
生成AI(Generative-AI)は、ディープラーニングの技術を駆使して、入力された情報から新しいコンテンツを生成することのできるAI技術です。こうした生成AIの技術を、エッジ上のAIアクセラレータ(APU)と組み合わせることによって実現できる「エッジ生成AI」は、ネットワークを必要としないシステムであり、ユーザーに最適なコンテンツをリアルタイムに提供することが可能です。これらの特長からエッジ生成AIは、民生機器だけでなく産業分野においても高い注目を集めています。そこで本記事では、写真を指定した画風に変換する生成AI「arbitrary-image-stylization」を、組み込み向けのAPUである「MDLA」を備えたVIAのメインストリーム向けシングルボードコンピュータ「VAB-5000」上で実行し、エッジのみで動画をリアルタイムに絵画風のイラストへと変換するAIアプリケーションを開発する方法について紹介します(下図:写真と画風を指定して絵画風のイラストを生成するアプリケーション)。

arbitrary-image-stylization-v1_outputs
なお、本記事はAIアプリケーションをゼロから開発する流れについて解説していることから、はじめてAIアプリケーションの開発に携わる方や、TensorFlowやOpenCVをこれから学ぼうとする方におすすめの内容となっています。また、本記事では、AIアプリケーションに利用するAIモデルを、これまでの記事にて紹介してきたNVIDIA GPU CloudやNVIDIA TAO Toolkitからではなく、さらに多くのAIモデルを配布しているTensorFlow Hub(Kaggle Model:後述)から入手します。このことから、本記事を読んでいただくことにより、TensorFlow Hubが配布しているバリエーションに富んだAIモデルをVAB-5000の開発に取り入れる方法と、取り入れる際の注意点についてもご理解いただけます。本記事を通して、VIAの高性能なエッジAIソリューション「VAB-5000」により実現できるエッジ生成AIの魅力をご体験ください。
TensorFlow Hubから入手したAIモデルを使ってVAB-5000上にエッジ生成AIを構築するまでのワークフロー
写真を指定した画風へと変換する生成AI「arbitrary-image-stylization」を、VAB-5000が持つ演算リソースであるAPU「MDLA」向けに最適化し、動画をリアルタイムに加工することのできるエッジ生成AIのアプリケーションを開発するためには、以下に挙げる8つの項目について理解する必要があります。
本記事では、まず産業分野において注目が高まっている生成AIについて紹介し、従来型のAIと生成AIの違いについて解説します。次に、AIモデルの配布サービスである「TensorFlow Hub(Kaggle Model)」について紹介し、これまでに紹介してきたAIモデルの配布サービス「NVIDIA GPU Cloud」や「NVIDIA TAO Toolkit」で解説してきたように、サービスより入手したAIモデルをVAB-5000上で実行する方法について示します。その後、本記事で扱う生成AI「arbitrary-image-stylization」について、その特徴を紹介し、TensorFlow Hubから入手した「arbitrary-image-stylization」を活用したAIアプリケーションをVAB-5000上に構築するまでの実装手順について解説します。実装パートではまず、AIモデルが利用する入力テンソルを準備し、AIモデルの処理結果である出力テンソルを活用するための、PreProcessとPostProcessの実装方法について紹介します。次に、VAB-5000上でTensorFlow Liteと、最適化の済んでいないAIモデルを使って、AIアプリケーションを仮組みする方法を解説します。最後に、VAB-5000向けにAIモデルを最適化し、VIAの提供するAI実行フレームワークである「Neuron Runtime Helper」を活用してVAB-5000のAPU「MDLA」上でAIモデルを高速に実行する方法について紹介し、Neuron Runtime Helperを利用することによる効果について言及。最適化されたAIモデル「arbitrary-image-stylization」がVAB-5000上で高速に動作し、動画をリアルタイムに指定した画風へと変換できる様子を示します。本記事を通して、生成AIの特徴を理解し、VAB-5000上にゼロからAIアプリケーションを構築する手順と、生成AIをVAB-5000向けに最適化して「エッジ生成AI」を実現するための方法を習得していただければ幸いです。
産業分野にも採用されはじめている生成AIとは
VIAのメインストリーム向けエッジAIソリューションである「VAB-5000」は、産業分野を中心に広く利用されている「分類」や「推定」などを主なタスクとした「従来型のAI」に加えて、近年高い注目を集めている「生成AI(Generative-AI)」も高速に実行することが可能です。本節ではまず生成AIの特徴について解説し、続けて産業分野における生成AIの活用例について紹介します。
従来型のAIと生成AIの違い
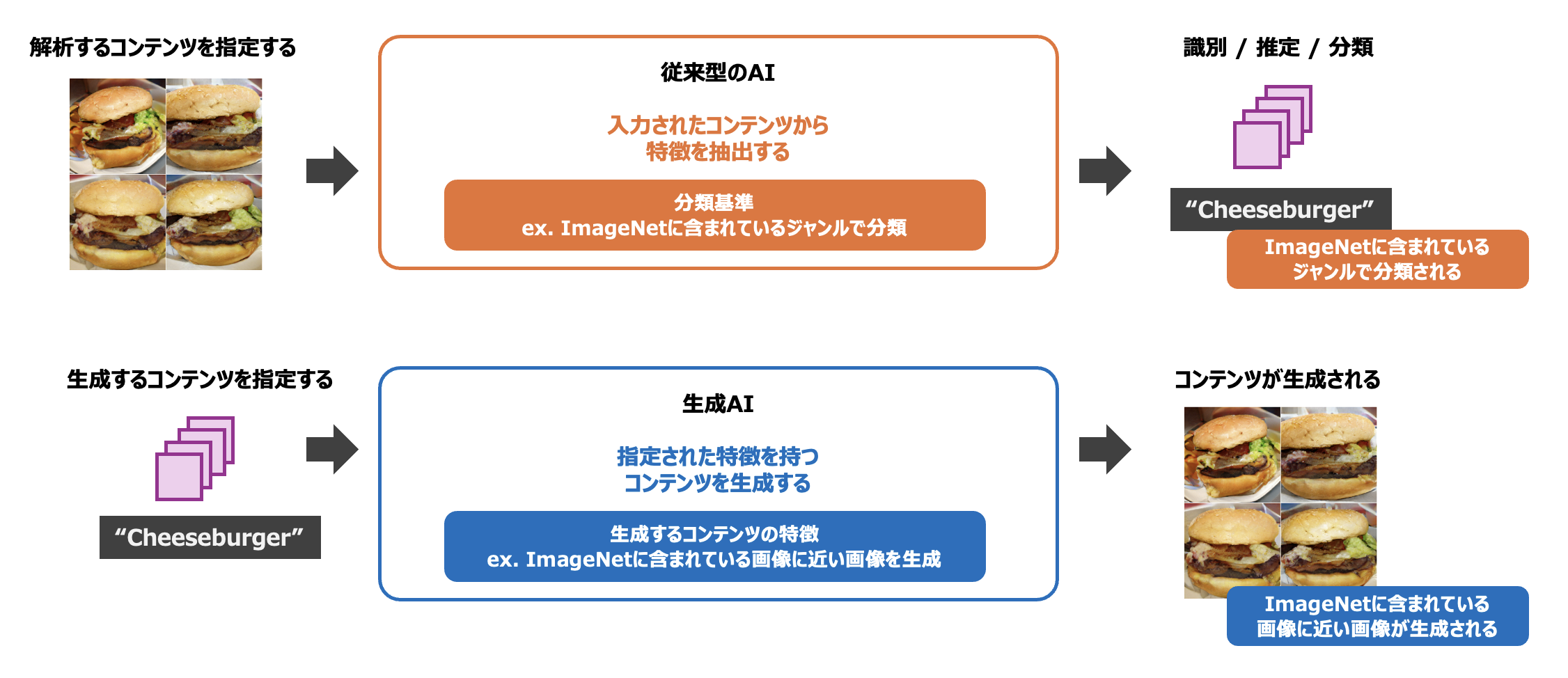
はじめに、従来型のAIと生成AIの違いについて考えてみましょう。これまでの記事で扱ってきた従来型のAIは、入力された画像や音声などを解析し、その特徴量から「識別」「推定」「分類」を行うものでした。従来型のAIには、画像内から人物の特徴を持ったピクセルを抽出し、セグメンテーションを行うAIモデルや、入力された波形から特徴を抽出することにより、音声をテキストに変換するAIモデルなどがあります。
これに対して、生成AIは入力されたランダムノイズに基づいて、これまでに存在しなかった新しいコンテンツを生成します。なお、ここで生成されるコンテンツは無秩序なものではなく、ある一定の「特徴」を備えます。例えば、TensorFlow Hub(Kaggle Model)よりダウンロードすることのできるAIモデル「BigGAN」はImageNetと呼ばれる画像のデータセットに似通った特徴を備えた画像を新たに生成することが可能な生成AIです。BigGANは、1000個のカテゴリのうち、どのカテゴリの画像を生成するかを示すOne-Hot Encodingのベクトルデータと、出力画像にバリエーションを与えるランダムノイズを入力として、これらの入力に基づいて、新たな画像を生成し、出力します(下図:BigGANにより生成されたチーズバーガーの画像)。入力にランダムノイズを利用することにより、そのゆらぎから実行する度に毎回新たなコンテンツを生成することができます(ランダムノイズでなく固定値を入力すれば、生成される画像は毎回同じものとなります)。なお、BigGANのようにゼロからコンテンツを生成するAI以外にも、入力された画像や音声といったコンテンツを、ある特徴を備えたコンテンツへと変換するAIモデルも生成AIのひとつです。
image_created_by_generativeAI
旧来、生成AIは総じて計算量が大きいことから、豊富な演算リソースを利用できるワークステーションやサーバー上で実行されることが一般的でした。しかし、近年はAPUの登場と最適化技術の向上により、エッジ上でも生成AIを実行できるようになりつつあります。こうした、エッジ生成AIを実行することのできるプラットフォームのひとつがVIAのメインストリーム向けAIソリューション「VAB-5000(下図)」です。エッジ生成AIのシステムはネットワークを必要としないことから、優れた応答性を実現することができます。また、エッジですべての処理が完結することから、大規模なシステムにおいて度々懸念材料となっていたサーバーに負荷が集中する課題についても解決することができます。次の節では、実際にこうしたエッジ生成AIが利用されているフィールドについて紹介します。

