであり、ひとつのワークステーションの上で複数のAIモデルの開発を、互いに干渉することなく並行して進めることが可能です
NVIDIA TAO Toolkit公式サイト(外部サイト)
NVIDIA TAO Toolkitに対応したMediaTek Genio 700搭載のコンピューティングボードはこちらから購入いただけます
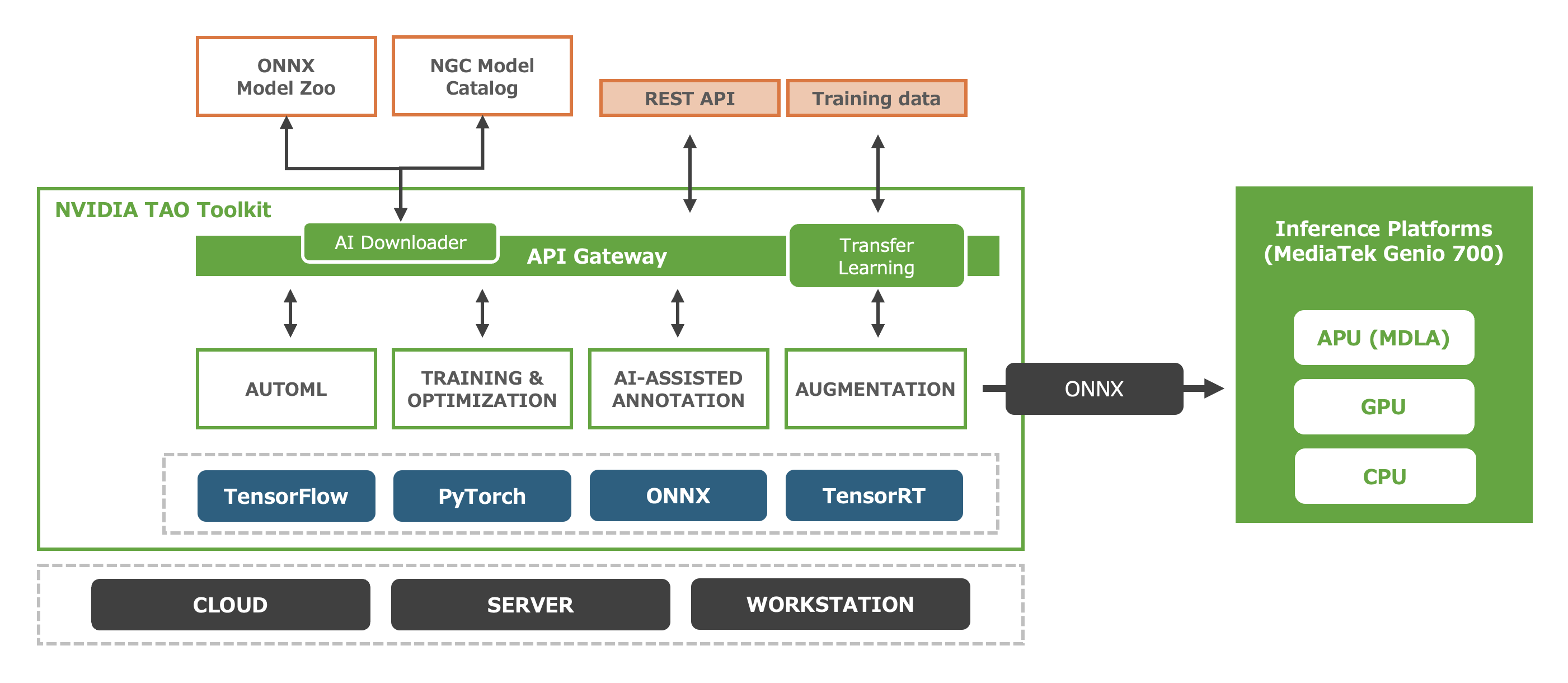
NVIDA_TAO_Overview
NVIDIA TAO Toolkitにて利用できるAIモデル
以下に、NVIDIA TAO ToolkitやNGC Model Catalogから簡単に入手することのできるAIモデルの一例を挙げます。いずれもエッジAIの分野にて注目されているAIモデルであり、NVIDIA TAO ToolkitとMediaTek NeuroPilot SDK、TensorFlow Liteツールセットを利用することにより、これらのAIモデルをMediaTek Genio 700に最適化された形へと変換し、AIアプリケーションへ組み込むことが可能です。
NVIDIA TAOのモデルをMediaTek Genio 700上で実行するためのチュートリアル
人物検出:People Detection
ナンバープレート検出:License Plate Detection
姿勢推定:Body Pose Estimation
リテール向けの物体認識:Retail Object Recognition
人物の追跡:People Re-identification
行動認識:Action Recognition 2D RGB
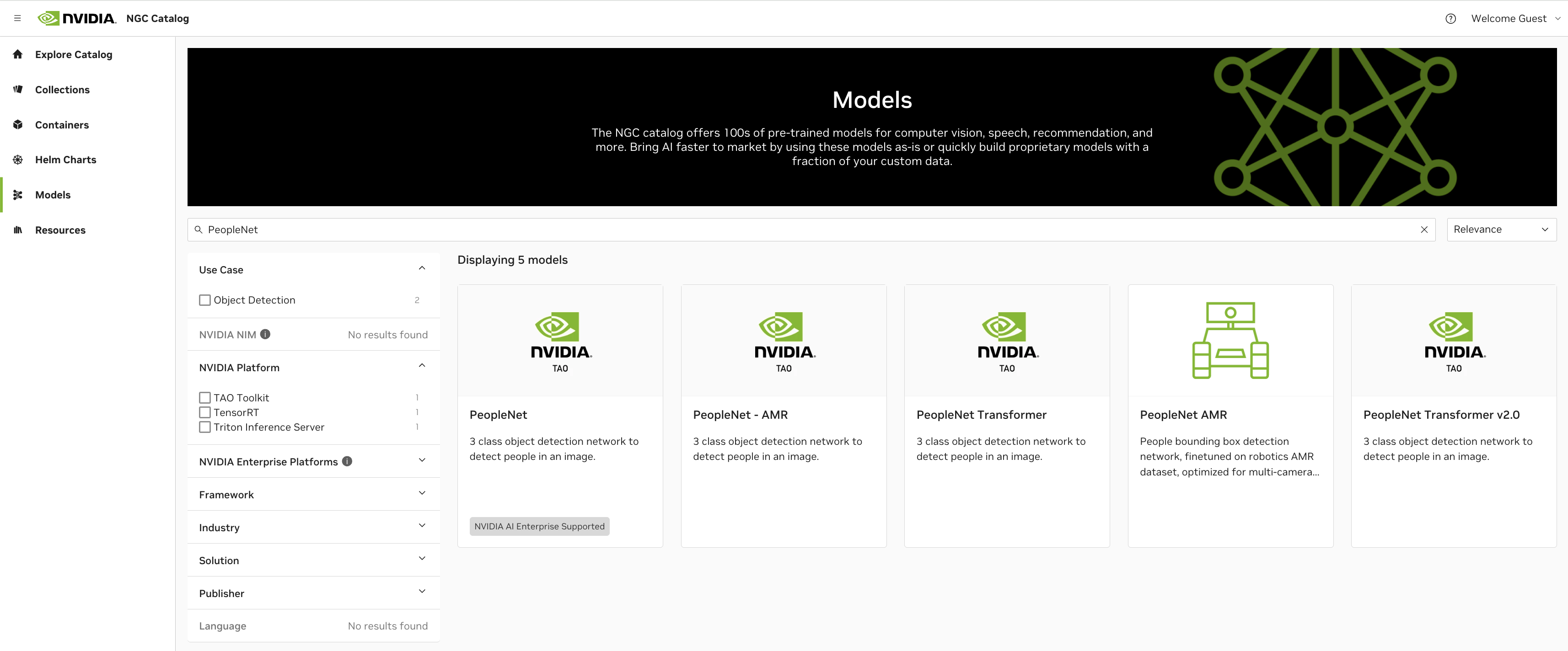
NGCModelCatalog_peoplenet
ONNX:開発ツール間の相互運用性を高めるAIモデルの記述形式
ONNX(Open Neural Network Exchange)はML(機械学習)やAIのモデルを表現するためのオープンソースのフォーマットです。ONNX形式でAIモデルを記述することにより、NVIDIA TAO Toolkitをはじめとする、数多くのAIフレームワークを連携させることが可能となります。ONNX形式で記述されたAIモデルはTensorFlow Lite形式のAIモデルにも変換できることから、ONNX形式を介することにより、あらゆるAIモデルをMediaTek Genio 700上に移植することができます。さらにONNXのポータルサイト「ONNX Model Zoo」では、ONNX形式で記述されている学習済みのAIモデルを簡単に入手することが可能です。もちろんこれらのAIモデルは、NVIDIA TAO Toolkitを活用してお客様独自の学習用データセットにより転移学習を加えることで、お客様のAIアプリケーションに最適化することが可能です。

