
- VAB-5000を支えるMediaTek Genio 700の特徴
- VAB-5000にDebian OSをインストールする
- AIモデルをDLA形式に変換する
- メインストリーム向けのVAB-5000とハイエンド向けのNVIDIA Jetson Orin NXを搭載したAMOS-9100の比較
- AMOS-9100/AMOS-9000における量子化

infer_peoplenet_parade_no_optim
VAB-5000 vs AMOS-9100 AI対決
VAB-5000 vs AMOS-9100
お忙しい方向けに、このページに掲載されているVIA VAB-5000とAMOS-9100の比較情報を、短時間でご理解いただけるよう音声で要約・解説します。通勤中や少しの休憩時間にご活用いただき、AI開発プロジェクトのヒントとしてお役立てください。
聴きどころ
シンプルな検出はAMOS-9100が高速。複雑なシーンではAMOS-9100がより多くの人物を安定検出しました。
コスト効率を重視。介護見守りや入退室確認など、比較的軽いAI処理に最適です。
高速処理と高精度を両立。工場ロボットの衝突回避、複雑な交通環境での検出追跡に強みを発揮します。
MDLAをPythonコードから直接制御できるVIA独自ツール。開発の複雑さを減らし、効率的なAIアプリ構築を支援します。
アプリの要求(速度・精度・コスト)に応じ、単なるスペックではなく、プラットフォームと最適化戦略を賢く選ぶことが重要です。
VAB-5000を支えるMediaTek Genio 700の特徴
VIAのシングルボードコンピュータVAB-5000やゲートウェイ製品であるARTiGO A5000は、MediaTek Genio 700 SoCを核として構築されたエッジAI向けのソリューションです。Genio 700には、合計8個のCPU(2x [email protected]、6x [email protected])と、GPUのMali-G57、APUのMDLA3.0が搭載されています。これらの演算器により低消費電力でありながら、実に4.0TOPSの演算性能を達成し、この優れた演算性能により、これまでエッジには導入が困難とされてきた複雑なAIモデルを実行することができます。また、Genio 700は得意とする演算が異なるCPU・GPU・MDLAを組み合わせることにより、高精度なモデルに欠かせない倍精度の浮動小数点数から、効率的にSIMD演算器を使うことのできる単精度の浮動小数点数や8bit/16bitの整数まで、多くのデータタイプを利用したAIモデルをサポートしています。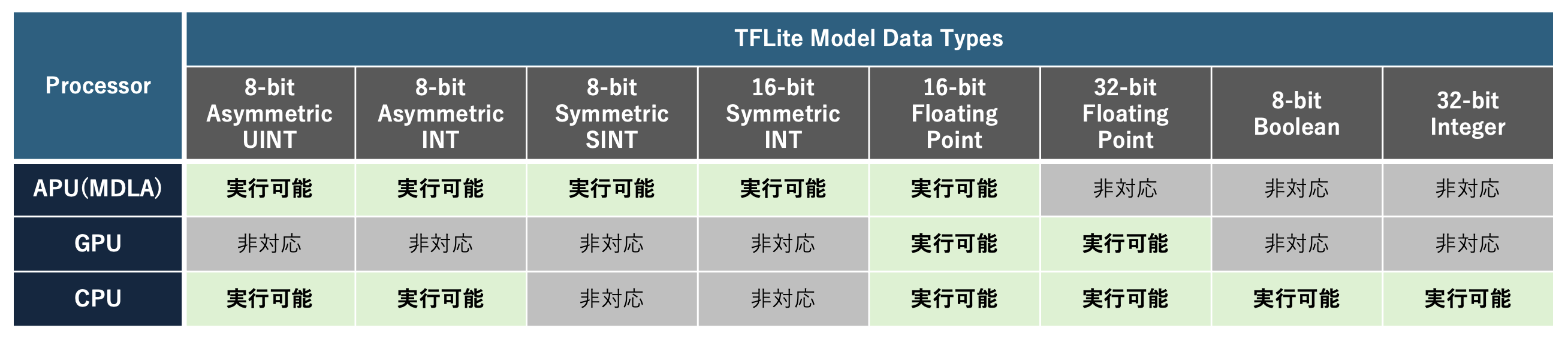
MDLA-GPU-CPU-map
VAB-5000にDebian OSをインストールする