VAB-5000
代表的な生成AIの一例
現在、生成AIは産業分野においても高い注目を集めており、様々なフィールドで生成AIを活用したサービスのPoC(Proof of Concept)が始まっています。以下に、エッジ生成AIが利用されているアプリケーションの一例を挙げます。
そのときの質問に適した回答をリアルタイムに生成することのできるチャットボット
状況にあわせた画像や音声を生成することで新たな体験を提供するデジタルサイネージ
理想的な製品写真を生成して生産した製品と比較することにより不良品を検出する外観検査装置
こうしたエッジ生成AIを活用したアプリケーションの魅力は、生成AIの特徴である状況に則したコンテンツを生成できる能力を、エッジのみで完結できる点にあります。例えば、生産現場にて外観検査を行うエッジ生成AIは、理想的な製品写真を生成AIにより作成し、これを実際に生産された製品と比較することにより不良品を検出します。このシステムはエッジのみで完結することから、製品に関する情報をネットワークに公開することなく外観検査をすることが可能となり、高い堅牢性を獲得できます。またサーバーを必要とせず、処理の一極集中が発生しないことから、簡単にスケールアウトさせることが可能です。さらには、ネットワークを利用しないため、優れた応答性も達成することが可能であり、大量の製品を高速に検査することができます。
TensorFlow Hub(Kaggle Model)を開発に取り入れるための予備知識
本記事では、エッジ生成AIの一例として、TensorFlow Hub(Kaggle Model)から入手した学習済みの生成AI「arbitrary-image-stylization」をVIAのエッジAI向けのシングルボードコンピュータ「VAB-5000」上で実行する手順について解説します。まず、AIモデルの解説に先立って、TensorFlow Hub(Kaggle Model)が提供するサービスについて説明します。
TensorFlow Hubを利用してAIアプリケーションを効率的に開発する
TensorFlow Hubは、実務で広く利用されているAIフレームワーク「TensorFlow」に関する技術情報をまとめたポータルサイトです。VIA VAB-5000のYocto OS上で実行することのできる軽量なAIモデル「TensorFlow Lite」に関する技術情報もTensorFlow Hubに集約されています。また、TensorFlow HubはAIモデルを配布する「Kaggle Model」のサービスも提供しています。Kaggle Modelでは、学習済みのAIモデルが多数公開されており、従来型のAIはもちろん、生成AIも簡単に入手することができます。公開されているAIモデルは、Pythonのパッケージであるtensorflow_hubパッケージを使ってアプリケーション実行時にダウンロードすることもできますし、アプリケーション実行前にWebサイトからtar.gz形式に圧縮されたTensorFlow1 / TensorFlow2 / TensorFlow Lite形式のAIモデルとしてダウンロードしておくことも可能です。こうしたTensorFlow Hubのサービスを活用することにより、AIモデルの実装に費やす時間や学習用データセットを準備する時間を削減できるため、AIアプリケーションをより効率的に開発することが可能となります。なお、tensorflow_hubパッケージはtensorflowパッケージのバージョンとPythonのバージョンに強く依存していることから、tensorflow_hubパッケージを利用せずにWebサイトからAIモデルをあらかじめダウンロードして利用する手順の方が、アプリケーション開発時の制約は少なくて済みます。
TensorFlow Hubを利用してTensorFlowをベースとしたAIアプリケーションを構築する手順
TensorFlow Hubでは、AIモデルがTensorFlow1、TensorFlow2、TensorFlow Liteといった幅広い形式で配布されています。ただし、すべてのAIモデルがTensorFlow1、TensorFlow2、TensorFlow Liteすべての形式を配布しているわけではありません。そのため、AIアプリケーションを開発する際には、事前に利用したいAIモデルが期待する形式でモデルを配布しているか確認しておく必要があります。例えば、本記事でAIモデルの実行フレームワークとして利用する「Neuron Runtime Helper」は、TensorFlow Lite形式のAIモデルを基にして生成することのできるDLA形式のAIモデルに対応していることから、TensorFlow Lite形式でモデルを配布しているAIモデルを選択すると効率的にアプリケーションを開発することができます。なお、Neuron Runtime Helperを利用する場合、入力となるTensorFlow Lite形式のモデルはinput shapeがすべて特定の値に固定されているモデルである必要があります。これは、AIモデルをTensorFlow Lite形式からDLA形式へと変換するncc-tfliteコマンドとNeuron Runtime Helperの仕様に基づく制約です。
以下の図は、TensorFlow HubとNVIDIA GPU Cloud/NVIDIA TAO ToolkitよりAIモデルを入手してから、Neuron Runtime Helperで実行することのできるDLA形式のAIモデルを生成するまでのフローを表したものです。TensorFlow Hubを利用する場合は、TensorFlow Lite形式でAIモデルをダウンロードすることができるため「ncc-tflite」コマンドひとつでDLA形式のAIモデルを生成することができます。ただし、簡単に変換することができる反面、利用できるモデルはTensorFlow Hubで配布されているAIモデルのうち、TensorFlow Lite形式であり、かつinput shapeが固定されているモデルに限定されます。NVIDIA GPU CloudやNVIDIA TAO Toolkitを利用する場合、入手できるAIモデルはONNX形式となるため、TensorFlow Hubを利用する場合と比較するとDLA形式のAIモデルを入手するまでの手順は多くなりますが、フローの途中でONNX runtimeの提供するAPIのひとつである「onnxruntime.tools.make_dynamic_shape_fixed」によりinput shapeを自由な値に固定することができるため、TensorFlow Hubを利用する場合に必要とされていたinput shapeに関する制約はなく、公開されているすべてのAIモデルをVAB-5000の開発に利用すること可能です。

