.png)
近年、産業分野におけるAIの活用が急速に拡大しています。そうした産業分野において、特に人気のあるアプリケーションの一つが「異常検知(AD:Anomaly Detection)」です。異常検知は、莫大なデータの中から通常のパターンから逸脱したデータを自動的に識別するAIの技術です。具体的には、機械学習のアルゴリズムを用いて、正常なデータのパターンを学習し、パターンから外れるデータを異常として検出します。AIを活用して実現した異常検知アプリケーションの強みは、事前に異常について綿密に定義しなくても、データの傾向から自動的に正常なデータと異常なデータの法則を確立できる点にあります。こうしたAIを活用した異常検知の技術は、製造業やインフラ管理、医療、金融など、さまざまなセクターで欠かせないツールとなっており、効率化やリスクの低減に大きく貢献しています。本記事では、製品画像に対して異常検知を行い、リアルタイムに不良品を特定するサンプルアプリケーションを、VIAのエッジAI向けプロダクトであるAMOS-9100やVAB-5000を活用して構築する流れについて解説します。
AMOS-9100やVAB-5000を活用した画像による異常検知
お忙しい方向けに、このページに掲載されている「AMOS-9100やVAB-5000を活用した画像による異常検知Podcast」の情報を、短時間でご理解いただけるよう音声で要約・解説します。通勤中や少しの休憩時間にご活用いただき、AI開発プロジェクトのヒントとしてお役立てください。
聴きどころ
製造・インフラで急増するAI異常検知。データから逸脱を自動識別し、効率化とリスク低減を実現する最前線。
Jetson搭載のAMOSとGenio搭載のVAB。現場要件に応じた最適なプラットフォーム選定を提案。
正常データのみで学習可能なオートエンコーダを採用。異常データ不足の現場でも迅速・低コストにAIを導入。
VAB-5000と分類器で302fpsの超高速処理を実現。高速ラインの全数検査に対応する性能を実証。
精度か速度か。再構成誤差と分類器の2手法を比較し、現場要望に応じた最適な実装戦略をデータに基づき提示。
異常検知が活用されているフィールド
異常検知は、リアルタイムの監視や予測が必要な場面で特に有効です。主なアプリケーションには以下のようなものが挙げられます。これらのアプリケーションは、AIによって人間の目では捉えにくい微細な変化を高速に検出することにより、コスト削減や信頼性の向上を貢献します。
製造業:生産ラインでの機器故障の予知保全。例えば、センサーから得られた振動や温度の変化から異常を検知し、ダウンタイムを防ぎます。
インフラ管理:電力網や橋梁などの構造物監視。異常な振動から劣化を早期に発見し、安全性を確保します。
医療:患者のバイタルデータ監視。心拍や血圧の異常を検知し、緊急対応を促します。
金融業:不正取引の検知。取引パターンの異常をリアルタイムで識別し、詐欺を防止します。
サイバーセキュリティ:ネットワークトラフィックの異常を検知し、侵入や攻撃を防ぎます。
本記事の流れ
本記事は、画像を基に異常検知を行うアプリケーションの構築方法について解説します。解説に先立ち、異常検知を行うAIで広く活用されているオートエンコーダの技術についてまず説明し、オートエンコーダを用いて異常を選出する方法を紹介します。本記事では、オートエンコーダにより異常を検知する方法のうち、二つのアプローチ、再構成誤差を活用した異常検知の方法と、潜在変数に対して分類器を適用する異常検知の方法を紹介します。最後にこうしたアプローチを踏まえて、実際に異常検知のアプリケーションを実装する方法を紹介します。まず、VIA AMOS-9100上に再構成誤差に着目した異常検知アプリケーションを構築する方法を解説し、そして次に、VIA VAB-5000上に潜在変数に着目した異常検知アプリケーションを構築する方法を解説します。以上の内容から、本記事を通してVIAの組み込みAI向けプラットフォームであるAMOS-9100やVAB-5000が、異常検知を行う高度なアプリケーションの構築にも利用いただけることをお見せ致します。
再構成誤差を活用した異常検知
