
Pose detection is a computer vision technique that can track and accurately predict the stance and position of a person’s body. Google’s ML Kit Pose Detection API enables you to do this in real time or from a static image, with a set of skeletal points. These points, known as landmarks, correspond to numerous body parts, such as (among many others) the head, the hands or the legs, and the relative positions can be used to distinguish between different poses.
While it may seem like a more trivial application of machine learning at first glance, there are many uses and implementations that prove otherwise. One of the most well-known examples would be for video games, with Microsoft’s Xbox 360 Kinect proving immensely popular from its initial release, selling millions of units. Another use would be for helping people exercise, by detecting errors and irregularities with their posture or positioning during a stretch or workout. For more information on this specific API, check out the overview on Google’s ML Kit website here.
Pose Detection on the VIA VAB-950
Pose detection has been implemented on the VIA VAB-950 using the ML Kit Vision Quickstart app allowing it to track the pose of a full body, including facial landmarks. In order for it to start, the user’s face must be within the view of the camera, and works best when the full body is present, but is able to perform partial detection if necessary. Check out the GitHub here in order to download it for yourself, or read our tutorial on installing Google’s ML Kit here. This is alongside the CameraX API, and the physical camera used is the MIPI CSI-2 Camera.
There are three main classes being used for this API which are fundamentally important to how it works. The first is “CameraXLivePreviewActivity”, which is where the CameraX use cases are set up. For the sake of not repeating myself too many times with these blogs, you can read about this in more depth in our face detection blog here, but essentially this class acts as the bridge between the live feed coming from the MIPI CSI-2 Camera, and the main logic of the program. This is done using two use cases, within the methods of “bindAnalysisUseCase” and “bindPreviewUseCase”, and where a “VisionImageProcessor” is declared, as “imageProcessor”. Then, in “bindAnalysisUseCase”, the pose detection case is slightly more complicated than the previous tutorials, although not too much:
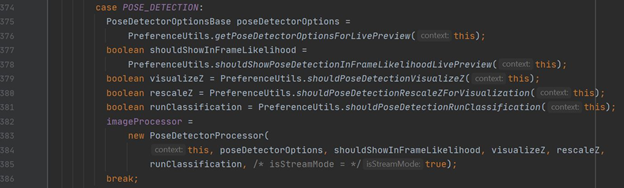
Within the above section of code, a “PoseDetectorOptionsBase” base class is declared, and from this several boolean variables are declared. These are to be used as fields for the “PoseDetectorProcessor” object declaration; the class of this object, “PoseDetectorProcessor” arguably being the most important class we will be looking at today. The “imageProcessor” is set to a new “PoseDetectorProcessor” object, using the aforementioned fields above.
“PoseDetectorProcessor” is where the image preview is taken as an input and fed into a “poseClassifierProcessor”. As remarked before, this is arguably the most important class, but it is also the simplest.
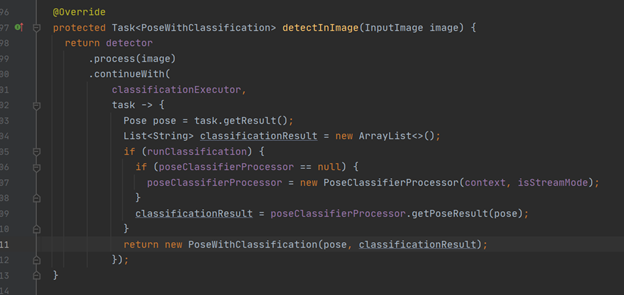
Most of the machine learning happens “under the hood”, and there are many calls to objects and methods from there. While the code isn’t available, Google has provided an insightful blog into what is happening here, such as machine learning pipelines or model tracking, as well as further potential applications. Check it out here!