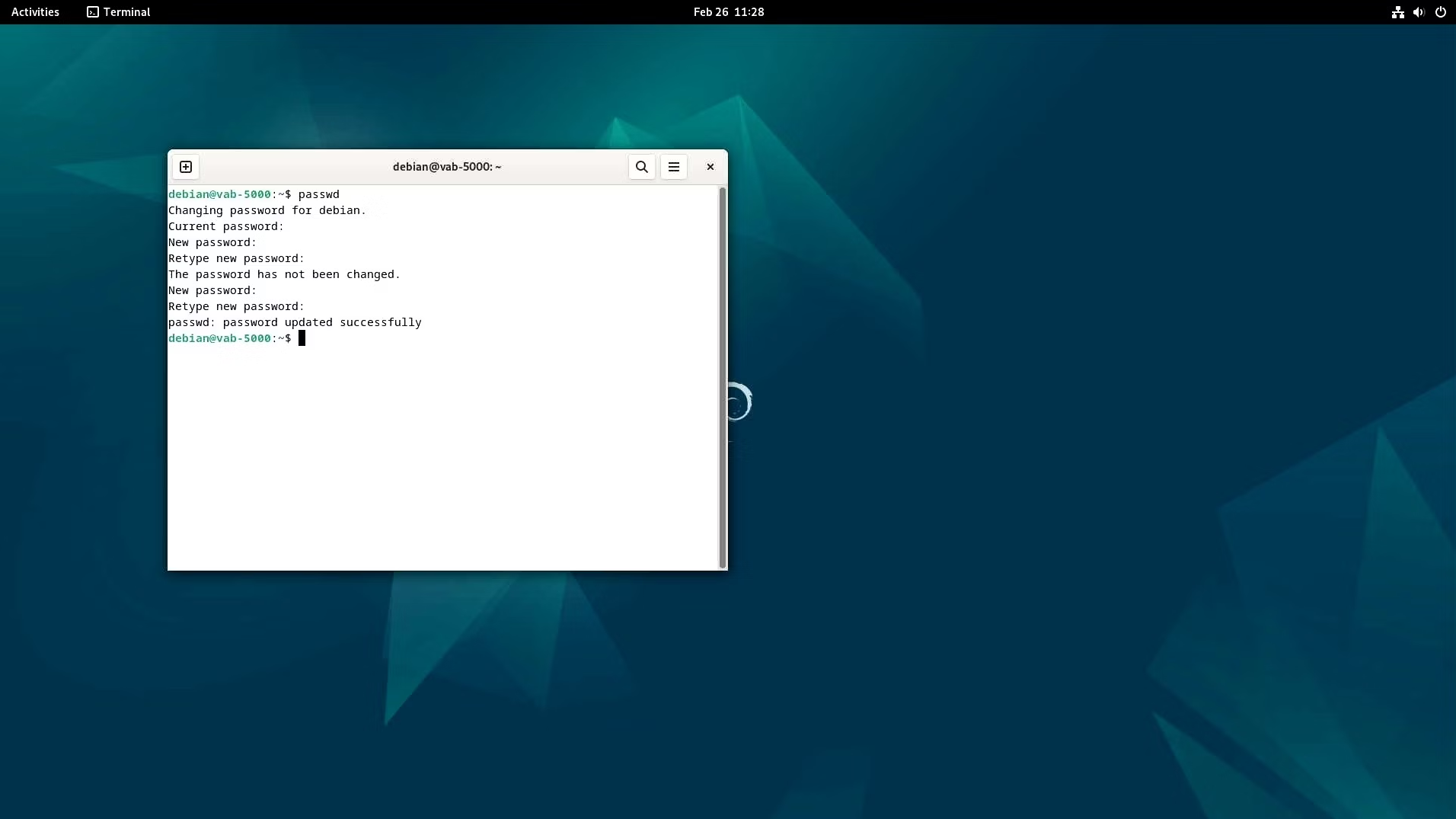
VAB-5000はOSとして、高いカスタマイズ性を備えたYocto Linux(組み込み機器やIoT向けに自社専用のLinuxディストリビューションを開発できるOS生成ツール)と、産業用Raspberry Piを中心に広く利用されているDebian OSに対応しています。しかし、MediaTek社の提供するMDLAを制御するためのミドルウェアは、2025年3月現在、Yocto Linux向けのみに提供されており、MDLAを利用する際には、産業用Raspberry Pi等で広く利用されているDebian OSを選択することができない状況にあります。この課題をいち早く解決するためにVIAはDebian OS上でもMDLAを制御できるミドルウェア「VIA Neuron Runtime Helper」を開発しました。Neuron Runtime HelperはPythonパッケージであり、開発者はPythonのソースコードからMDLAを制御することができます。産業用Raspberry PiやUbuntu など、一般的なLinux OSを利用した経験があれば、すぐにVAB-5000の優れたパフォーマンスを活かしたML/AIのアプリケーションをPythonのみで実装することが可能です。本節では、Neuron Runtime Helperの利用方法について紹介する前に、VAB-5000上にDebian OSをインストールする手順について解説します。VAB-5000にOSを書き込むためのホストPCをセットアップする
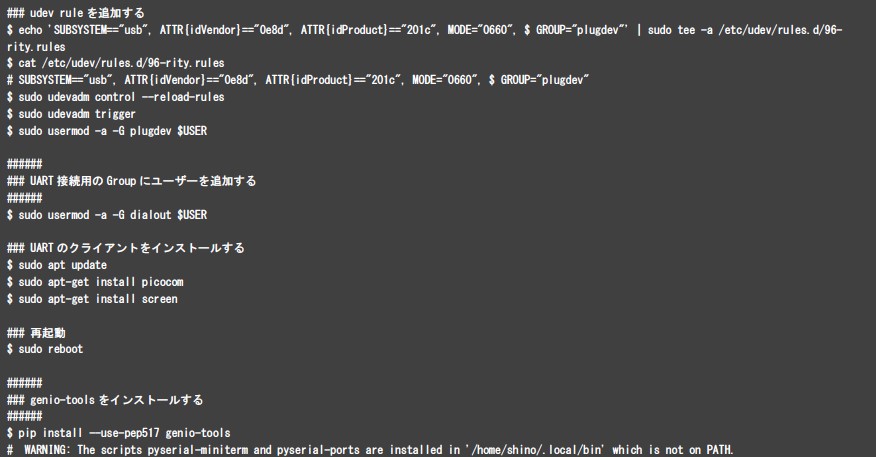
まず、VAB-5000にDebian OSを書き込むためのホストPCをセットアップします。ホストPCのセットアップ手順は、MediaTekのWebサイトにて公開されておりますので、そちらをご参照ください。 Setup Build Environment (Linux) Setup Tool Environment (Linux) 以下は、Ubuntu 22.04 LTSをホストPCとして選択した場合のセットアップの一例です。はじめに、OSを書き込むためのツールが必要とするパッケージをインストールします。次に、VAB-5000と接続するためのツールをインストールし、USBドライバの設定を行います。最後に、OSをVAB-5000へ書き込むためのgenio-toolsをインストールすれば、ホストPCの準備は完了です。


Debian 12 EVKをVAB-5000に書き込む
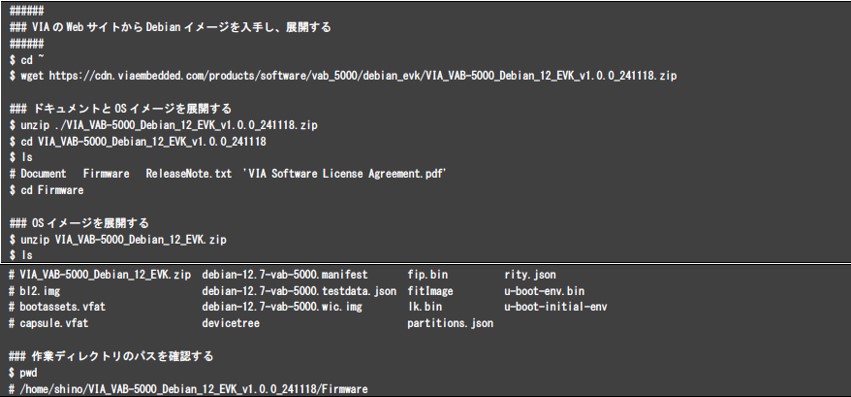
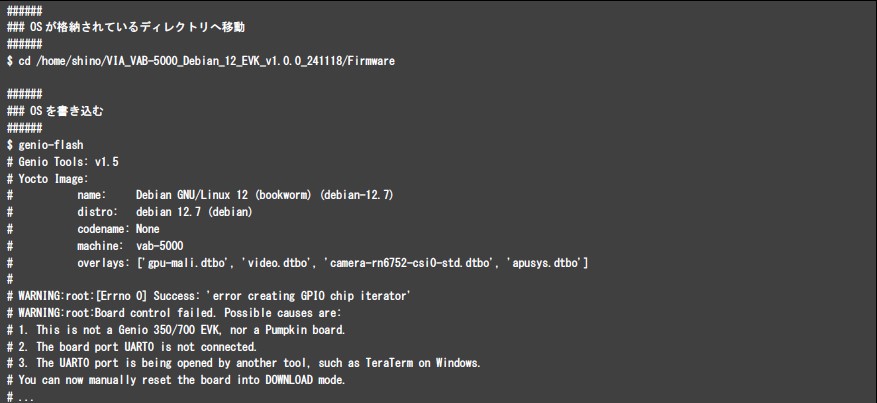
VAB-5000へ書き込むためのDebian OSはVIAのホームページから入手することができます。 VAB-5000向けのOSダウンロードサイト