ONNX_model_zoo_ScreenShot
AIモデルの開発に広く利用されているフレームワークの紹介
エッジAIを開発できるNVIDIA TAO Toolkitは、AIモデルの定義や学習、その評価に「TensorFlow」や「PyTorch」フレームワークを利用しています。これらのAIフレームワークは複雑な機能を多数備えているため、サイズが大きく、エッジ上でAIを実行する際には利用できませんが、AIモデルを開発する際に頻出するフレームワークであるため、ここで紹介します。
TensorFlow / Keras API
TensorFlowは、AIの開発からデプロイ、実行までをシームレスにサポートすることのできるAIフレームワークです。AIモデルを簡単に記述できるように、複数の抽象化レベルを提供しており、手早い開発からアドバンスドなチューニングまで、ニーズに合わせて最適なAPIを選択可能です。特に、高レベルの Keras API は非常に直感的なインタフェースを多数提供していることから、ML/AIの開発経験があまりない方も安心して、手早く開発に着手いただけます。また、TensorFlowはML/AIの開発に広く利用されているPython言語への対応はもちろん、C++をはじめとする多くの開発言語をサポートしており、それぞれに対してライブラリを提供しています。これにより、使用する言語やプラットフォームに関係なく、サーバー、エッジデバイス、ウェブといった、あらゆるシーンで活躍できるAIモデルを開発することができます。
PyTorch
PyTorchは、Pythonのプラットフォーム上で動作するAIモデルを効率的に開発することのできるプラットフォームです。研究開発向けとして利用され始めたAIプラットフォームですが、AIモデルを簡単に記述できることや、少しの労力で高度なアルゴリズムを実装できる手軽さから、研究分野を超えて産業分野においても幅広く利用されるようになっています。デプロイのしやすさも魅力のひとつであり、Python開発環境やC++開発環境にてPyTorchのライブラリを利用できることはもちろん、開発したAIモデルを簡単にONNX形式へと変換することが可能です。
AIモデルをONNX形式へと変換しNVIDIA TAO Toolkitで利用する