NGC_vs_TensorFlowHub
なお、Neuron Runtime HelperをはじめとするVAB-5000のMDLAを制御するミドルウェアは、MDLAに非対応な命令を含むDLA形式のAIモデルをサポートしていません。非対応な命令を含むAIモデルに対してncc-tfliteコマンドを実行した場合、以下のようなメッセージが出力されます。こうしたメッセージが出力される場合には、別のAIモデルを選択するか、AIモデルに修正を加えて、MDLAがサポートしていないコードブロックを削除する必要があります。MDLAがサポートしている命令については以下のサイトをご参照ください。

NVIDIA GPU CloudやNVIDIA TAO Toolkitだけでなく、さらにバリエーションに富んだAIモデルを配布しているTensorFlow Hubを活用することで、より多くのAIモデルをVIA VAB-5000上に統合することができます。そのため、これらのAIモデルを配布するサービスについて知ることは、効率よくAIアプリケーションを開発するための鍵と言えるでしょう。
本記事で扱う生成AI「arbitrary-image-stylization」とは
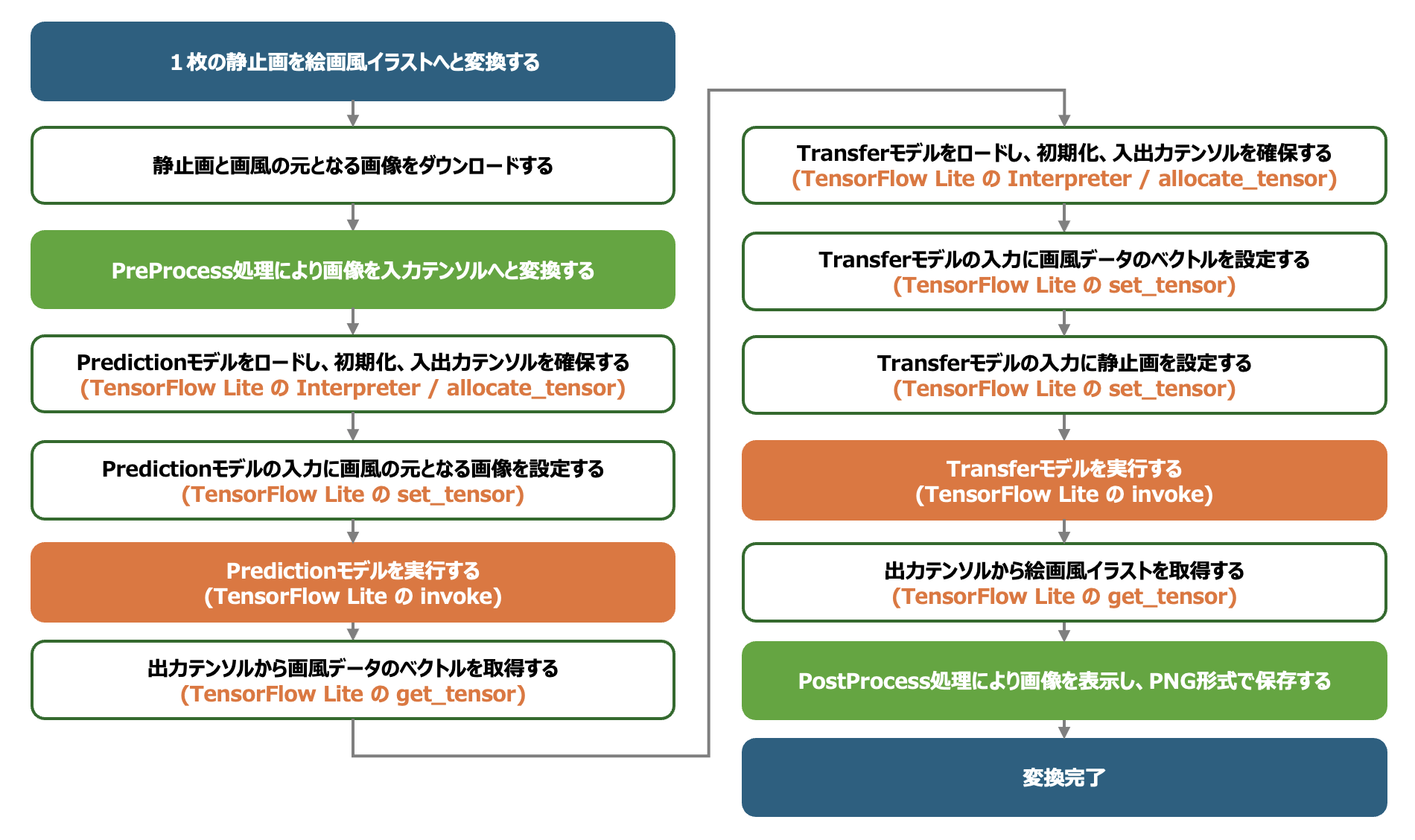
本記事は、生成AIモデルである「arbitrary-image-stylization」をTensorFlow Hubよりダウンロードしてから、AIアプリケーションを構築するまでの実装手順について解説します。arbitrary-image-stylizationは、入力された画像を、指定された画風に沿った絵画風のイラストへと変換することのできる生成AIです。arbitrary-image-stylizationは、2つのAIモデルから構成されています(下図)。まず前段の「Predictionモデル」が、画風を示す入力画像を解析し、画風データのベクトルを生成します。次に、後段の「Transferモデル」が、前段で生成した画風データのベクトルと、イラスト調の画像へと変換したい入力画像に基づいて、指定された画風に沿った絵画風のイラストを生成、出力します。動画に対して画風変換を適用する場合は、まずアプリケーションの先頭でPredictionモデルを実行し画風データのベクトルを生成した後、動画を再生しながら、各フレームに対して同じ画風データのベクトルでTransferモデルを適用します。フレーム毎にPredictionモデルを実行する必要はありません。
Kaggle Model:arbitrary-image-stylization-v1