Download_Debian

VAB-5000-microUSB

VAB-5000-SW1

VAB-5000-desktop_Debian
VIA独自のミドルウェア「Neuron Runtime Helper」を利用してMediaTek Genio 700に統合されたMDLAをPythonから制御する
VIA Neuron Runtime Helperは、新規プロジェクトの立ち上げはもちろん、既存のプロジェクトをVAB-5000上へ移植する作業も高効率化することのできるPythonパッケージです。Genio 700の開発環境においては、AIモデルを構成する各処理がいずれの演算器で実行するかについてのスケジューリングを、MediaTekの提供するncc-tfliteコマンドが決定します。ncc-tfliteが決定したスケジューリングポリシーはDLA形式のバイナリファイルに記録されます。MediaTekのAIフレームワーク「NeuroPilot」と緻密に統合されたNeuron Runtime Helperは、このDLA形式のバイナリファイルをPython上から呼び出すことにより、最適なスケジューリングポリシーに従ってAIモデルをCPU・GPU・MDLA上で実行することができます。 DLA形式のAIモデルを入手するためには、まずONNX形式のAIモデルをTensorFlow形式のモデルへと変換します。はじめからTensorFlow形式のモデルを利用することも可能です。次に、TensorFlow形式のモデルに対して最適化を加えながら、TensorFlow Lite形式のモデルへと変換します。最後に、MediaTekの提供するncc-tfliteコマンドを利用してTensorFlow Liteモデルを静的にコンパイルされたDLA形式のバイナリファイルへと変換します。以下の表は、最適化の度合いに応じて変化するデータタイプに応じて選択される演算器の対応を示したものです。MDLAを利用するように最適化のパラメータを強めることにより、より高速なAIモデルを開発することができます。ただし、最適化の度合いによってはモデルの精度が下がることがあるため、開発時には速度と精度のトレードオフに注意する必要があります。 VIA Neuron Runtime Helper User Guide
MDLA-GPU-CPU-map
デモを通してVIA Neuron Runtime Helperの機能を理解する
早速、Neuron Runtime Helperを利用した物体検出アプリケーションのソースコードを見てみましょう。インストールされたDebian OSの「/usr/share/neuron-runtime-helper」ディレクトリにNeuron Runtime Helperを利用して推論を行うPythonプログラムのデモが含まれています。以下の手順でデモを実行すると、DLA形式のYOLOv8モデルを利用した物体検出の様子を見ることができます。