本記事では、まず、再構成誤差を活用して異常検知をする方法をご紹介します。再構成誤差を活用した異常検知は、正常な画像のみで学習したオートエンコーダを利用します。正常な画像のみで学習したオートエンコーダに正常な画像を入力すると、オートエンコーダを構成するエンコーダとデコーダは、入力された画像と誤差の少ない画像を生成します。一方で、異常な画像をオートエンコーダへ入力すると、オートエンコーダが正常な画像のみで学習されている理由から、デコーダは異常を含んだ画像を生成することができず、入力した画像と大きく異なる画像が生成されます。これにより、正常な画像に対する再構成誤差は小さくなり、異常な画像に対する再構成誤差は大きくなります。こうした特性から、再構成誤差を用いて異常を検知することができます。
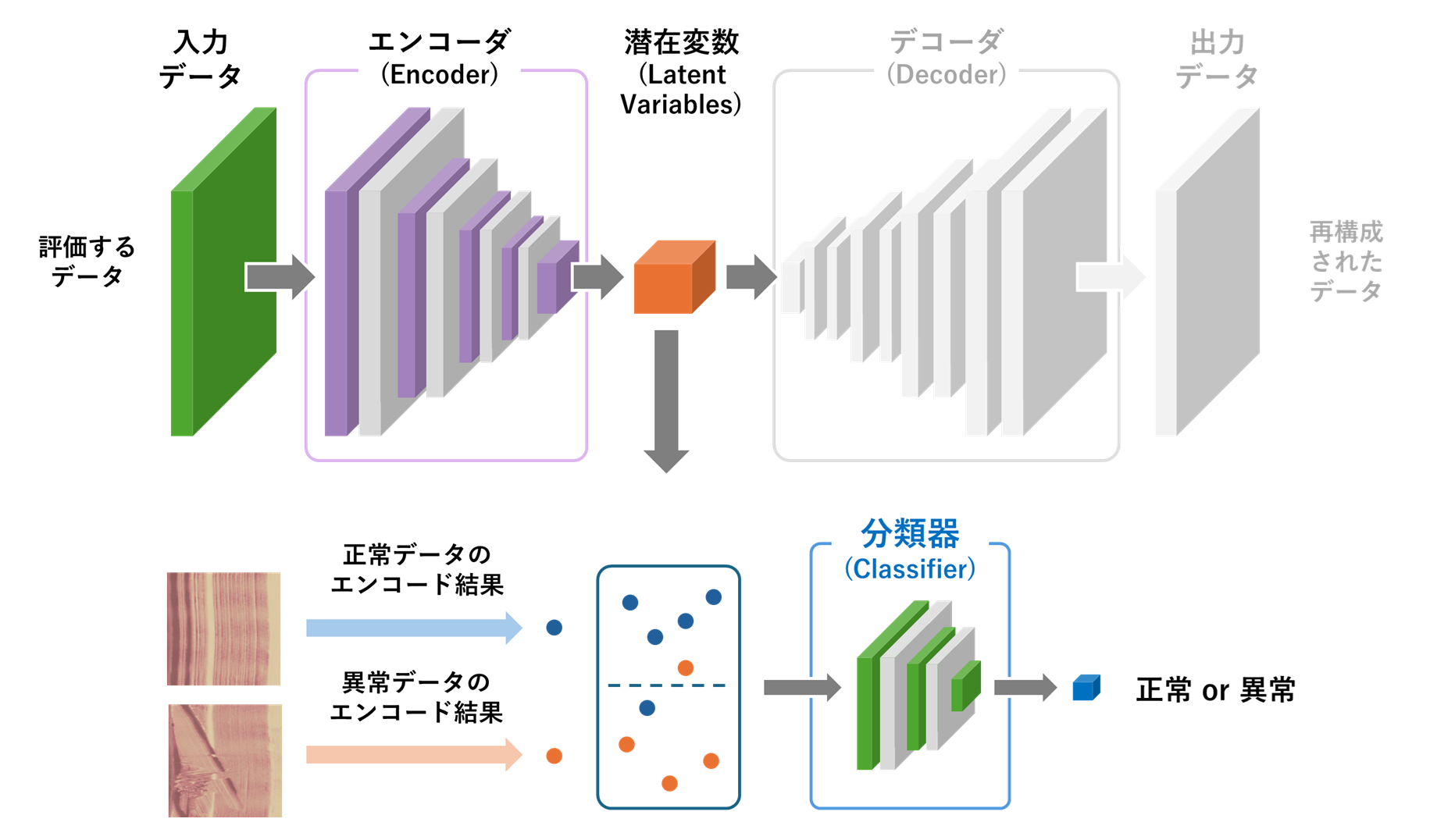
潜在変数に対して分類器を適用する異常検知の
本記事では、二つ目の異常検知の方法として、オートエンコーダにより生成できる潜在変数に対して、分類器(Classifier)を適用して正誤判定を行う方法をご紹介します。オートエンコーダのエンコーダが生成する潜在変数は、入力された画像の特徴を色濃く残した変数であり、分類器を扱うアプローチでは、この変数の分布に着目します。このアプローチでは、潜在変数を入力として、それが正常か異常のどちらであるかを出力する分類器を定義します。そして、この分類器を、正常な画像の潜在変数と異常な画像の潜在変数を使って学習します。この一連の流れにより、オートエンコーダのエンコーダと分類器を利用して、入力された画像が正常か異常かを識別することができるようになります。このアプローチは、潜在空間の特徴を活用し、より複雑な異常パターンを捉えやすい点が特徴です。
リッチなIOとレガシーIOを兼ね備えたVAB-5000
本記事で扱うデータセット
本記事では、異常検知の対象となるデータとして、BTAD(BeanTech Anomaly Detection Dataset)を用います。BTADは、2021年にイタリアのbeanTech社とウディネ大学によって公開された実世界の産業向け異常検知データセットであり、産業現場での製品欠陥検出を目的とした異常検知のアプリケーションあるいは異常部位を局所化するアプリケーションの構築に適しています。本記事では、BTADに含まれる3種類の製品画像のうち、木工製品の木目に注目したProduct2(下図)を扱い、製造された製品の木目(テクスチャ)が正常か異常を判定するサンプルアプリケーションを開発します。なお、BTADは、Creative Commons Attribution-ShareAlike 4.0 International(CC BY-SA 4.0)ライセンスのもとで公開されており、商業目的のプロジェクト、製品、サービスなどで自由に利用することのできるデータセットです。なお、BTAD Product2 は600×600ピクセルの画像ですが、本記事で紹介するアプリケーションでは、畳み込み演算で扱いやすいように、2の累乗である512×512ピクセルの画像へと縮小して扱います。

Product2_OK_KO_samples
オートエンコーダを活用した異常検知
本節では、実際のアプリケーションの開発を始める前にまず、異常検知を実現するAIが広く採用しているオートエンコーダの技術について説明します。次に、オートエンコーダがどのように異常検知に寄与できるのかを紹介し、最後にオートエンコーダの実行に適したハードウェアアクセラレータについて解説します。
オートエンコーダの動作とその特徴
本記事にて構築する異常検知を行うアプリケーションは、ニューラルネットワークの一種である「オートエンコーダ(Autoencoder)」を活用します。オートエンコーダは、非教師あり学習の手法として用いられるモデルです。オートエンコーダの目的は、低次元の潜在変数(Latent variables)へと圧縮した入力データを、誤差なく元の次元のデータに再構成する機能を獲得することです。オートエンコーダは学習を通して、データの特徴をモデル自身に記憶させ、自己符号化機能を備えたモデルを生成します。オートエンコーダは、エンコーダ(Encoder)とデコーダ(Decoder)の2つの部分から構成され、入力データと出力データの差分(再構築誤差:MSE:Mean Squared Error)を最小化するように訓練されます。この訓練により、学習後のオートエンコーダは、学習を通してデコーダに記憶された正常なデータ固有のパターンを備えた出力データを生成できるようになります。オートエンコーダが保持する正常なデータ固有のパターンにより、オートエンコーダはノイズの除去や異常検知などのタスクに活用することが可能です。