ArtModel_Prediction_and_Transfer
なお、arbitrary-image-stylizationのAIモデルは量子化されており、FP16で量子化されたモデルと、INT8で量子化されたモデルがTensorFlow Hubにて配布されています。FP16で量子化されたモデルの方が、より鮮明な出力画像を生成することができますが、INT8で量子化されたモデルの方が、より高速に画像を変換することができます(後述)。
TensorFlowを利用したエッジ生成AIアプリケーションをPythonで開発する
それでは早速、生成AIである「arbitrary-image-stylization」をTensorFlow Hubより入手し、AIアプリケーションを開発してみましょう。なお、本記事ではVAB-5000のAPUである「MDLA」の制御にVIAが独自開発したミドルウェア「Neuron Runtime Helper」を利用します。Neuron Runtime HelperはPythonのパッケージであり、これを使うことによりPython上から簡単にMDLA を制御して、DLA形式のAIモデルを高速に実行することができます。Neuron Runtime Helperの入手方法や本記事で扱っているアプリケーションのソースコード全文を入手する方法についてはVIAのサポートデスクまでお問い合わせください。なお、アプリケーションの実行にはVIA VAB-5000のDebian OS環境が必要です。
VIA Neuron Runtime Helper User Guide
エッジ生成AIにより動画を指定した画風のイラストへと変換するまでの開発フロー
今回は、AIアプリケーションを下図の手順で開発します。まず、一般的な AIフレームワークである TensorFlowと、TensorFlow Hubから入手したTensorFlow Lite形式のarbitrary-image-stylizationモデルを使って、1枚の静止画を絵画風のイラストへと変換するAIアプリケーションを開発します。このアプリケーションはTensorFlowのみで記述されるため、VAB-5000に依存するコードを含んでおらず、実行プラットフォームに依存しないポータブルなアプリケーションとなります。一方でポータブルであることから、このアプリケーションはVAB-5000向けに最適化されておらず、MDLAを利用しないため、十分な推論速度を得ることはできません。次のステップでは、TensorFlow LiteのAIモデルをDLA形式へと変換し、前の手順で実装したTensorFlow Lite形式のAIモデルを制御するコードブロックを、Neuron Runtime Helperを利用してDLA形式のAIモデルを制御するコードブロックへと改変することにより、MDLAを利用し高速に画風変換のできるAIアプリケーションを実現します。ここまで実装した段階で、DLA形式のAIモデルにより十分な速度で画風変換ができることを確認します。今回のゴールは、動画に対してarbitrary-image-stylizationを適用することですので、15FPS~30FPS(1フレーム30ms~60ms)程度の推論速度であることが望ましいです。期待する性能を得ることができていれば、最後に、入力ソースを静止画から動画へと変更し、OpenCVとNeuron Runtime Helperを活用してリアルタイムで動画を変換できるAIアプリケーションを構築します。

Development_Flow
AIモデルを実行するためのPythonの仮想環境を定義する
開発に先立って、以下の手順でVAB-5000上にMinicondaをインストールし、PythonパッケージであるNeuron Runtime HelperとTensorFlowをインストールして、アプリケーションを実行するためのPythonの仮想環境「neuron_helper」を作成します。Pythonの仮想環境を構築する際は、numpyのバージョンに注意してください。numpy2.xがインストールされているとパッケージの不整合が生じて実行時にエラーとなります。なお、Neuron Runtime Helperパッケージの入手方法については、VIAのサポートデスクまでお問い合わせください。

以降の手順では、このPythonの仮想環境上でアプリケーションを実行します。
>入力データと出力データを扱うPreProcessとPostProcessを定義する
今回実装するアプリケーションは変換対象となる画像と画風情報の基となる画像を入力として、生成AIにより生成された絵画風のイラストの画像を出力します。そのため、まずは、画像を読み込んでAIの入力テンソルへと加工するPreProcessの処理と、AIから出力されたテンソルを画像として保存するPostProcessの処理を実装します。
PreProcessの処理は、以下のフローから構成されます。まず、URLを入力として、Webサイトから画像をダウンロードします。次に画像を0~255のuint8の階調から、AIモデルの入力に適した0.0~1.0のfloat32の階調へと変換します。その後、各AIモデルの入力画像サイズにあわせて画像に対してクリッピングとリサイズの加工を加え、入力テンソルを作成します。

PreProcess

PostProcessの処理では、AIモデルから出力されたテンソルをPythonパッケージであるmatplotlibを利用してグラフ上にプロットし、プロットしたグラフを保存します。また、出力画像を単体でtf.keras.utils.save_imgを利用してPNG形式の画像として保存します。なお、tf.keras.utils.save_imgはAIモデルから出力された0.0~1.0の値を持つfloat32型のテンソルを、一般的な画像に用いられる0~255のuint8型の階調へと変換するscale機能を持っています。

PostProcess

PreProcessとPostProcessを組み合わせたフローは以下のようになります。

TensorFlow Lite形式のAIモデルへ入手して入力テンソルと出力テンソルのshapeを確認する
次に、TensorFlow Hubから入手したTensorFlow Lite形式のAIモデルをアプリケーションに組み込みます。TensorFlow Hubはarbitrary-image-stylizationを構成する2種類のモデル「Predictionモデル」と「Transferモデル」を、それぞれ「FP16(float16型)」と「INT8(int8型)」向けに量子化した、合計4個のモデルを配布しています(下図)。今回は、これらのモデルをあらかじめtar.gz形式でVAB-5000上にダウンロードしました。
Kaggle Model:arbitrary-image-stylization-v1

Kaggle_Arbitrary
そして以下が、ダウンロードしたAIモデルをプログラム上にロードするためのコードブロックとなります。ここでは、INT8で量子化されたPredictionモデルとTransferモデルをロードしています。Pythonでは、tf.lite.InterpreterメソッドにTensorFlow Lite形式のAIモデルへのパスを指定することで、AIモデルをロードすることができます。ロードした後、生成されたInterpreterのget_input_detailsとget_output_detailsを呼び出すことにより、AIモデルの入力テンソルと出力テンソルの情報を確認することができます。