AI transforma example
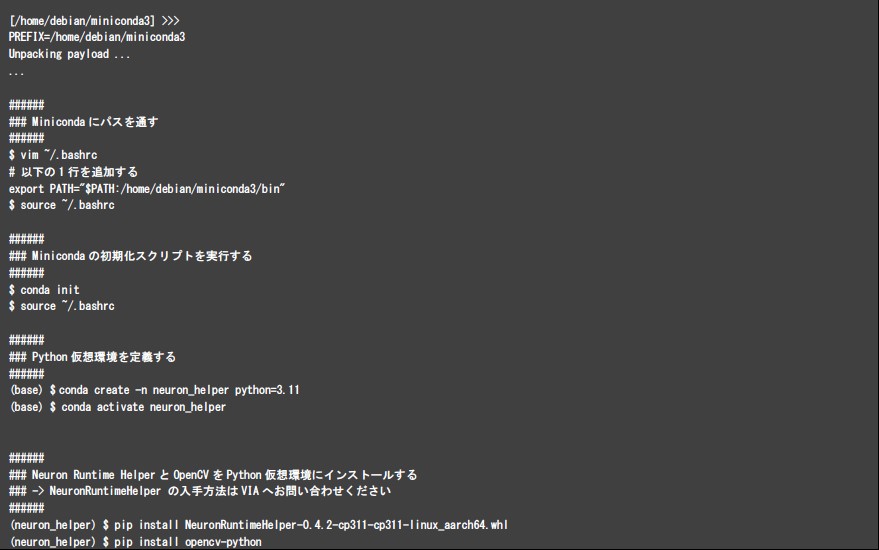
Neuron Runtime Helperを利用するための準備を行う
Neuron Runtime Helperを利用するには、VAB-5000上で動作するDebianにてPythonの仮想環境を定義する必要があります。Pythonの仮想環境を定義するため、Minicondaをインストールしてください。Minicondaは、Minicondaの配布サイトから「Miniconda3-py311_25.1.1-1-Linux-aarch64.sh」をDebian OS上にダウンロードし、以下の手順を実行することでインストールすることができます。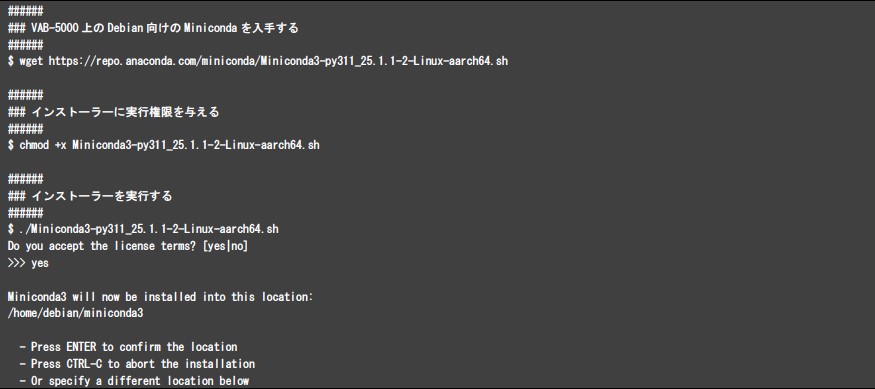
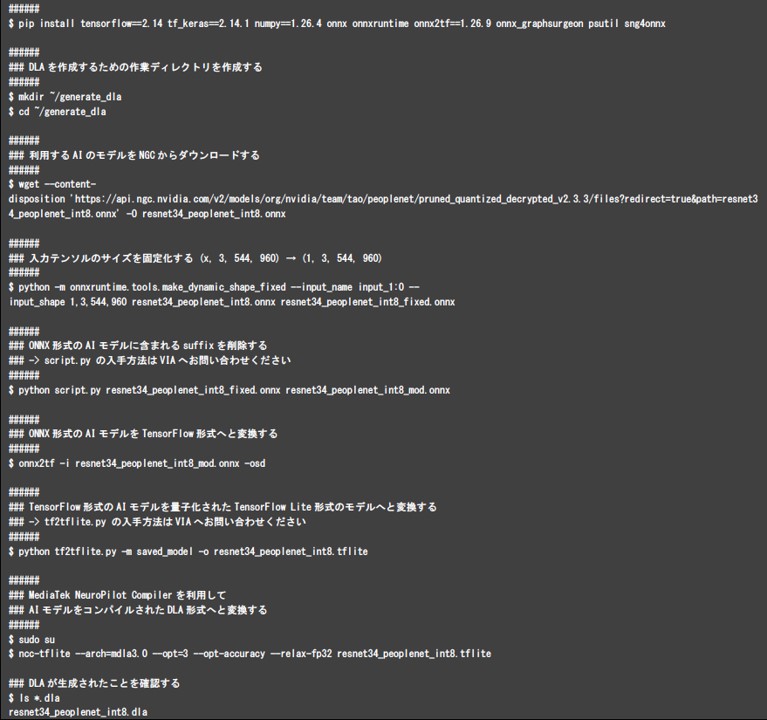
AIモデルをDLA形式に変換する
AIモデルをDLA形式へと変換する例を以下に示します。まず、Pythonの仮想環境を作成し、DLA形式のAIモデルを生成するために必要なパッケージをインストールします。次に、DLA形式に変換したいAIモデルを取得します。以下はONNX形式のAIモデル「PeopleNet」をNGC(NVIDIA GPU Cloud)から取得し、DLA形式のAIモデルへと変換する例となります。まず、NGCからダウンロードしたONNX形式のAIモデルは、入力テンソルのシェイプが(x, 544, 960, 3)であり可変長となっているため、これを構築するシステムに合わせて(1, 544, 960, 3)のシェイプへと固定化します。次に、TensorFlow形式へと変換する際に不要となるsuffixをscript.pyにより除去します。ここまで準備ができたら、ONNX形式のAIモデルを、TensorFlow形式を経て、最適化を加えながらTensorFlow Lite形式へと変換します。TensorFlow形式からTensorFlow Lite形式へと変換はtf2tflite.pyスクリプトにより実行されますが、TensorFlow Lite形式のAIモデル内で演算に利用するデータタイプを制限することにより、AIモデルの速度を向上させることができます。ただし、精度も変化することに注意してください(後述)。最後にTensorFlow Lite形式のAIモデルをncc-tfliteコマンドによりDLA形式のバイナリファイルへと変換します。ここで生成されたDLA形式のAIモデルをNeuron Runtime Helperで渡すことにより、ハードウェアに最適化され、適切にスケジューリングされたAIモデルをPythonから実行することができます。本説明中に登場したscript.pyとtf2tflite.pyはVIAの提供するスクリプトです。