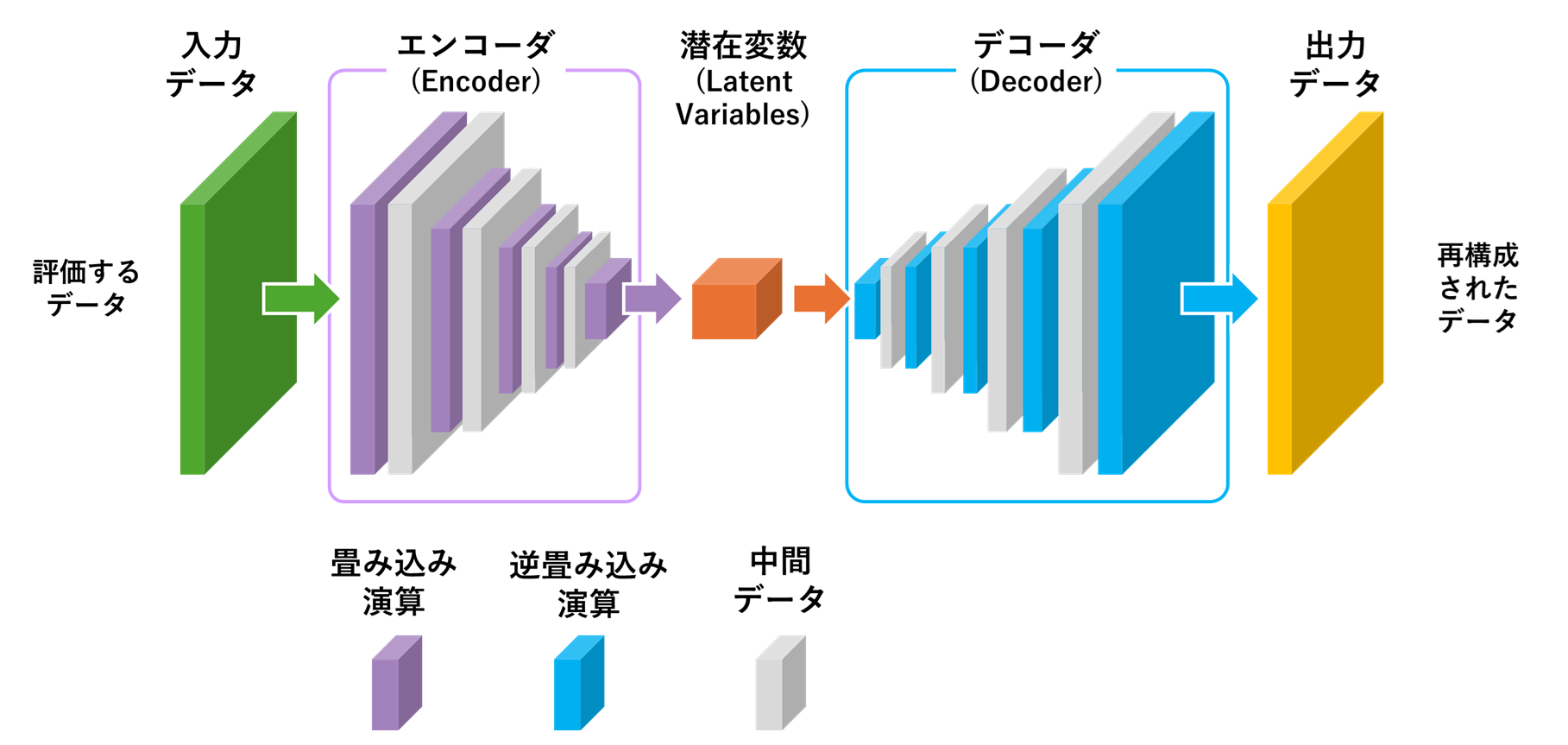
AutoEncoder
エンコーダの動作
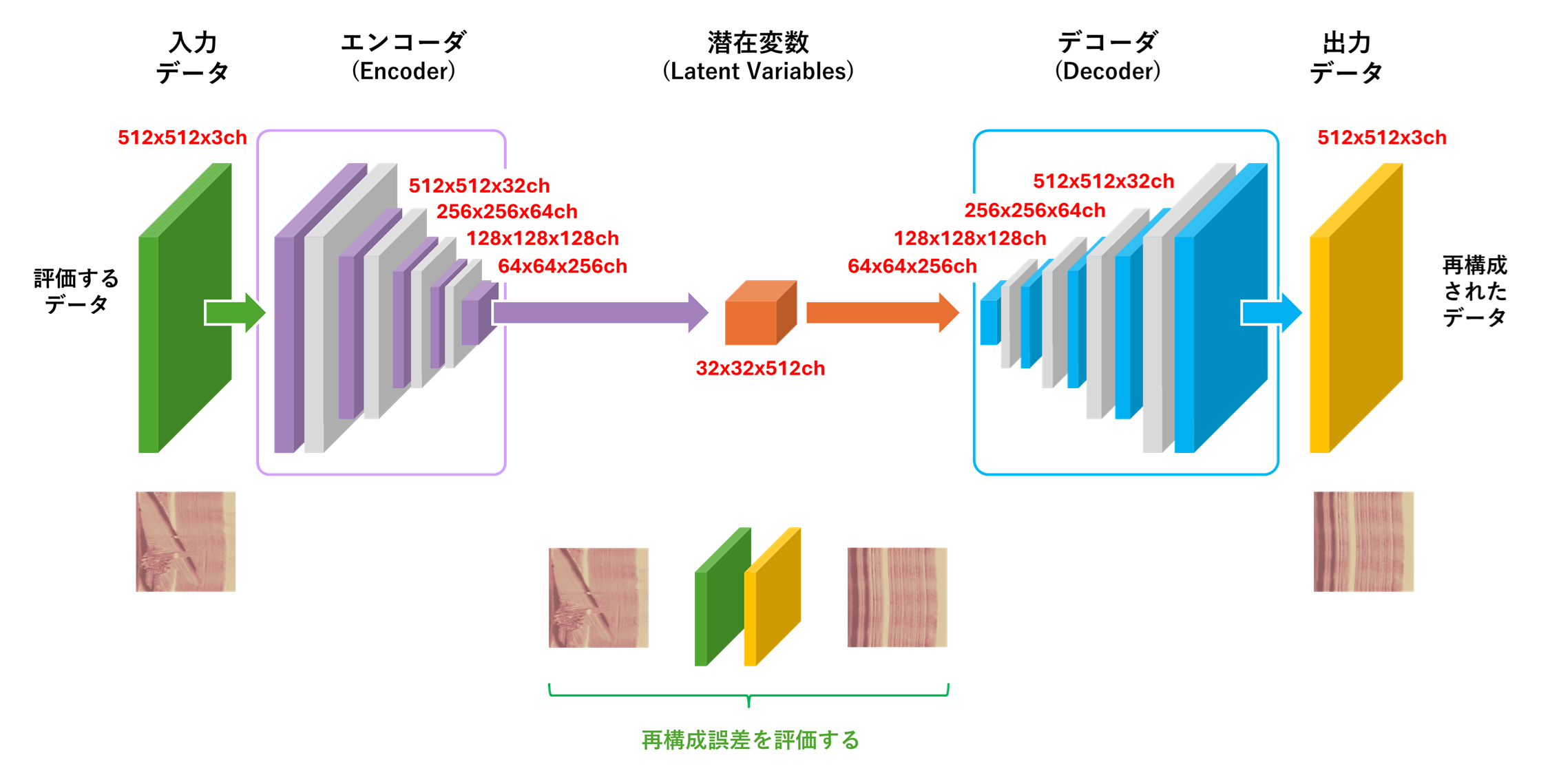
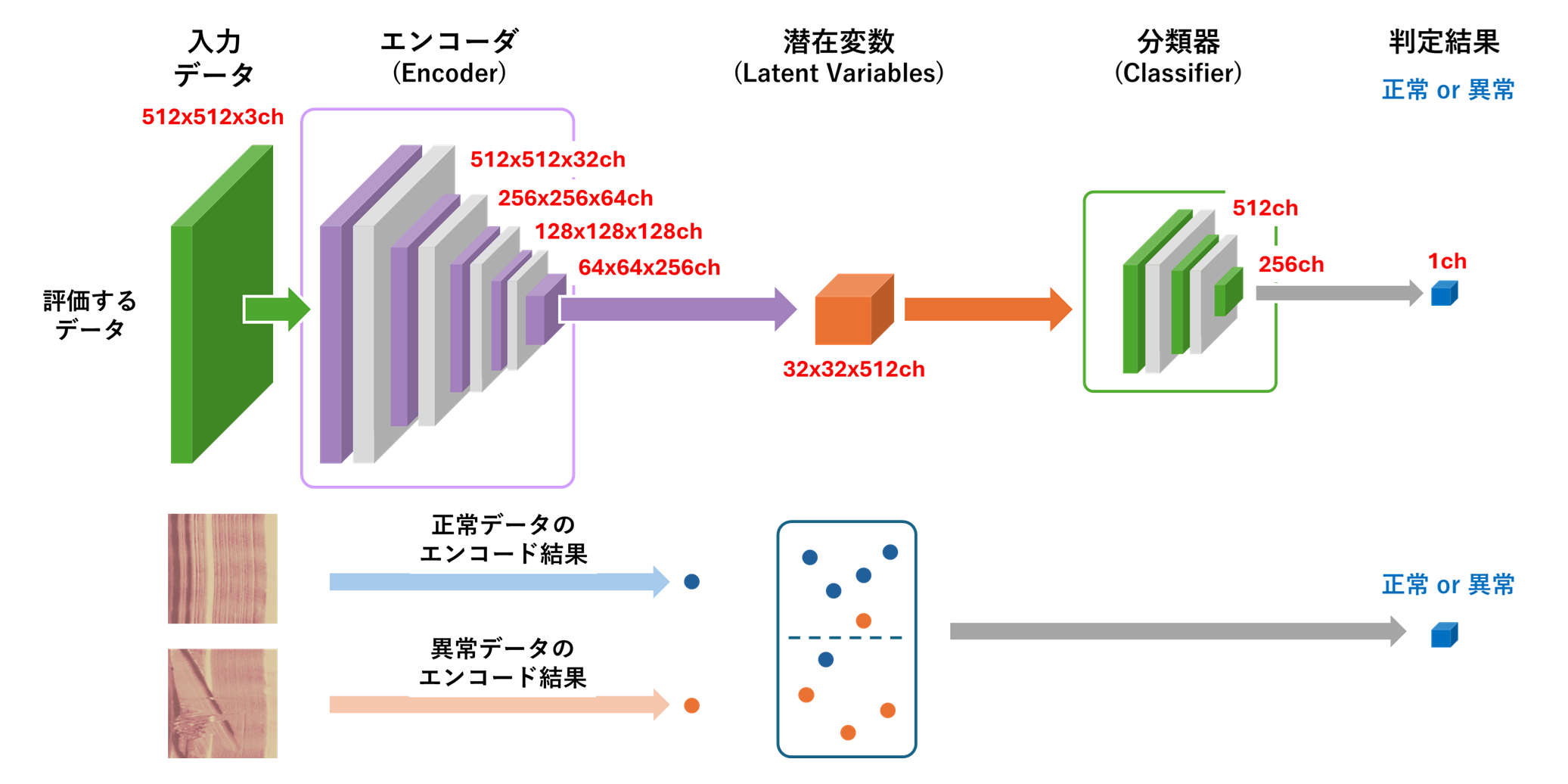
エンコーダ(Encoder)は、オートエンコーダの前半部分で、入力データを低次元の潜在変数に圧縮する役割を担います。具体的には、画像などの入力データを複数の層からなるニューラルネットワークを通じて処理し、次元を徐々に減らしていきます。本記事で紹介するアプリケーションを構成するエンコーダでは、BTADのProduct2から抽出した512×512ピクセルの画像を、畳み込み演算により32×32次元のベクトルへと圧縮します。圧縮の際にエンコーダは、データの本質的な形状やパターンといった特徴を入力画像から効率的に抽出し、効率的に特徴を保持できる潜在変数を生成しようとします。特に、オートエンコーダ全体の自己符号化機能によりデコーダで復元することのできる情報は冗長であるため、エンコーダはこうしたデータを圧縮の際に除外し、効率的に情報を表現できる潜在変数を生成します。エンコーダは学習フェーズにて入力画像を低次元な潜在変数へと圧縮しても再構築誤差を最小化できるような畳み込み演算のパラメータ(重み、バイアス)を選出します。
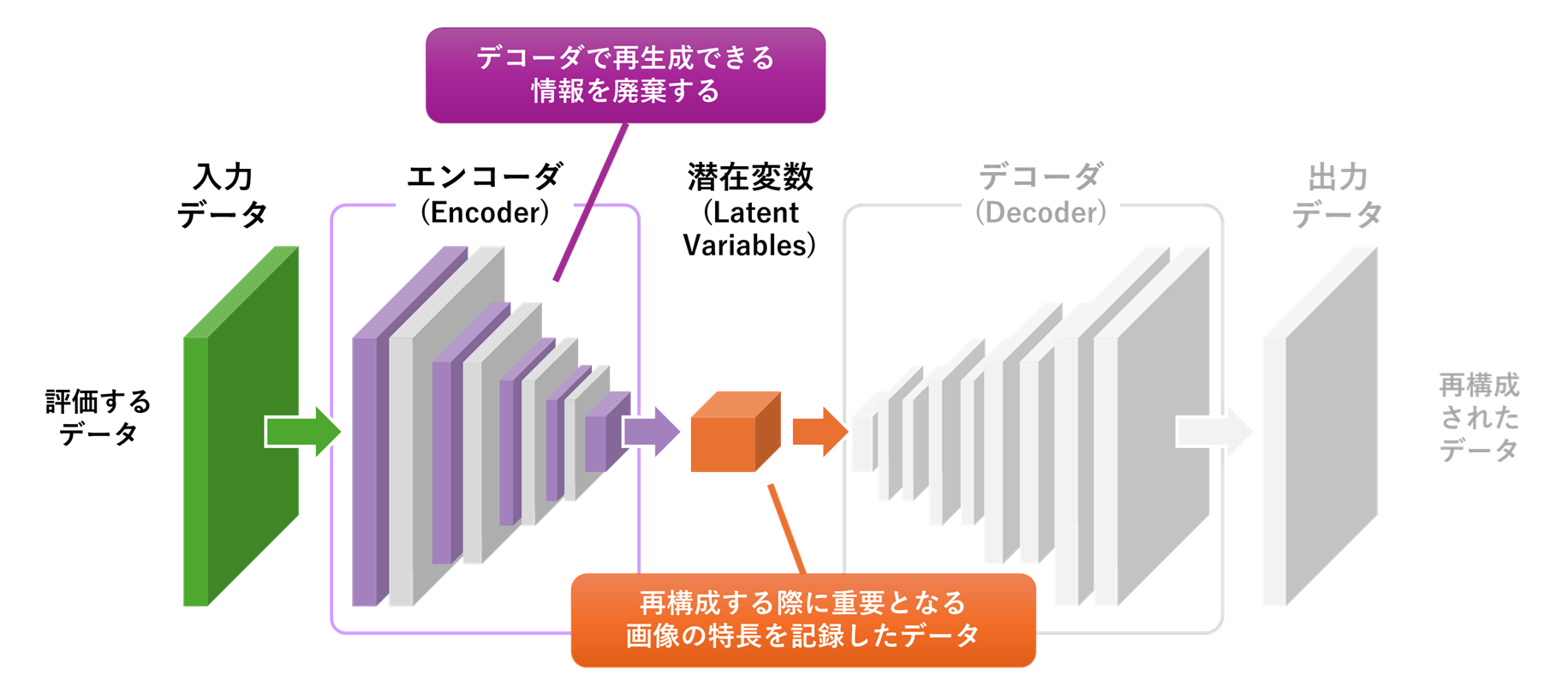
Encoder_in_AutoEncoder
デコーダの動作
デコーダ(Decoder)は、オートエンコーダの後半部分で、エンコーダによって生成された潜在変数を、元の入力データに近い出力データへと再構築する役割を果たします。エンコーダの出力である潜在変数を入力として、ニューラルネットワークの層を通じて次元を徐々に増やし、元のデータ形式に戻します。本記事で紹介するアプリケーションのデコーダは、エンコーダが圧縮した32×32次元の潜在変数に対して、逆畳み込み演算を加え、512×512ピクセルの画像を再生成します。この動作により、オートエンコーダのモデル全体が入力データを自己符号化できるようになり、学習を通じてデコーダは潜在変数とエンコーダの処理により失われた情報を復元する能力を獲得します。通常、エンコーダとデコーダは対称的な構造を持ち、オートエンコーダ全体として入力データと出力データの一致を目指します。
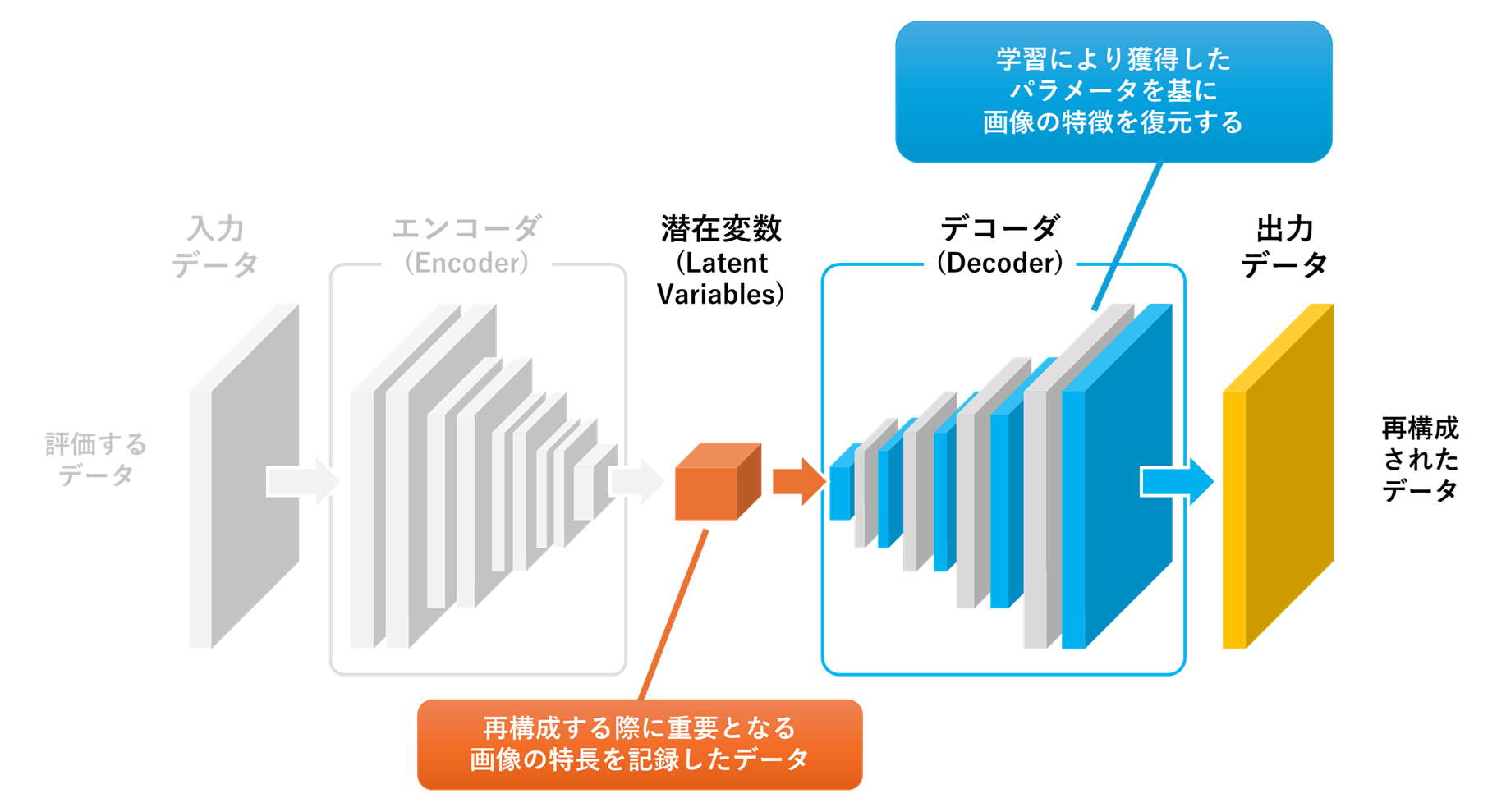
Decoder_in_AutoEncoder
潜在変数の意味
潜在変数は、エンコーダによって入力データから抽出された低次元のベクトル表現で、オートエンコーダのボトルネック部分に相当します。これらはデータの隠れた構造や本質的な特徴を表すもので、高次元な入力データを低次元に圧縮した形で保持しています。低次元であっても潜在空間の質が高ければ、類似データのクラスタリングや、正常データに対する再構成誤差の低減が可能になり、入力データをより精密に分析できるようになります。
オートエンコーダを異常検知に活用する方法
オートエンコーダを正常な製品画像のみを含むデータセットを用いて学習させることにより、オートエンコーダは、入力された画像を正常なデータのパターンに沿って圧縮し、再び入力データを復元できるように最適化されます。学習時に異常な画像を一切含めないことにより、オートエンコーダのモデルに正常データとはどのような特徴を持つものなのかを記憶させ、正常データの再構成のみに特化した自己符号化機能を獲得させます。
再構成誤差に着目して異常を検知する