以下は、上記のプログラムを実行して得られたPredictionモデルの入力テンソルと出力テンソルの情報です。この情報の`shape`と`dtype`を確認することにより、Predictionモデルには、入力としてshapeが(1, 256, 256, 3)のfloat32型のテンソルが必要であることと、Predictionモデルが出力としてshapeが(1, 1, 1, 100)のfloat32型のテンソルを生成することがわかります。入力テンソルの(1, 256, 256, 3)は画風情報の基となる絵画の画像を期待しており、出力テンソルの(1, 1, 1, 100)にはTransferモデルで利用する画風データのベクトルが含まれています。

続いて以下がプログラムを実行して得られたTransferモデルの入力テンソルと出力テンソルの情報です。この情報によりTransferモデルが、入力としてshapeが(1, 384, 384, 3)のfloat32型のテンソルと(1, 1, 1, 100)のfloat32型のテンソルを必要としていることと、Transferモデルが出力としてshapeが(1, 384, 384, 3)のfloat32型のテンソルを生成することがわかります。ここでの入力テンソル(1, 384, 384, 3)は画風変換の対象となる静止画を期待しており、入力テンソルの(1, 1, 1, 100)はPredictionモデルにより生成された画風データのベクトルを期待しています。出力テンソルの(1, 384, 384, 3)にはAIモデルにより生成された絵画風のイラストデータが含まれます。

TensorFlow Lite形式のAIモデルの構造をNetronで可視化してMediaTek Genio 700のAPUに適した量子化が含まれていることを確認する
前述した手順によりTensorFlow Lite形式のAIモデルをロードできることを確認できたため、次に、今回利用するTensorFlow Lite形式のAIモデルに、VAB-5000の核となるSoCであるMediaTek Genio 700のAPU「MDLA」に適した演算が含まれているか確認してみましょう。AIモデルを可視化できるWebサイトであるNetronを利用し、ダウンロードしたTensorFlow Lite形式のTransferモデルを開くと、以下のグラフを確認することができます(グラフ全体は非常に巨大なため、グラフの一部を抜粋して掲載します)。可視化されたグラフでは、以下のように「Quantize」と「Dequantize」が含まれていることを見て取れ、AIモデルが量子化されていることがわかります。「QuantizeからDequantizeまでの区間」がMDLAにより高速に処理することのできるコードブロックです。FP16で量子化されているAIモデルでは、QuantizeからDequantizeまでの区間の演算にfloat16型を用いており、INT8で量子化されたAIモデルではこの区間の演算にint8型を用います。いずれもMDLAが得意とする演算であるため、これらのコードブロックはMDLAにより高速に実行することができます。ただしQuantizeとDequantizeの実行にもコストが発生するため、あまりに多くQuantizeとDequantizeが繰り返される場合は処理時間が逆に増加することがあります。なお、このグラフから、本モデルの入力テンソルは入力直後にQuantizeされており、出力テンソルは出力される直前にDequantizeされていることから、このAIモデルの入力テンソルと出力テンソルが量子化されていないこともわかります。

Quantize_and_Dequantize
TensorFlow Lite形式のAIモデルを利用してAIアプリケーションを構築する
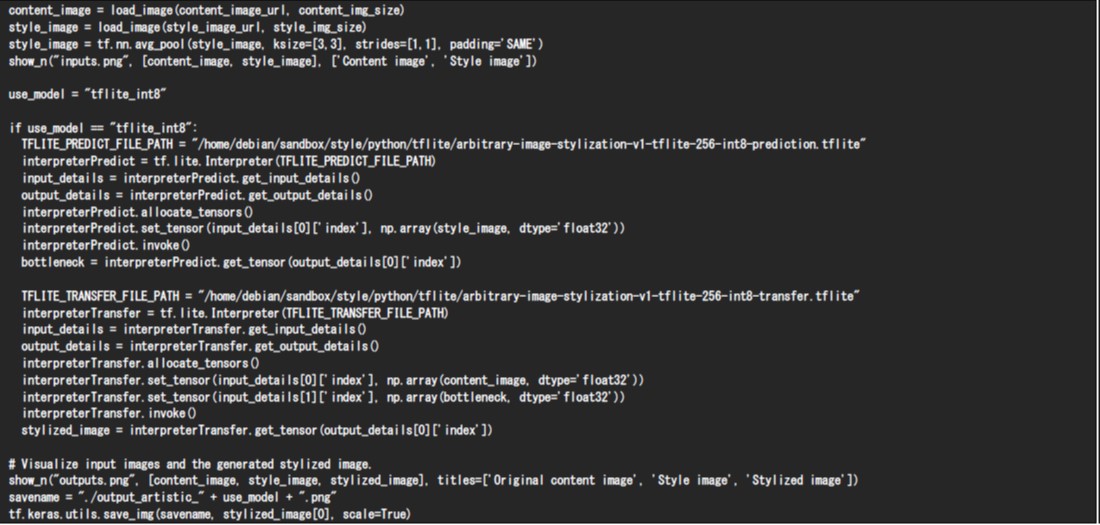
最後に、PreProcessの処理とPostProcessの処理をTensorFlow Lite形式のAIモデルの処理と組み合わせて、静止画を絵画風のイラストへと変換するAIアプリケーションを構築します。以下はその処理フローと実装例です。なお、本プログラムではVAB-5000のAPU「MDLA」を制御するNeuron Runtime Helperを利用していないことから、すべての処理はVAB-5000のCPU上で実行されます。AIモデルの入力テンソルはset_tensorメソッドにより指定し、AIモデルの出力テンソルはget_tensorメソッドを使って取得します。2つの入力テンソルを必要とするTransferモデルに対しては、引数[0]と引数[1]を指定してset_tensorメソッドを2回呼び出し、複数の入力テンソルを設定します。
TensorFlowLite_and_PrePostProcess
TensorFlow Lite形式のAIモデルを利用した、ここまでの実装内容の処理時間を測定した結果、下記のような結果を得ることができました。本記事ではプログラムを5回実行したうち最も良い処理時間を抜粋して掲載しています。arbitrary-image-stylizationは生成AIの中では比較的に軽量なモデルですが、測定結果よりTransferモデルの処理時間が300ms以上(3FPS)となってしまうことから、CPUのみでAIモデルを実行する現状の実装のままではarbitrary-image-stylizationを動画に適用することは難しい、ということがわかります。