TensorFlow Lite形式のモデルを生成する際の量子化
前述の説明にて、TensorFlow形式のモデルからTensorFlow Lite形式のモデルへ変換する際の最適化の強度を変更することにより、モデルの実行速度と推論精度が変化することを述べました。この最適化の強度は、VIAの提供するTensorFlow形式からTensorFlow Lite形式のモデルを生成するtf2tflite.pyの記述により制御することができます。以下に示すコードブロックは、tf2tflite.pyによる最適化の強弱を指定するものです。上のコードブロックはTensorFlow Lite形式のモデルを生成する際に、強い最適化を適用します。TFLiteConverterによりモデルを変換する際のパラメータ「converter.target_spec.supported_ops」にINT8を設定してモデル内で利用する演算を制限し、INT8の量子化を適用し、「converter.optimizations」に「tf.lite.Optimize.DEFAULT」を設定してTensorFlow形式からTensorFlow Lite形式へ変換する際に追加の最適化を行うよう指示しています。これにより、上のコードブロックにより変換されたAIモデルはMDLAで実行しやすい演算により構成され、データ長も短く、並列化しやすくなることから、高速に動作することができます。対して、下のコードブロックは最適化を加えません。特別な最適化を加えずに形式のみの変換に留めることにより、演算速度が向上することはありませんが、モデルの高い推論精度を維持することが可能です。以降の記事にて紹介する、最適化を強めたAIモデルは上のコードブロック、最適化を抑制したAIモデルは下のコードブロックによりモデルを変換したものとなります。
VIA 独自のAIフレームワーク「Neuron Runtime Helper」を使いこなすためのコツ
Neuron Runtime HelperはVIA独自のフレームワークであるため、一般的なAIフレームワークと比較すると、サンプルコードがあまり多くないといった状況にあります。また、手元のソースコードが、既存のAIフレームワーク向けのソースコードであり、Neuron Runtime Helperに対応したソースコードでなく、移植しなければならないケースもあるでしょう。そのため、既存のAIフレームワークとNeuron Runtime Helperの機能を比較することが、Neuron Runtime Helperを使いこなすためのコツと言えます。最もNeuron Runtime Helperと近いと感じるAIフレームワークはTensorFlow Liteです。