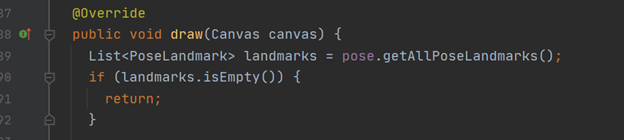
The final significant class is “PoseGraphic”. As the name suggests, this is where the methods for drawing the skeleton and visually showing the landmarks as points are. As with most of the code for the other API’s, the main method here is the “draw” method, which takes a “Canvas” object as input. A list is created of all the landmarks, which are then all drawn onto the canvas:
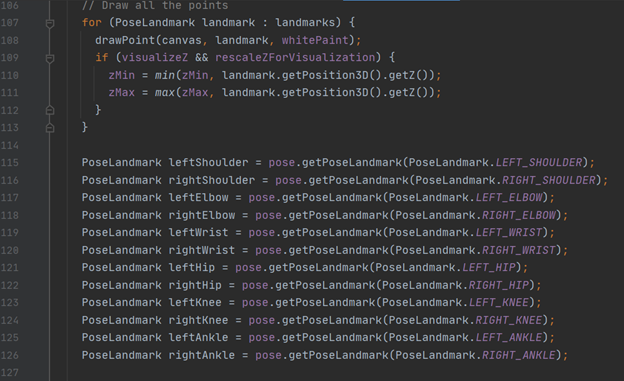
Lines connecting the landmarks together are then drawn, separated by the left and right sides of the body:
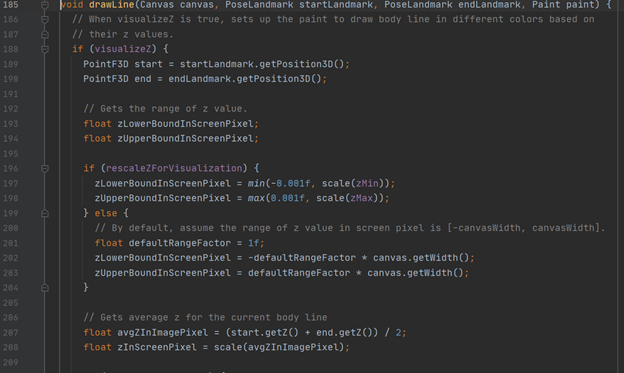
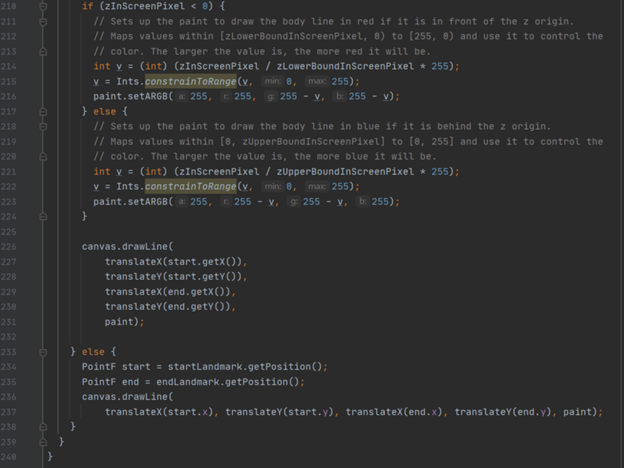
The “drawLine” method is important, as it visually shows the position of certain body parts by changing the colours based on their “Z” values, also known as “Z” coordinates. (as well as drawing the line lines of course). These values are experimental, but are calculated for every landmark. Their purpose is to give an estimate as to whether a landmark is on front or behind the subject’s hips, relative to the camera. The centre of the Z axis is therefore at the hips, with negative Z values indicating the landmark is towards the camera, and positive being away from the camera. Z values are measured in “image pixels”, but it’s worth noting that these do not give a true 3D value.
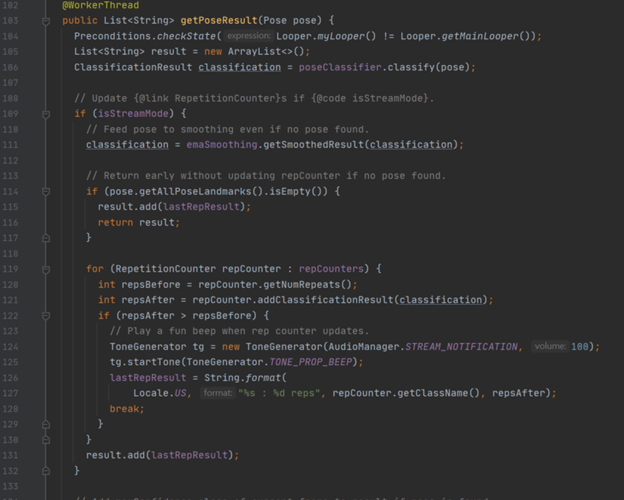
Finally, there is a collection of other classes which are unique to this API. These are for classifying poses, which is useful if you want to make something like an exercise app and count the amount of reps someone is doing or work out their stance. The main one of these to look at is the “PoseClassifierProcessor” class, which accepts a stream of the “Pose” class. Here, the predominant method is “getPoseResult”, which when given a new “Pose” as input, returns a list of formatted “String” types, which are the classification results. There are two results returned, the rep count and the confidence (0.0-1.0).

That’s about everything in terms of code. Here is how it looks when running:
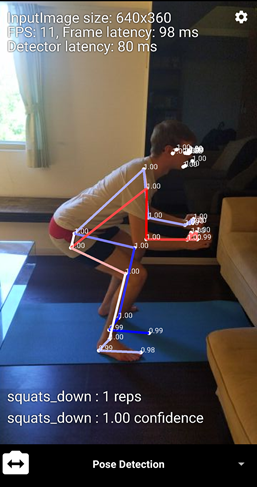


Notice the labels for push-ups and squats are at the bottom, as the classifier has been turned on (and also please note this is not a tutorial on how to have correct posture for push-ups!).
Visit our website’s blog section to find all the latest news and tutorials on the VIA VAB-950!