正常なデータのみで学習されたオートエンコーダへ正常な画像を入力した場合、入力画像を高い精度で再構成することが可能です。一方で、異常な製品画像、例えば傷、欠陥、異物混入などが含まれる画像を入力した場合、オートエンコーダの学習した正常パターンに基づいて画像を再構成しようとする機能により、異常部分を無理やり正常であるかのように修正しようとする作用が働き、結果として入力画像と出力画像の間に大きな誤差が発生します。こうして発生した入力と出力の差分である再構成誤差の大きさを指標とすることで、異常検知を実現することができます。本記事で紹介するアプリケーションでは、再構成誤差として入力画像と再構成画像の差分から算出した画像全体のMSE(Mean Squared Error)を用いて異常判定を行っています。
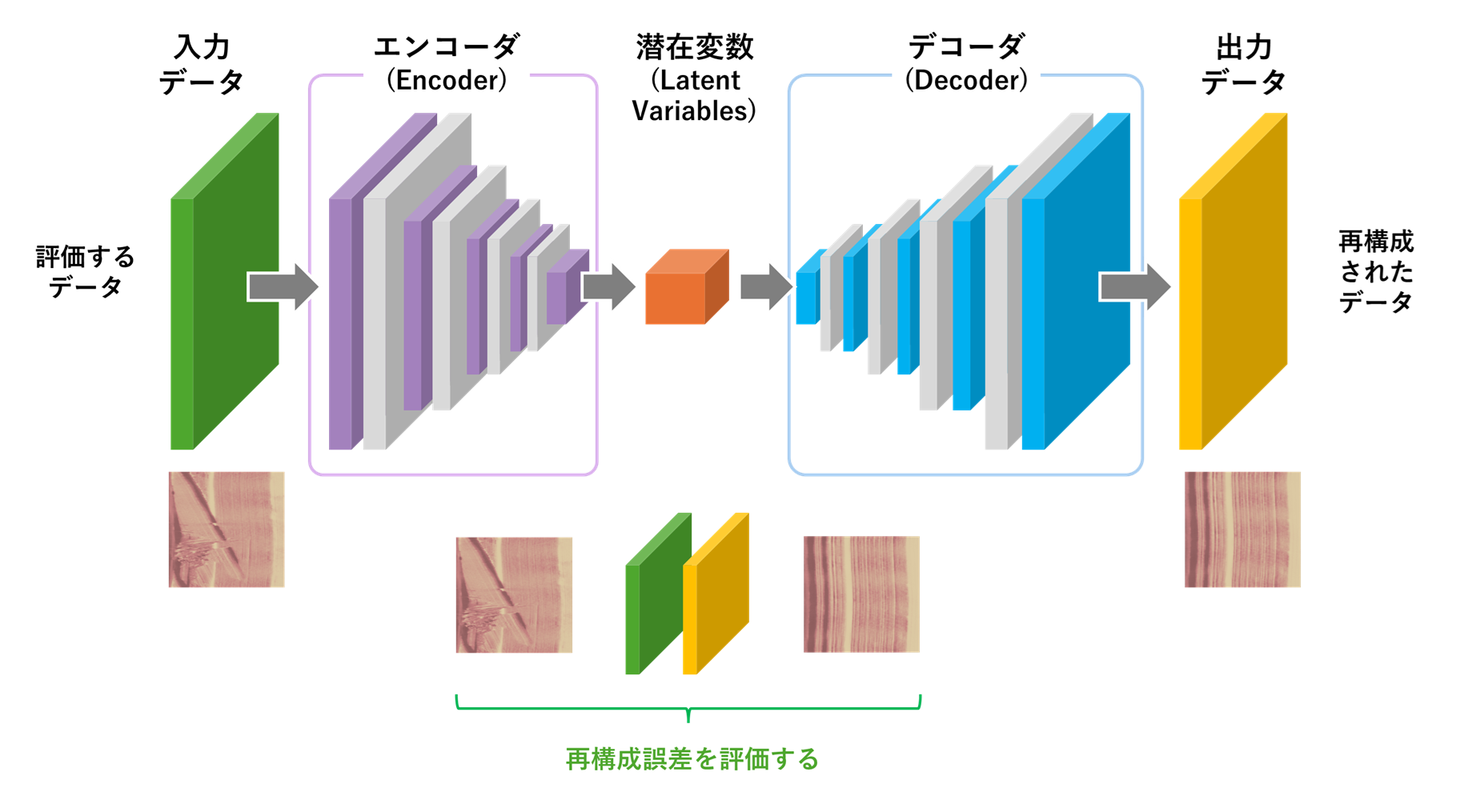
MSE_for_AutoEncoder
潜在変数に着目して異常を検知する
さらに、オートエンコーダを活用した異常検知の手法には、単に入力と出力の画像を比較する手法だけでなく、潜在変数に利用する手法もあります。潜在変数は、入力画像の重要な特徴を低次元で圧縮した表現であり、正常な画像に対しては特定の分布に従った値を取る傾向があり、一方で、異常な画像ではこの分布から大きく外れた値となります。このことから、潜在変数の空間において、あらかじめ正常データの分布を統計的にモデル化しておき、正常データの分布からのずれを一定の閾値で判定することでも、高精度な異常検知を実現することが可能です。
Clasifier_for_AutoEncoder
AMOS-9100とVAB-5000に搭載された演算リソースと異常検知の関係
オートエンコーダの実装には、エンコーダで次元を落としていく演算と、デコーダで次元を復元していく演算の両方が必要になります。Jetson Orin NXをベースとしたVIA AMOS-9100は、演算リソースとして「GPU」を活用することで、エンコーダとデコーダの双方を構成するそれぞれの演算を高速に実行することが可能です。一方、VIA VAB-5000に搭載されたAI向けの演算リソース「MDLA」は、エッジAIで頻出する演算に特化して高速化する設計となっており、畳み込み演算に強く、逆畳み込み演算に弱いことから、エンコーダの高速化のみを得意としています。このため、VAB-5000上に構築するアプリケーションでは、デコーダを搭載しない方が望ましいと考えられます。こうした理由から、本記事ではAMOS-9100向けにはエンコーダとデコーダを利用して再構成誤差に着目して異常を検知するアプリケーションを構築し、VAB-5000向けにはエンコーダと分類器を利用して潜在変数に着目して異常を検知するアプリケーションを構築しました。なお、本記事では処理速度の比較のために、AMOS-9100上にもエンコーダと分類器を利用して異常検知を行うアプリケーションを実装しました。
異常検知アプリケーションの精度を評価する指標
異常検知アプリケーションは二値分類問題であり、予測結果と実際のラベルを比較することにより精度を算出します。異常検知では、異常を「Positive(陽性)」と呼び、正常を「Negative(陰性)」と呼びます。異常検知では、まず、データセットに対する予測結果と実際のラベルを基に混同行列(Confusion Matrix)を作成し、次に混同行列に含まれる値から、精度の指標となるAccuracy(精度)、Precision(適合率)、Recall(再現率、感度)を算出することにより、アプリケーションを評価します。
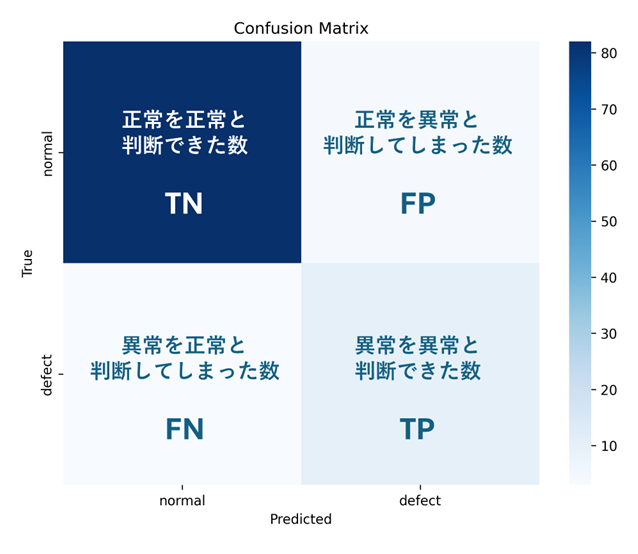
混同行列(Confusion Matrix)
混同行列は、分類モデルの予測結果を実際のラベルと比較してまとめたテーブルです。異常検知の評価の基盤となり、精度を算出するために利用されます。行が実際のクラス、列が予測されたクラスを表します。
TN (True Negative):正常を正常と正しく予測した数。正常データを正しく無視できた回数。
TP (True Positive):異常を異常と正しく予測した数。異常を検知成功できた回数。