Performance_TFLiteOnly
TensorFlow Lite形式のAIモデルをDLA形式のAIモデルへと変換する
CPUのみでarbitrary-image-stylizationを実行した際の処理時間から、このAIモデルは動画をリアルタイムに変換するアプリケーションにそのまま適用することが難しいということがわかりました。そこで、次のステップとして、VAB-5000の持つAPU「MDLA」を利用するように、プログラムを更新していきましょう。MDLAの制御には「Neuron Runtime Helper」を利用します。Neuron Runtime Helperを利用するにあたって、まずはAIモデルをTensorFlow Lite形式から、Neuron Runtime Helperに対応したDLA形式のAIモデルへと変換します。DLA形式のAIモデルは、VAB-5000上のDebian OSにて、以下の操作を行うことで入手することができます。

DLA形式のAIモデルの入力テンソルと出力テンソルのshapeを確認する
続いて、PythonコードからNeuron Runtime Helperを利用して、DLA形式のPredictionモデルとTransferモデルをロードし、これらの入力テンソルと出力テンソルの情報を確認してみましょう。Neuron Runtime Helperでは「NeuronContext」クラスのコンストラクタにAIモデルへのファイルパスを指定することにより、AIモデルをロードすることができます。ロードした後は「Initialize」メソッドを呼び出し、AIモデルを初期化します。初期化後「GetInputDimensions」メソッドと「GetOutputDimensions」メソッドを呼び出すことでAIモデルの入力テンソルと出力テンソルのshapeを確認することができます。GetInputDimensionsとGetOutputDimensionsはデータ型を出力しませんが、DLA形式のAIモデルはTensorFlow Lite形式のAIモデルと同じ入出力となることが保証されていますので、データ型を確認する場合はTensorFlow Lite形式のAIモデルのデータ型を参照してください。
VIA Neuron Runtime Helper User Guide
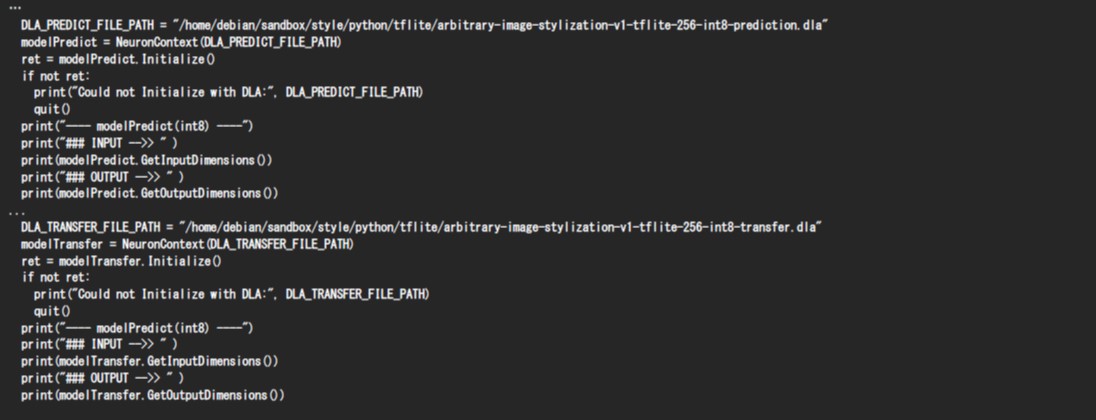
DLA形式のPredictionモデルは、TensorFlow Lite形式のAIモデルと同様に、入力テンソルとして(1, 256, 256, 3)のテンソルを期待し、(1, 1, 1, 100)の出力テンソルを生成します。

DLA形式のTransferモデルもTensorFlow Lite形式のAIモデルと同様に、1つ目の入力テンソルとして(1, 384, 384, 3)のテンソルを期待し、2つ目の入力テンソルとして(1, 1, 1, 100)のテンソルを期待し、(1, 384, 384, 3)の出力テンソルを生成します。

DLA形式のAIモデルを利用したAIアプリケーションをNeuron Runtime Helperを利用して構築する
以上の情報を基に、DLA形式のAIモデルを利用して絵画風のイラストを生成するAIアプリケーションを構築します(下図)。DLA形式のAIモデルの入力テンソルと出力テンソルは、TensorFlow Lite形式のAIモデルの入力テンソルと出力テンソルと同じshapeとデータ型であることから、画像から入力テンソルを生成するPreProcessと、出力テンソルを画像として保存するPostProcessはTensorFlow Lite形式を扱う際に実装したコードブロックを利用することができます。TensorFlow Lite形式のコードブロックとの違いは、AIモデルに入力テンソルをセットする処理と、AIモデルから出力テンソルを取得する処理にあります。Neuron Runtime Helperでは、「SetInputBuffer」メソッドによりAIモデルに入力テンソルを指定することが可能であり、「GetOutputBuffer」メソッドにより出力テンソルを取得することができます。以上の変更を加えたソースコードを以下に示します。なお、Transferモデルは2つの入力テンソルを必要としますので、SetInputBufferに引数0と引数1を指定して、2回呼び出すことにより2つの入力テンソルを設定します。
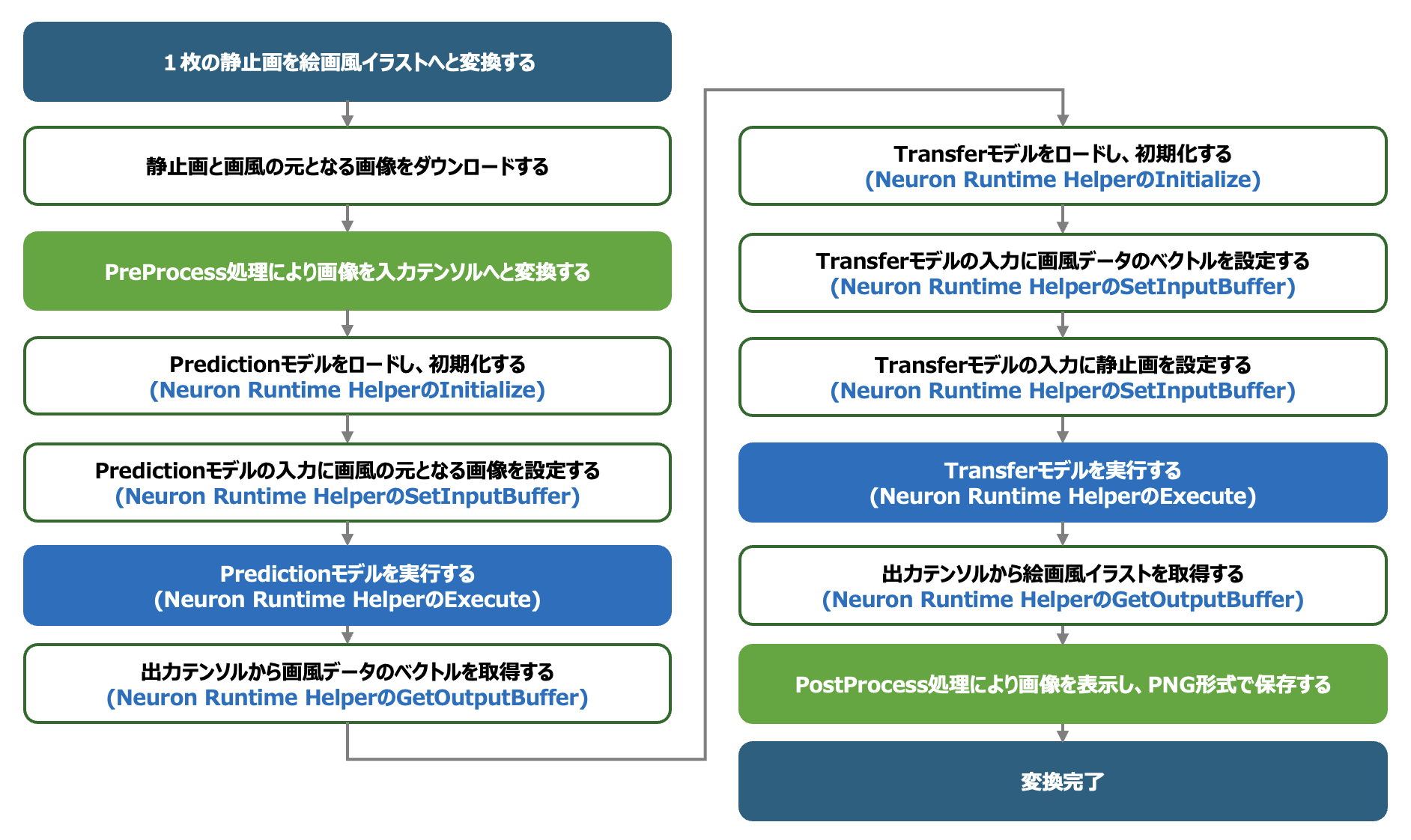
DLA_and_PrePostProcess