上記で紹介したTensorFlowやPyTorchを利用して開発したAIモデルは、TensorFlow-to-ONNX(tf2onnx)ツールセットや、PyTorchに内蔵されたエクスポート機能などにより、簡単にONNX形式のAIモデルへと変換することが可能です。ONNX形式に変換することにより、エッジAIにも広く利用されているAIの実行プラットフォーム「ONNX runtime」を利用できるようになるため、エッジへのデプロイがより簡単になります。また、学術論文等で紹介されている最新のAIモデルはPyTorchで実装されていることが多いですが、ONNX形式に変換することによりNVIDIA TAO Toolkitと連携し、発表されたばかりの最新のアルゴリズムを備えたAIモデルをNVIDIA TAO Toolkit上で開発することが可能となります。
PyTorchのAIモデルをONNX形式へと変換する方法(外部サイト)
TensorFlowのAIモデルをONNX形式へと変換する方法(外部サイト)
MediaTek NeuroPilot SDK:さらなるチューニングに向けたSDK
MediaTekは、MediaTek Genio 700向けにTensorFlow Lite以上のチューニングを可能とするSDKとして「MediaTek NeuroPilot SDK」を提供しています。先に挙げたNeuron SDKも、NeuroPilot SDKの一部です。NeuroPilot SDKはGenio向けに開発されたSDKであることから、APU(MDLA)の性能をフルに引き出したAIアプリケーションの開発を強力に支援することができます。なお、NeuroPilot SDKを用いた開発方法をはじめ、ツールの詳細について確認するためには専用のMediaTekのライセンスが必要となります。ご興味のあるお客様は、別途下記のフォームよりお問い合わせください。
VAB-5000で利用できるMediaTek NeuroPilot SDKの詳細についてはお問い合わせください
リッチなハードウェアと柔軟なソフトウェアプラットフォームではじめる AIアプリケーション開発
以上が、MediaTek Genio 700を核としたVAB-5000を使ってエッジAIアプリケーションを開発する方法となります。NVIDIA TAO Toolkitや、その他、TensorFlowやPyTorchなどのAIフレームワークを利用して定義したAIモデルをONNX形式で書き出し、ONNX形式からTensorFlow Lite形式へと変換。実行時にデリゲートを指定することにより、Genio 700の演算リソースを十分に活かしたAIアプリケーションを構築可能です。こうしたAIモデルの開発フローは、開発環境さえ構築してしまえば、以降はツールのアシストにより手軽に利用することができます。是非一度、VAB-5000でAIアプリケーションの開発をお試しください。