FP (False Positive):正常を異常と誤予測した数。誤警報が発生した回数。
FN (False Negative):異常を正常と誤予測した数。異常を見逃した回数。
confusion_matrix
異常検知のアプリケーションを評価する指標
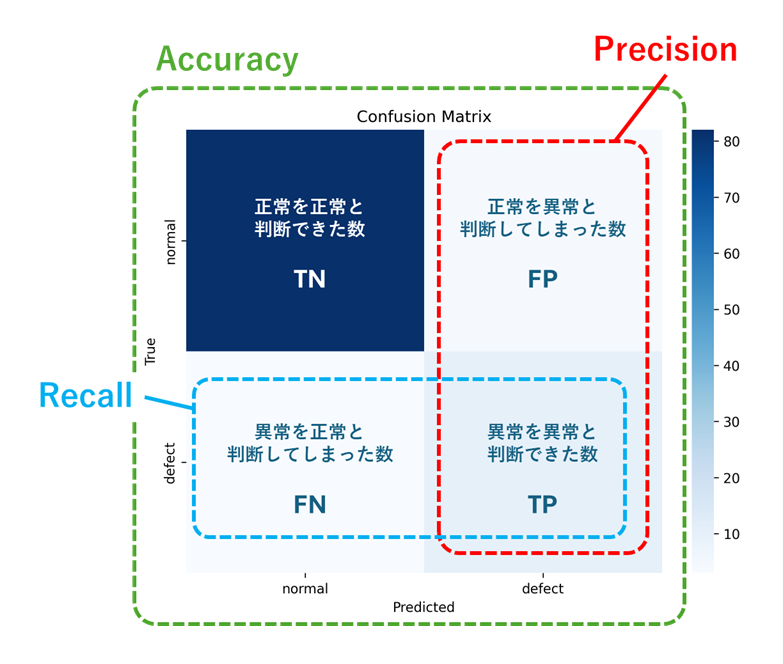
異常検知のアプリケーションを評価する指標には、画像認識等で広く利用されるAccuracyに加えて、PrecisionやRecallなどがあります。精度の評価は、二値分類問題として扱われますが、異常検知のアプリケーションを評価する場合、データが不均衡で異常のサンプル数が少ない場合が多いため、データが不均衡な場合においても高い感度を示す「Precision」や「Recall」といった指標を選ぶことが重要です。それぞれの意味と算出方法は以下の通りです。
Accuracy (精度)
全体の予測のうち、正しく分類された割合。
計算式: (正しく予測した正常(TN) + 正しく予測した異常(TP)) / 全データ数(TN+TP+FP+FN)
Precision (適合率)
異常と予測したものの中で、実際に異常だった割合。誤検知(False Positive)を評価する場合に重要。
計算式: 真の異常 (TP) / (真の異常 (TP) + 誤って異常と予測した正常 (FP)
Recall (再現率、感度)
実際に異常だったものの中で、正しく異常と予測した割合。異常の見逃し(False Negative)を評価する場合に重要。
計算式: 真の異常 (TP) / (真の異常 (TP) + 誤って正常と予測した異常 (FN))
Accuracy_Precision_Recall
さらなる評価指標
なお、異常検知の評価では、再構成誤差や分類器の出力スコアに対して、判定時に用いる閾値を変化させながら性能を評価する、AUROC(Area Under the ROC Curve)のような閾値に非依存な指標も広く用いられています。本記事では混同行列に基づく指標を用いて評価を行っていますが、今後はこうした指標を用いて評価することも可能です。
x86_64上のTensorFlowでオートエンコーダの定義と学習を行い、AMOS-9100向けの異常検知アプリケーションを開発する
まず、オートエンコーダと、その入出力の再構成誤差に着目して異常検知を行うアプリケーションをAMOS-9100上に実装してみましょう。このアプリケーションの開発では、まずx86_64のUbuntu 24.04上でオートエンコーダのモデルの定義と学習を行い、学習結果からAMOS-9100に適したTensorRTのモデルを生成します。その後、AMOS-9100向けに生成したTensorRTのモデルをAMOS-9100上のGPUを使って実行し、再構成誤差を評価。異常検知を行うアプリケーションを実現します。
再構成誤差に着目した異常検知アプリケーションを構築する
本アプリケーションのAIモデルでは、オートエンコーダに含まれるエンコーダが、入力データである512x512x3ch(RGB)ピクセル3chの画像に対して畳み込み演算を繰り返し適用し、データを512x512x32ch、256x256x64ch、128x128x128ch、64x64x256ch、32x32x512chへと圧縮。32x32x512chの潜在変数を生成します。その後、デコーダが潜在変数に対してエンコーダと逆の変換を行い512x512x3ch(RGB)の画像を再構成します。このAIモデルをBTADに含まれる正常ラベルが付与された画像のみで学習することにより、BTAD Product2に適した自己符号化機能を備えたアプリケーションを実現します。
こうして学習の済んだオートエンコーダは、BTAD Product2に含まれる正常な画像が入力された場合、最適化された自己符号化機能により、正常な画像をほとんど誤差なく画像を圧縮して再構成することができます。一方で、異常な画像が入力された場合は、オートエンコーダの持つ自己符号化機能により、画像の異常個所が修復され、あたかも正常な画像が入力されたかのような出力を生成。結果として、異常データが入力された場合にのみ、入力画像と出力画像の間に大きな誤差が発生します。この特徴を利用し、再構成誤差を評価することで、異常を検知するアプリケーションを実現します。