DLA形式のAIモデルとTensorFlow Lite形式のAIモデルの推論時間を比較する
前述した内容のソースコードを実装し、1枚の画像を絵画風のイラストへと変換するAIアプリケーションを構築した際のPredictionモデルとTransferモデルの処理時間を計測した結果を以下に示します。また、これらのAIモデルによって生成された画像も併記します。
処理時間の面ではINT8で量子化されたDLA形式のAIモデルが最も早く、次いでFP16で量子化されたDLA形式のAIモデルが早いことがわかります。arbitrary-image-stylizationモデルを動画の画風変換に利用する場合、Predictionモデルは画風データのベクトルを生成する処理であるため、動画を変換する前に実行することが可能であり、絵画風のイラストを生成する時間はTransfer モデルの処理時間によって決まります。Transferモデルの処理時間は、INT8で量子化されたDLA形式のAIモデルでは23.7ms、FP16で量子化されたDLA形式のAIモデルでは26.2msとなっており、30FPS以上の性能を得ることができていますので、FP16またはINT8で量子化されたDLA形式のarbitrary-image-stylizationモデルであれば、動画をリアルタイムに処理できることがわかります。一方で、生成された画像を比較すると、INT8で量子化されたDLA形式のAIモデルではイラストの細部が潰れてしまっているのに対して、FP16で量子化されたDLA形式のAIモデルは細部まで描きこまれたイラストを生成できていることを確認できます。このことから、動画を絵画風のイラストへと変換するAIアプリケーションには「FP16で量子化されたDLA形式のAIモデル」が適していると言えます。

Performance_TFLite_and_DLA

output_artistic_each_models
動画を指定の画風に変換する生成AIのアプリケーションを開発する
動画を絵画風のイラストへと変換するアプリケーションには「FP16で量子化されたDLA形式のAIモデル」が適していることがわかりましたので、このAIモデルを中心に、Neuron Runtime HelperとOpenCVを利用して動画を絵画風イラストへと変換するアプリケーションを実装してみましょう。アプリケーション全体の処理フローを以下に示します。
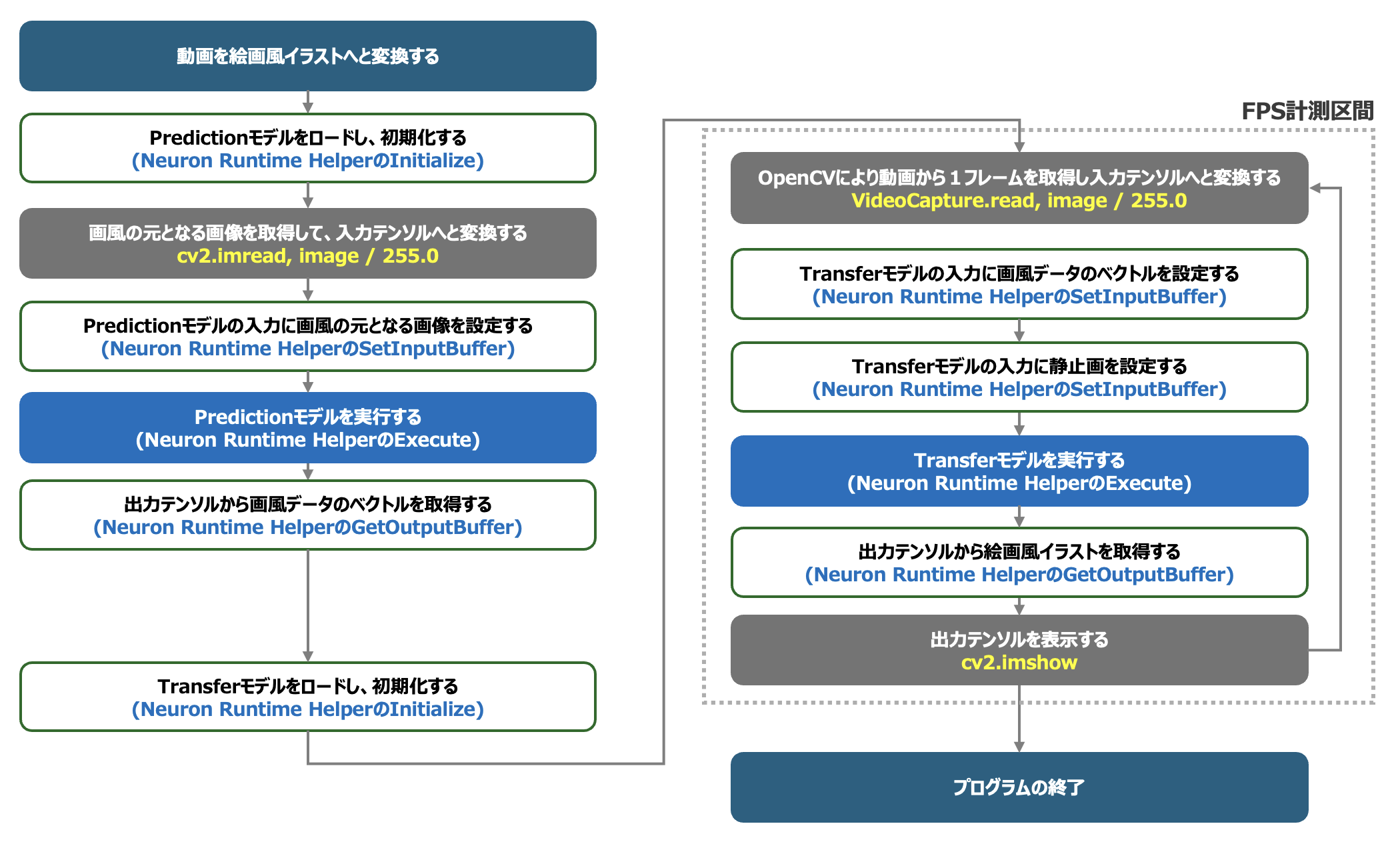
OpenCV_and_NeuronRuntimeHelper
まず、ソースコードからTensorFlowに依存するコードブロックを除外するため、入力テンソルを生成するためのPreProcess処理をOpenCVを利用して以下のように定義し直します。