以下にTensorFlow Lite for C/C++によりAIモデルを実行するシーケンスと、Neuron Runtime HelperによりAIモデルを実行するシーケンスの比較を掲載します。この対比から、Neuron Runtime Helperが決して使いにくいものではなく、言語を跨いだとしてもTensorFlow Liteにより構築したプログラムの資産をNeuron Runtime Helper向けに簡単に変換することが可能であり、広く利用されているAIフレームワークと同等に利用できることを理解いただけると思います。
Tensorflowlite-vs-Neuronruntimehelper
NVIDIA GPU Cloudから入手したAIモデルを利用してエッジで物体検出をする
NGC(NVIDIA GPU Cloud)から取得したAIモデル「PeopleNet」を基に、上記の手順によりDLA形式のAIモデルを作成し、Neuron Runtime Helperを利用して物体検出を行なった例を以下に示します。PeopleNetは映像中の人物と顔を検出するAIモデルです。モデルの入力には、サッカーをプレイする動画(1440p:2560px×1440px)を利用しました。VAB-5000はこの入力動画に対して、21~23FPSで推論することができます。 モデルの入力として選択したサッカーをプレイする動画(shutterstock)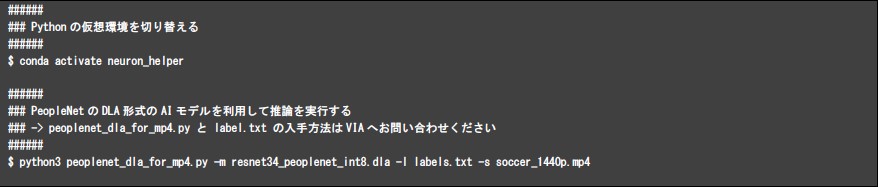

Infer_peoplenet_1440p
メインストリーム向けのVAB-5000とハイエンド向けのNVIDIA Jetson Orin NXを搭載したAMOS-9100の比較
VIAはエッジAIの分野に対して、メインストリーム向けにVAB-5000を、ハイエンド向けにAMOS-9100/AMOS-9000を提供しています。 AMOS-9100/AMOS-9000はNVIDIA Jetson Onix NXを搭載したソリューションです。ここでは、NGCから取得した同じAIモデル「PeopleNet」を各プラットフォームで利用した場合、どのような性能差が生まれるかについてご紹介します。なお、推論には、VAB-5000はNeuron Runtime Helperを利用しており、AMOS-9100はNVIDIAの提供するフレームワークであるDeepStreamとTensorRTを利用しています。 AMOS-9100の製品情報はこちらからご確認いただけます AMOS-9000の製品情報はこちらからご確認いただけます VAB-5000の製品情報はこちらからご確認いただけますAMOS-9100/AMOS-9000における量子化