MSE_for_AMOS-9100
推論速度
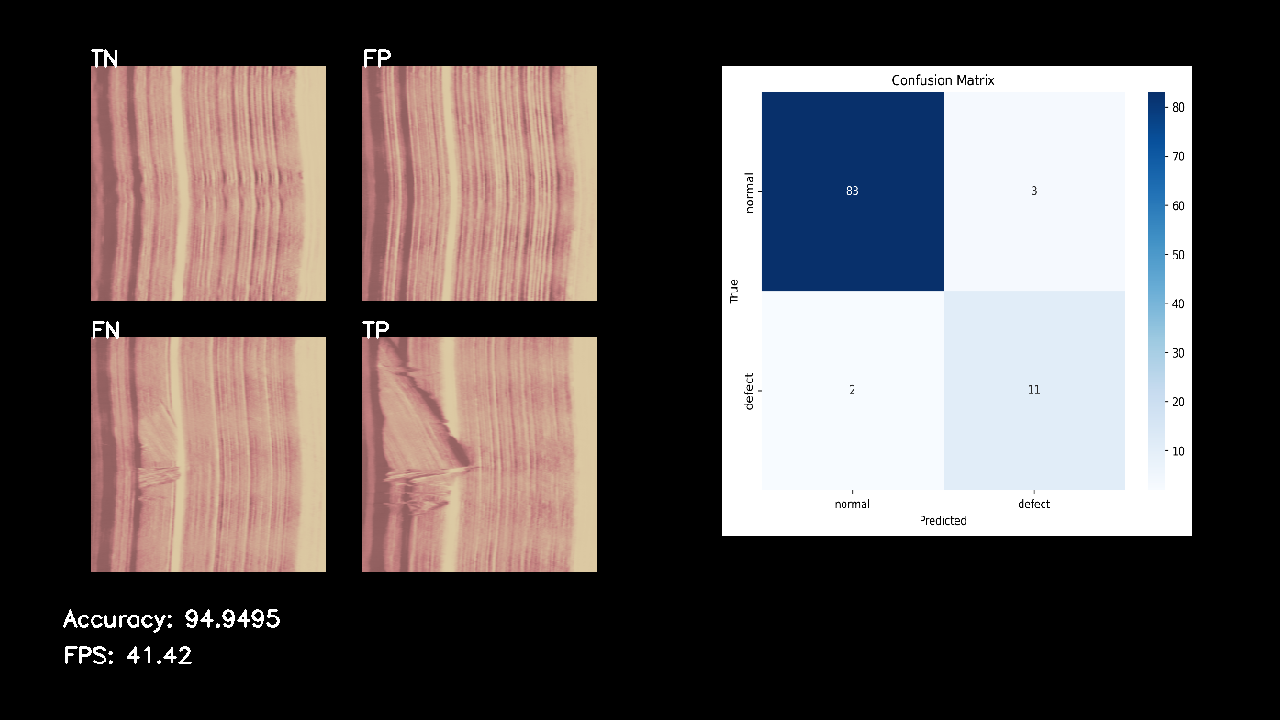
このアプリケーションの推論速度は、オートエンコーダに画像を入力してから、その画像がオートエンコーダによって再構成され、出力画像が生成されるまでの時間、そして入力画像と出力画像の間の再構成誤差を計算し、その誤差値があらかじめ設定した閾値を超えているかどうかを判断するまでの一連の処理時間によって決定されます。今回構築したアプリケーションにおいては、この全体の処理速度は41fpsという結果になりました。
このアプリケーションの入力画像から出力画像を再構成するまでの処理は、ループのない機械的な計算によってのみ行われるため、実行時間のばらつきはほとんど生じません。また、再構成誤差を計算する時間や、その誤差値を評価して閾値と比較する処理にかかる時間も、基本的に一定です。したがって、この測定された推論速度は、ほぼ確定的で再現性の高い値であると言えます。もし今後、このアプリケーションの処理速度をさらに高速化したい場合には、オートエンコーダのモデルの構造を見直すことが有効であると考えられます。特に、潜在空間の次元数(ボトルネック部分のサイズ)を小さくする、ネットワークの層数を減らすといった工夫が、推論速度の向上に大きく寄与するでしょう。
AMOS-9100_exec_image
TensorRTによる高速化
なお、AMOS-9100はNVIDIA製GPUを搭載した組み込みAIプラットフォームです。そのため、今回の開発では、x86_64環境上のTensorFlowで作成したAIモデルを、NVIDIA GPUに最適化されたTensorRTフレームワーク向けにエクスポートすることで、AIモデルをアーキテクチャに最適化し、高速化を実現しました。なお、x86_64環境であってもNVIDIA GPUを搭載していれば、同じようにTensorRTによる高速化の効果を体験することができます。
推論精度
今回構築したアプリケーションを、BTAD Product2のうち、学習に利用しなかったテスト用データを用いて異常検知の精度を評価したところ、以下のような結果となりました。再構成誤差に着目するアプローチにより、高いRecallを実現できていることがわかります。
Accuracy = 94.9%
Precision = 68.8%
Recall = 84.6%
AMOS-9100_confusion_matrix
正常を異常と判断してしまった理由
今回構築した異常検知アプリケーションを実行した結果、製品画像が正常であるにもかかわらず、異常であると判断される状況が発生しました。誤検知された製品画像を、正常と正しく判断された製品画像と比較したところ、誤検知された画像には、画像左側に位置する木目の領域に白いモヤのような明るさがかかっている特徴が見られました。この白いモヤは、正常画像群には見られない違いであり、学習時に使用した正常データには含まれていなかった外観のばらつきであると考えられます。改善策としては、正常データの収集時に照明ムラや白いモヤが発生する条件も含めた多様な正常画像を追加で学習させる手法や、照明条件を変えて入力画像のコントラストを調整し、外観のばらつきに対するロバスト性を向上させる手法などが有効であると考えられます。

Correct_but_output_is_Anomaly
異常を正常と判断してしまった理由
今回構築した異常検知アプリケーションにおいて、異常のある製品画像が正常であると誤って判断される状況も発生しました。誤判定された画像を正常な画像と比較したところ、画像右側に、正常製品とほぼ同等の木目パターンが含まれていました。正常に近い木目領域が画像全体の大部分を占めていたため、再構成ベースのモデルが画像全体を比較的正確に復元でき、再構成誤差が小さくなったものと推測されます。今後の改善策としては、異常検知の際に画像全体の誤差だけでなく局所的な誤差分布を評価する注目領域の重み付けの仕組みを導入することや、異常サンプルを活用した教師あり学習を組み合わせることが効果的であると考えられます。