また、出力テンソルを表示するPostProcess処理はOpenCVを使って以下のように定義します。

加えて、Transferモデルにより入力画像を画像を絵画風のイラストへと変換するメソッドを以下のように定義します。 use_model

Predictionモデルを実行して絵画の画像から画風データのベクトルを生成するメソッドは、以下のように定義します。

そして、PreProcessの処理と、PostProcessの処理、Neuron Runtime HelperによりTransferモデルを実行する処理を以下のように組み合わせることにより、下図のように動画を指定の画風へと変換するAIアプリケーションを実現することができます。このアプリケーションは19FPS程度で動作することが可能です。
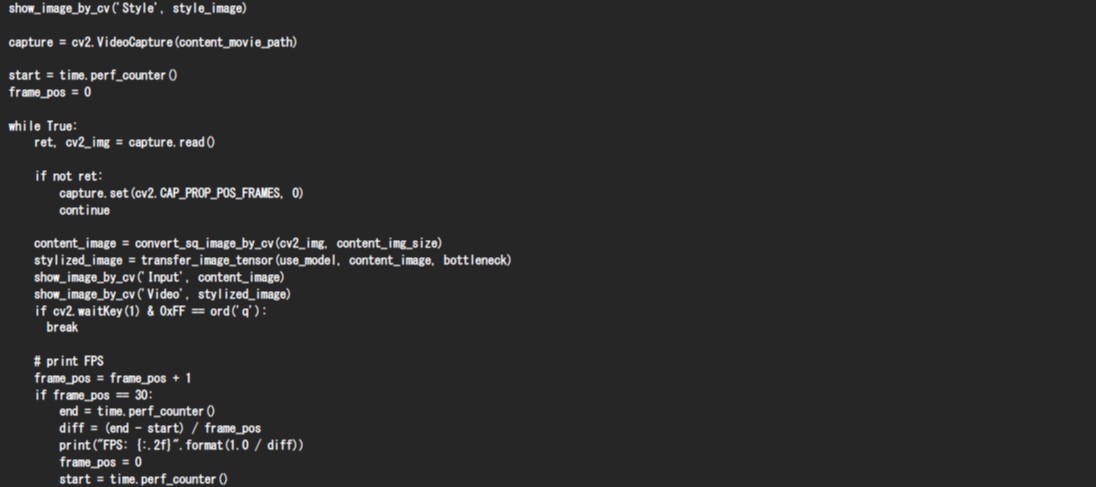
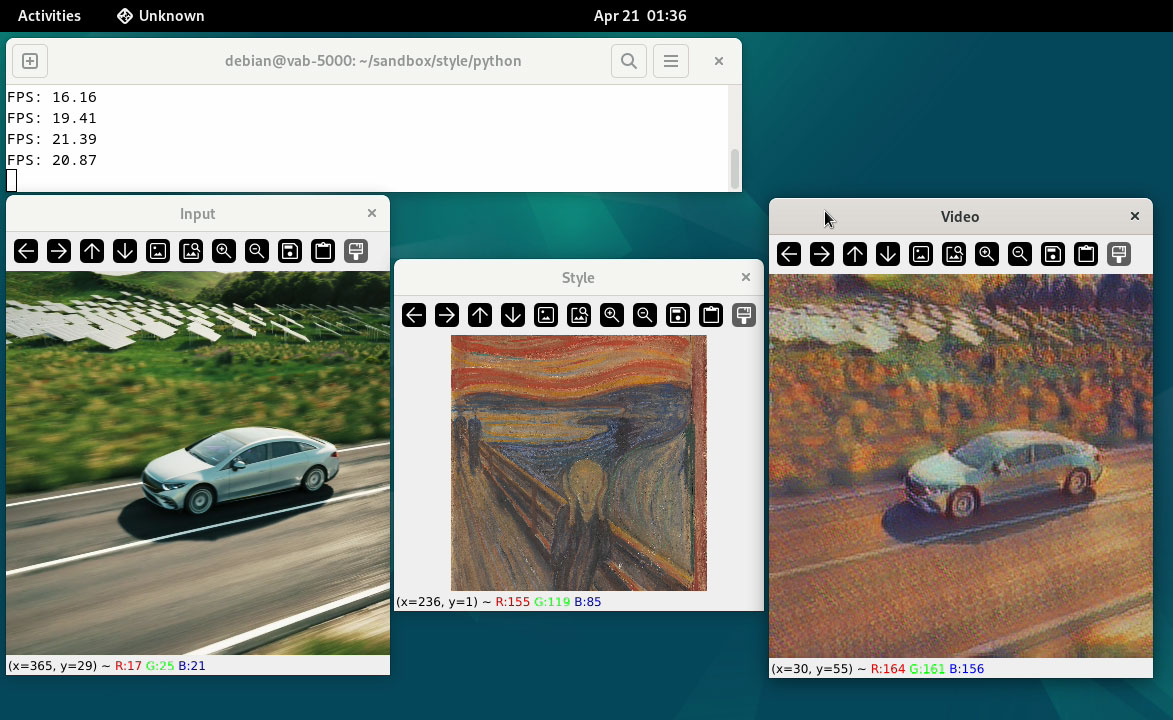
OpenCV_and_NeuronRuntimeHelper_Display

OpenCV_and_NeuronRuntimeHelper_Display_2
以上が、VAB-5000に統合されたAPU「MDLA」とMDLAをPythonから制御することのできるVIA独自の「Neuron Runtime Helper」を利用して、生成AI「arbitrary-image-stylization」をエッジのみでリアルタイムに実行する手順となります。
VAB-5000を活用して様々なAIアプリケーションを効率的に開発しよう
本記事で解説したようにVIAの「VAB-5000」を活用することにより、従来型のAIから、比較的演算リソースを多く必要とする生成AIまで、様々なAIモデルをエッジで実行することができます。またVIAのVAB-5000ではAPU「MDLA」を制御することのできるVIA独自のミドルウェア「Neuron Runtime Helper」により、Pythonコードのみで効率的にAIアプリケーションを開発することが可能です。是非、VIAの「VAB-5000」をエッジAIの開発にご活用ください。
VAB-5000