AMOS-9100のAIモデルは、NGCから取得したONNX形式から、実際に実行されるTensorRT形式へと変換される際に、データタイプがINT8とFP16のみとなるように量子化されます。この量子化は、動画に対してAIモデルを適用するDeepStreamプラットフォームが最初にONNX形式のAIモデルを参照した際に行われ、量子化されたAIモデルはTensorRT向けの形式であるEngineファイルとして保存されます。二度目以降の実行では、保存されたEngineファイルに格納されたAIモデルが利用されます。なお、AMOS-9100上のtrtexecコマンドを利用することにより最適化の度合いを調整したEngineファイルを事前に生成しておくことも可能です。以降に示す本記事のAMOS-9100におけるAIの実行性能は、AIモデルに対してINT8/FP16の量子化を適用するデフォルトの最適化のみを加えたものとなっています。人物が大きく映り込んでおり物体検出のしやすい動画に対する推論
まず、以下はサッカーをプレイする動画(1440p)に対して推論を実行した例です。VAB-5000では21~23fps、AMOS-9100では29~32fpsで動画を処理することが可能であり、検出精度はほぼ同等となっています。なお、この入力動画は、人物が正面から大きく映り込んでおり、とても物体検出しやすい動画です。
Infer peoplenet soccer VAB-5000 vs AMOS-9100
仰望な画角によりやや人物の物体検出がしにくい動画に対する推論
続いて、バスケットボールをプレイする動画(1440p)に対して推論を実行した例を以下に示します。この動画は、仰望な画角と人混みの影響により人物を検出しにくい動画です。この動画に対する推論では、VAB-5000とAMOS-9100双方が28~30fps程度の性能で推論をすることができていますが、AMOS-9100による推論の方がより多くの人物を検出できています。VAB-5000が前の例よりも高速に動作している理由は、検出できた物体数が少ないことにより、処理が削減された影響と思われます。 モデルの入力として選択したバスケットボールをプレイする動画(shutterstock)
Infer peoplenet parade AMOS-9100
VAB-5000に対する最適化を低減し検出精度を向上させた場合の推論
AMOS-9100同程度までVAB-5000の検出精度を上げるために、TensorFlow形式からTensorFlow Lite形式のAIモデルへ変換する際の最適化を抑制し、精度の高い演算のみでAIモデルを構築した例を以下に示します。最適化を抑制することにより、より多くの物体を検出できるようになっています。その一方でMDLAを利用できない演算がAIモデルに含まれるようになることから、実行速度は11~12fps程度に留まります。
Infer_peoplenet_parade_no_optim