Anomaly_but_output_is_Correct
x86_64上のTensorFlowでオートエンコーダの定義と学習を行い、VAB-5000向けの異常検知アプリケーションを開発する
次に、オートエンコーダを使った異常検知アプリケーションをVAB-5000上で実装してみましょう。このアプリケーションを実現するには、まずx86_64アーキテクチャのUbuntu 24.04環境で、オートエンコーダと分類器を定義します。そして、正常なデータでオートエンコーダの学習を行い、正常なデータと異常なデータを用いて分類器の学習を行います。そして、オートエンコーダのエンコーダが算出した潜在変数を分類器に入力することで異常検知を実現します。なお、分類器の学習は、入力画像に加えて、その画像が正常か異常かを示すラベルを必要とする、教師あり学習です。x86_64上での学習が完了したら、分類器と、オートエンコーダに含まれるエンコーダをAIモデルとしてエクスポートし、結合します。そして、これらをVAB-5000向けとして、MediaTek SoCに搭載されたハードウェアアクセラレータMDLA(MediaTek Deep Learning Accelerator)に対応したDLA形式のモデルへと変換します。DLA形式へと変換したモデルをVAB-5000にデプロイすることで、MDLAを活用した高速かつ効率的な異常検知アプリケーションを実現できます。以上の手順により、x86_64環境で柔軟にモデル開発を行いながら、VAB-5000のハードウェア性能を最大限引き出したエッジAIアプリケーションを構築できます。
潜在変数に着目した異常検知アプリケーションを構築する
アプリケーションを構築するには、まず、BTAD Product2の正常データのみを利用した学習により、オートエンコーダが正常データを適切に再構成できるようにします。これにより、正常な入力画像のデータと、エンコーダの出力である潜在変数の間に相関が生まれます。次に、デコーダ部分を無効化し、学習済みのエンコーダを利用して正常画像と異常画像に対応する潜在変数を生成し、生成した潜在変数とそれぞれの入力データに対応する正誤ラベルを分類器向けの学習データとして準備します。最後にこの学習データを使って分類器の学習を行い、入力データが潜在変数を経て正誤判定に繋がる流れのAIモデルを構築します。ここで注意しなければならないのは、分類器を学習する際の学習は教師あり学習である、という点です。そのため、再構成誤差を用いた異常検知アプリケーションのモデルの学習には正常な製品画像の入力データのみがあれば十分でしたが、分類器をつかったアプリケーションのモデルの学習には、正常な製品画像の入力データに加えて、ある程度の量の異常な製品画像の入力データが必要となります。
Clasifier-_for_VAB-5000
Neuron Runtime Helperによる高速化
VIAのVAB-5000のDebian環境ではPythonコードから、VAB-5000の核となるSoC Genio-700に搭載されたAI向けハードウェアアクセラレータの「MDLA」を利用することができます。MDLAを利用するには、まずx86_64環境上で、エンコーダと分類器をセットにしたAIモデルをTensorFlow Lite形式のモデルへと変換します。次に、VAB-5000にバンドルされたコマンド「ncc-tflite」を実行することでMDLA向けのDLA形式のAIモデルを生成します。最後に、生成されたDLA形式のAIモデルを、VAB-5000向けのDebian環境に含まれているVIAの開発したAIモデルをハードウェアアクセラレータ上で実行するためのランタイム「Neuron Runtime Helper」で実行することで、PythonコードからハードウェアアクセラレータであるMDLAを制御し、高速に推論を行うアプリケーションを実現することができます。
推論速度
このアプリケーションもAMOS-9100で利用したアプローチ同様に、入力画像から潜在変数を生成する処理は機械的な計算によってのみ行われ、潜在変数から分類結果を得る分類器による処理も機械的に行われるため、実行時間のばらつきはほとんど発生しません。結果、今回実装したアプリケーションは222fps前後で正誤判定をすることができました。潜在変数を活用する本アプローチでは、処理が重いデコーダを実行せず、異常検知に軽量な分類器のみを実行するため、AMOS-9100での再構成誤差を活用した異常検知に比べて、高速な動作を実現することができます。なお、AMOS-9100上で潜在変数を活用するアプローチのアプリケーションを実行した場合、302fps前後で異常検知を実行することが可能です。

VAB-5000_exec_ls_image
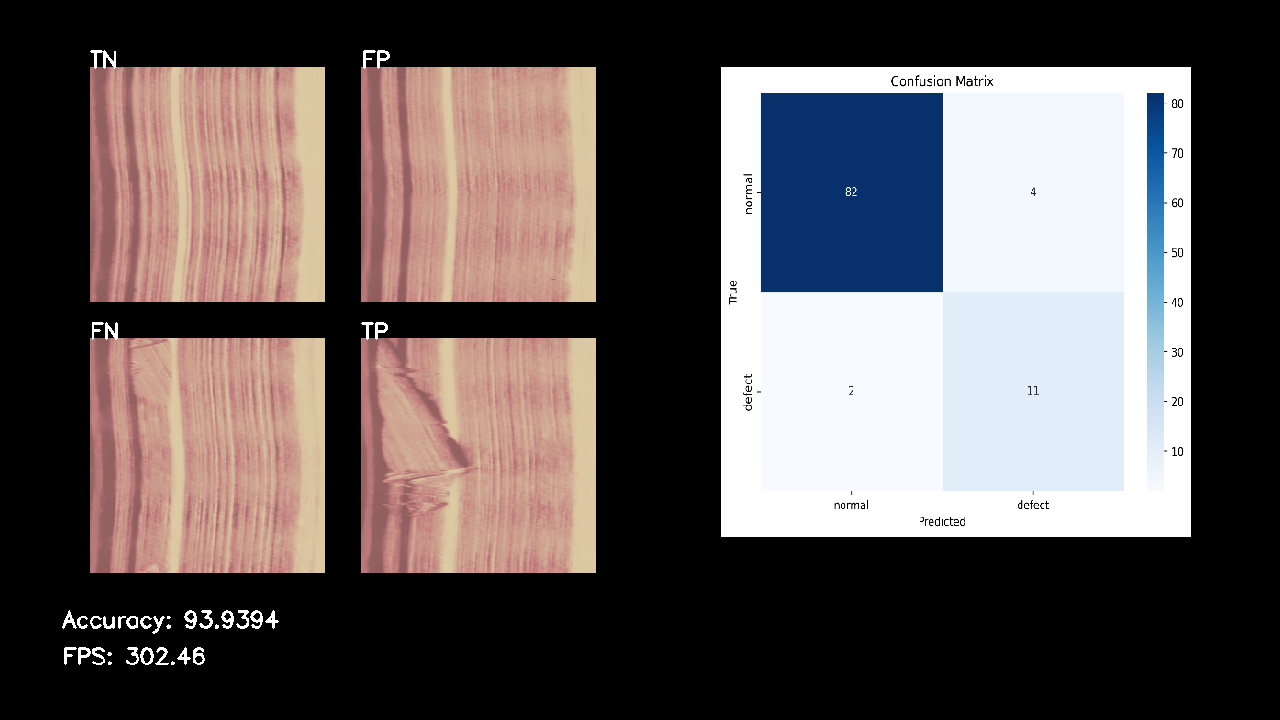
AMOS-9100_exec_ls_image
推論精度
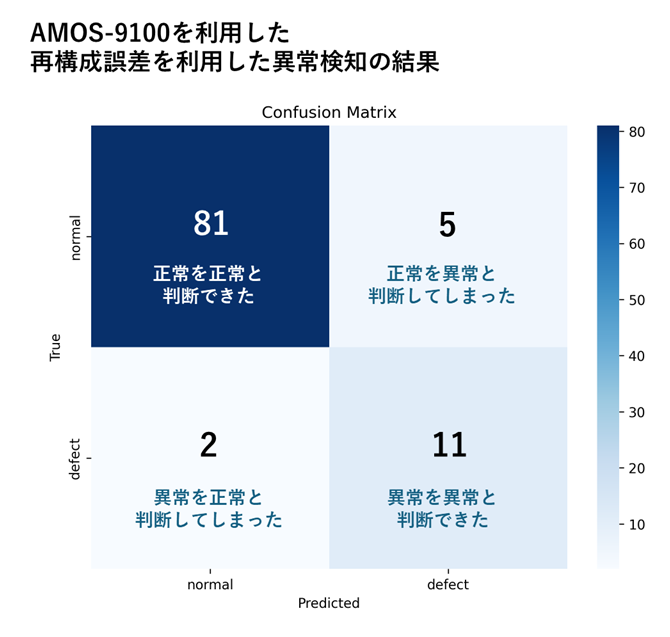
本アプリケーションを、BTAD Product2のうち、学習に利用しなかったテスト用データを用いて異常検知の精度を評価したところ、以下のような結果となりました。VAB-5000を活用した分類器によるアプローチでは、AMOS-9100を活用した再構成誤差に着目するアプローチに比べると、Precisionが高く、Recallが低い傾向となりました。
Accuracy = 92.9%
Precision = 71.4%
Recall = 76.9%
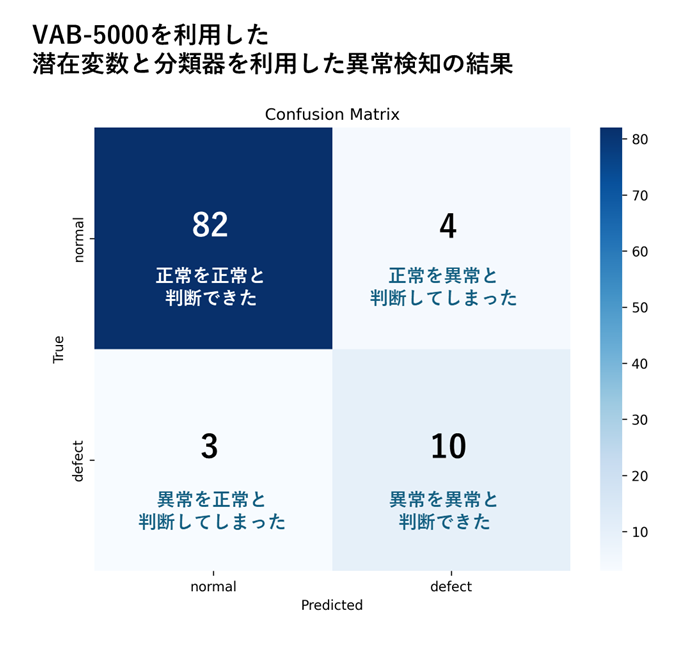
VAB-5000_confusion_matrix
分類器によるアプローチにおける課題
VAB-5000環境で採用したのは、オートエンコーダの入出力の再構成誤差を利用せず、潜在変数に対して分類器を適用するアプローチです。本アプローチは高速に動作することができる反面、分類器の学習は教師あり学習となるため、正常データだけでなく、相当量の異常データも必要になるという課題があります。本記事の例でも、BTADデータセットは、正常データに比べて異常データの数が少ないため、分類器の異常値に対する学習が十分にできず、再構成誤差を活用するアプローチと比べると、異常を検知する精度であるRecallが低くなる結果となってしまいました。精度の問題を解消するには、十分な量の正常データと異常データを用意した上で、エンコーダと分類器が異常データに対して高い感度を示すように調整を行う必要があります。一方で、本アプローチは高速に異常判定を行うことができるため、生産ラインにおける一次スクリーニングや、異常候補を高速に抽出して後段の検査工程へ引き渡す用途に適していると考えられます。
利用するシーンやハードウェアリソースを念頭に異常検知アプリケーションを設計する
本記事では、オートエンコーダにより異常を検知する方法のうち、二つのアプローチ、再構成誤差を活用した異常検知の方法と、潜在変数に対して分類器を適用する異常検知の方法を紹介しました。これらは、どちらの方式が優れているというものではなく、利用するシーンや精度、採用するハードウェアリソースに応じて、適切な方式を選ぶべきものです。以下に選定する際の基準をまとめます。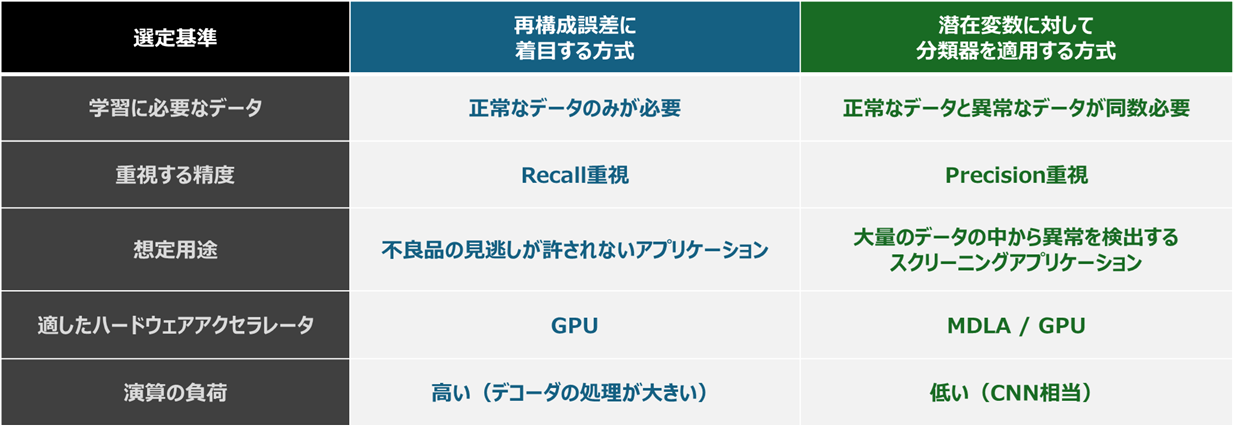
method-table
VIA VAB-5000やAMOS-9100を活用して産業分野に応用できる異常検知アプリケーションを実現しよう
本記事を通じて、VIAの組み込みAI向けプラットフォームであるAMOS-9100やVAB-5000を活用することで、画像データを用いた異常検知アプリケーションを効率的に構築できることをご理解いただけたかと思います。画像に基づく異常検知は、製造ラインでの製品外観検査(傷、欠け、異物混入などの検出)や、監視カメラ映像から不審な行動や禁止エリアへの侵入を検知するといったセキュリティアプリケーションなどに活用することができ、非常に有用です。AMOS-9100やVAB-5000は、コンパクトでありながら高性能なAI処理能力を備えており、エッジ環境でのリアルタイム処理に最適なプラットフォームです。是非、これらのプラットフォームをお客様の製品開発にお役立てください。